
Building AI chatbots using Amazon Lex and Amazon Kendra for filtering query results based on user context
AWS Machine Learning Blog
FEBRUARY 14, 2023
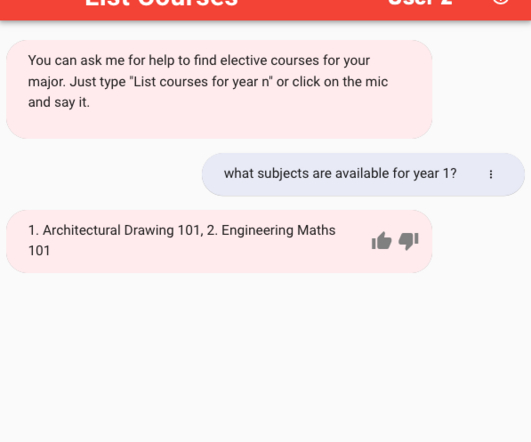
Solution overview To solve this problem, you can identify one or more unique metadata information that is associated with the documents being indexed and searched. In Amazon Kendra, you provide document metadata attributes using custom attributes. When the authentication is performed using Amazon Cognito, the “sessionState”.”sessionAttributes”.”idtokenjwt”









Let's personalize your content