This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
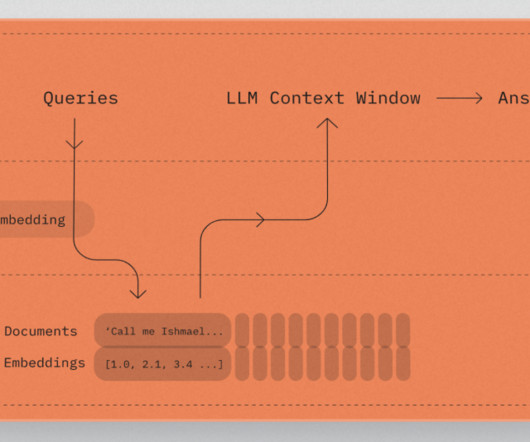
Amazon Bedrock Knowledge Bases has a metadata filtering capability that allows you to refine search results based on specific attributes of the documents, improving retrieval accuracy and the relevance of responses. These metadata filters can be used in combination with the typical semantic (or hybrid) similarity search.
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
If you're looking to implement Automatic Speech Recognition (ASR) in Python, you may have noticed that there is a wide array of available options. Broadly, Python speech recognition and Speech-to-Text solutions can be categorized into two main types: open-source libraries and cloud-based services. What is Speech Recognition?
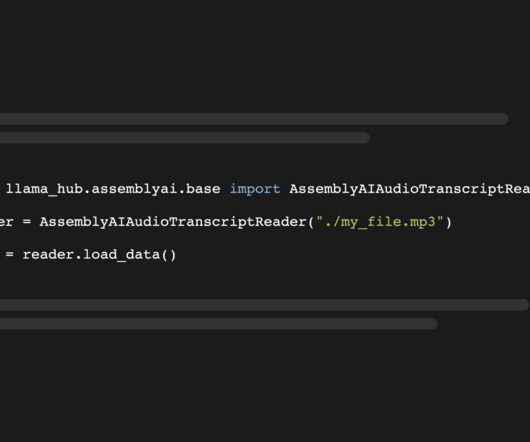
venv/bin/activate # Windows: python -m venv venv.venvScriptsactivate.bat Install LlamaIndex, Llama Hub, and the AssemblyAI Python package : pip install llama-index llama-hub assemblyai Set your AssemblyAI API key as an environment variable named ASSEMBLYAI_API_KEY. You can read more about the integration in the official Llama Hub docs.
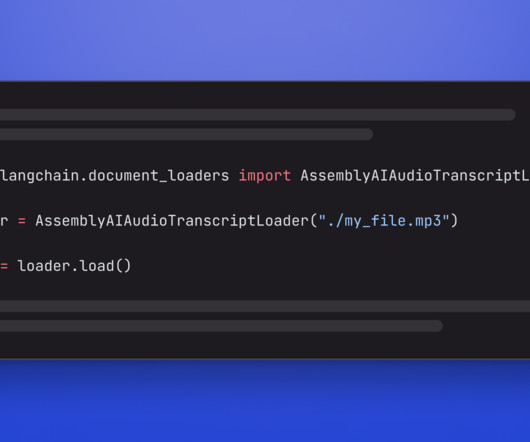
venv/bin/activate # Windows: python -m venv venv.venvScriptsactivate.bat Install LangChain and the AssemblyAI Python package : pip install langchain pip install assemblyai Set your AssemblyAI API key as an environment variable named ASSEMBLYAI_API_KEY. page_content) # Runner's knee. Runner's knee is a condition.
However, information about one dataset can be in another dataset, called metadata. Without using metadata, your retrieval process can cause the retrieval of unrelated results, thereby decreasing FM accuracy and increasing cost in the FM prompt token. This change allows you to use metadata fields during the retrieval process.
With metadata filtering now available in Knowledge Bases for Amazon Bedrock, you can define and use metadata fields to filter the source data used for retrieving relevant context during RAG. Metadata filtering gives you more control over the RAG process for better results tailored to your specific use case needs.
Database metadata can be expressed in various formats, including schema.org and DCAT. ML data has unique requirements, like combining and extracting data from structured and unstructured sources, having metadata allowing for responsible data use, or describing ML usage characteristics like training, test, and validation sets.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services. However, some components may incur additional usage-based costs.
When using the FAISS adapter, translation units are stored into a local FAISS index along with the metadata. The following sample XML illustrates the prompts template structure: EN FR Prerequisites The project code uses the Python version of the AWS Cloud Development Kit (AWS CDK). The request is sent to the prompt generator.
Since SimTalk is unfamiliar to LLMs due to its proprietary nature and limited training data, the out-of-the-box code generation quality is quite poor compared to more popular programming languages like Python, which have extensive publicly available datasets and broader community support.
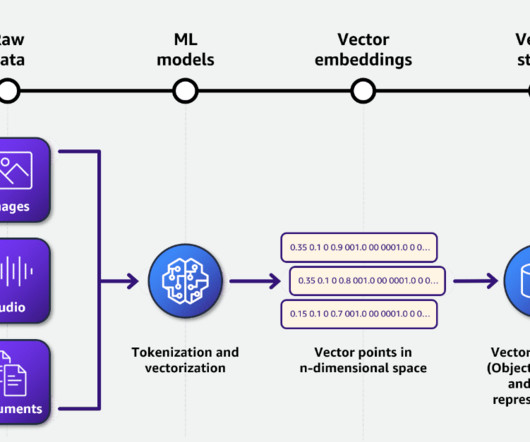
On the other hand, a Node is a snippet or “chunk” from a Document, enriched with metadata and relationships to other nodes, ensuring a robust foundation for precise data retrieval later on. Behind the scenes, it dissects raw documents into intermediate representations, computes vector embeddings, and deduces metadata.
Discover how metadata, the hidden gem of your knowledge base, can be transformed into a powerful tool for enriching your RAG pipeline and… Continue reading on MLearning.ai »
Gradio is an open-source Python library that enables developers to create user-friendly and interactive web applications effortlessly. curl ) and using the Python client ( ollama package). Example Python Request Heres how you can use the Python client to interact with the Llama 3.2 and the Ollama API, just keep reading.
complexities and embrace efficient Python packaging with build frontends. Embracing its simplicity, portability, and future-proofing benefits, making them the key to success in modern Python packaging. served as the entry point to the world of Python packaging. ', py_modules=['my_module'], # Other metadata.)
Streamlit is an open source framework for data scientists to efficiently create interactive web-based data applications in pure Python. Install Python 3.7 structured: | Process the pdf invoice and list all metadata and values in json format for the variables with descriptions in tags. or later on your local machine.
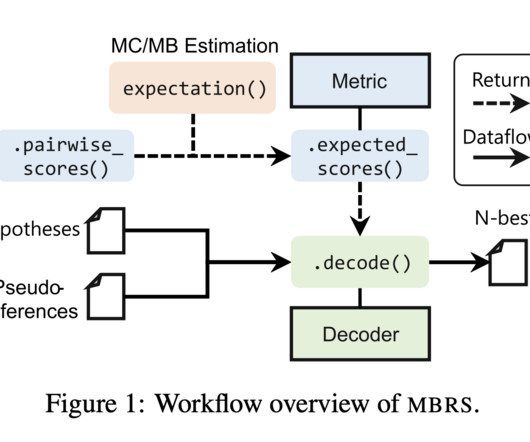
The MBRS library is implemented primarily in Python and PyTorch and offers several key features. Additionally, MBRS provides metadata analysis capabilities, allowing users to analyze the origins of output texts and visualize the decision-making process of MBR decoding.
How to save a trained model in Python? Saving trained model with pickle The pickle module can be used to serialize and deserialize the Python objects. For saving the ML models used as a pickle file, you need to use the Pickle module that already comes with the default Python installation. Now let’s see how we can save our model.
Extract and generate data : Find out how to extract tags and descriptions from your audio to enhance metadata and searchability with LeMUR. Fresh From Our Blog How to identify languages in audio data using Python : Learn how to use Python to automatically identify languages in audio files.
Researchers at the Allen Institute for AI introduced olmOCR , an open-source Python toolkit designed to efficiently convert PDFs into structured plain text while preserving logical reading order. Image Source The core innovation behind olmOCR is document anchoring, a technique that combines textual metadata with image-based analysis.
Setting up the virtual environment In a terminal, create a directory for this project and navigate into it: mkdir ragaudio && cd ragaudio Now, enter the following command to create a virtual environment called venv python -m venv venv Next, activate the environment. Running the application To run the app, execute python main.py
The embeddings, along with metadata about the source documents, are indexed for quick retrieval. Python 3.9 The embeddings are stored in the Amazon OpenSearch Service owner manuals index. OpenSearch Service is used as the vector store for efficient similarity searching. or later Node.js
Chroma can be used to create word embeddings using Python or JavaScript programming. Each referenced string can have extra metadata that describes the original document. Researchers fabricated some metadata to use in the tutorial. Metadata (or IDs) can also be queried in the Chroma database.
In Python, a package organizes related modules (Python files) into a single hierarchical structure. A Python package is simply a directory that contains one or more Python modules, along with a special __init__.py py file that tells Python that this directory should be treated as a package.
Extract and generate data : Find out how to extract tags and descriptions from your audio to enhance metadata and searchability with LeMUR. Read more>> Content moderation on audio files with Python : Use AssemblyAI's API to automatically detect sensitive topics in speech data for content moderation.
We add the following to the end of the prompt: provide the response in json format with the key as “class” and the value as the class of the document We get the following response: { "class": "ID" } You can now read the JSON response using a library of your choice, such as the Python JSON library. The following image is of a gearbox.
In addition, 3FS incorporates stateless metadata services that are supported by a transactional key-value store, such as FoundationDB. By decoupling metadata management from the storage layer, the system not only becomes more scalable but also reduces potential bottlenecks related to metadata operations.
In this post, we show you how to convert Python code that fine-tunes a generative AI model in Amazon Bedrock from local files to a reusable workflow using Amazon SageMaker Pipelines decorators. It automatically keeps track of model artifacts, hyperparameters, and metadata, helping you to reproduce and audit model versions.
Step 1: Environment setup You first need to install the required Python packages for fine tuning. The following is the bash script for the Python environment setup. The following is the Python code for the get_model.py First, create the Python file, touch consolidation.py with the following code and run it with sbatch.
Extract and generate data : Find out how to extract tags and descriptions from your audio to enhance metadata and searchability with LeMUR. Python + Gradio Tutorial) : Can you learn a new language in seconds? Summarize audio data : Discover how to quickly summarize your audio data with key takeaways using LeMUR.
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. Streamlit This open source Python library makes it straightforward to create and share beautiful, custom web apps for ML and data science. The following diagram illustrates the RAG framework. Error app.py
makes it easy for RAG developers to track evaluation metrics and metadata, enabling them to analyze and compare different system configurations. Source Step 1: Setting up Well begin by installing the necessary dependencies (I used Python 3.11.4 Overview of the categories of building blocks provided by LangChain. langchain-openai== 0.0.6
Veritone’s current media search and retrieval system relies on keyword matching of metadata generated from ML services, including information related to faces, sentiment, and objects. We use the Amazon Titan Text and Multimodal Embeddings models to embed the metadata and the video frames and index them in OpenSearch Service.
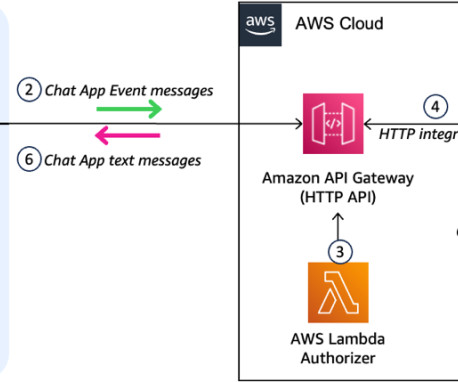
This request contains the user’s message and relevant metadata. Install the Python package dependencies that are needed to build and deploy the project. This project is set up like a standard Python project. The custom Google Chat app, configured for HTTP integration, sends an HTTP request to an API Gateway endpoint.
metadata = {} index = VectorStoreIndex.from_documents(docs) query_engine = index.as_query_engine() response = query_engine.query("What is a runner's knee?") Akshay Pachaar gave a shoutout to AssemblyAI with his concise tutorial on audio transcription in python. Build vector store index and query engine docs[0].metadata
Return item metadata in inference responses – The new recipes enable item metadata by default without extra charge, allowing you to return metadata such as genres, descriptions, and availability in inference responses. If you use Amazon Personalize with generative AI, you can also feed the metadata into prompts.
Astral, a company renowned for its high-performance developer tools in the Python ecosystem, has recently released uv: Unified Python packaging , a comprehensive tool designed to streamline Python package management. Developers can now use uv to generate and install cross-platform lockfiles based on standards-compliant metadata.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Third, despite the larger adoption of centralized analytics solutions like data lakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources.
Create a SageMaker Model Monitor schedule Next, you use the Amazon SageMaker Python SDK to create a model monitoring schedule. Publish the BYOC image to Amazon ECR Create a script named model_quality_monitoring.py docker/Dockerfile --repository sm-mm-mqm-byoc:1.0 amazonaws.com/sm-mm-mqm-byoc:1.0", instance_count=1, instance_type='ml.m5.xlarge',
To demonstrate this, we will use a Python client to interact with the API. One of the most powerful features of Spotlight is its ability to generate structured metadata from images. Using the OpenAIAPI For developers who prefer a programmatic approach, Spotlight can be accessed via the OpenAI API.
We also store the video summaries, sentiments, insights, and other workflow metadata in DynamoDB, a NoSQL database service that allows you to quickly keep track of the workflow status and retrieve relevant information from the original video.
For instance, analyzing large tables might require prompting the LLM to generate Python or SQL and running it, rather than passing the tabular data to the LLM. In your code, the final variable should be named "result". """ We can then parse the code out from the tags in the LLM response and run it using exec in Python.
For example, we export pre-chunked asset metadata from our asset library to Amazon S3, letting Amazon Bedrock handle embeddings, vector storage, and search. This could be, for example, Keep all your replies as short as possible or If I ask for code its always Python.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content