This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Imagine this: you have built an AI app with an incredible idea, but it struggles to deliver because running largelanguagemodels (LLMs) feels like trying to host a concert with a cassette player. This is where inference APIs for open LLMs come in. The potential is there, but the performance?
For AI and largelanguagemodel (LLM) engineers , design patterns help build robust, scalable, and maintainable systems that handle complex workflows efficiently. This article dives into design patterns in Python, focusing on their relevance in AI and LLM -based systems. model hyperparameters).
Utilizing LargeLanguageModels (LLMs) through different prompting strategies has become popular in recent years. Differentiating prompts in multi-turn interactions, which involve several exchanges between the user and model, is a crucial problem that remains mostly unresolved.
Due to their exceptional content creation capabilities, Generative LargeLanguageModels are now at the forefront of the AI revolution, with ongoing efforts to enhance their generative abilities. However, despite rapid advancements, these models require substantial computational power and resources. Let's begin.
Generative LargeLanguageModels (LLMs) are well known for their remarkable performance in a variety of tasks, including complex Natural Language Processing (NLP), creative writing, question answering, and code generation. times faster than the current llama.cpp system while retaining model fidelity.
LargeLanguageModels (LLMs) have demonstrated impressive capabilities in handling knowledge-intensive tasks through their parametric knowledge stored within model parameters. Representation engineering emerged as a higher-level framework for understanding LLM behavior at scale. Check out the Paper.
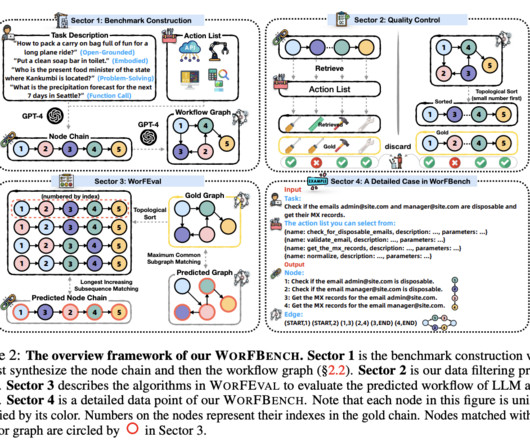
LargeLanguageModels (LLMs) have shown remarkable potential in solving complex real-world problems, from function calls to embodied planning and code generation. Researchers from Zhejiang University and Alibaba Group have proposed WORFBENCH, a benchmark for evaluating workflow generation capabilities in LLM agents.
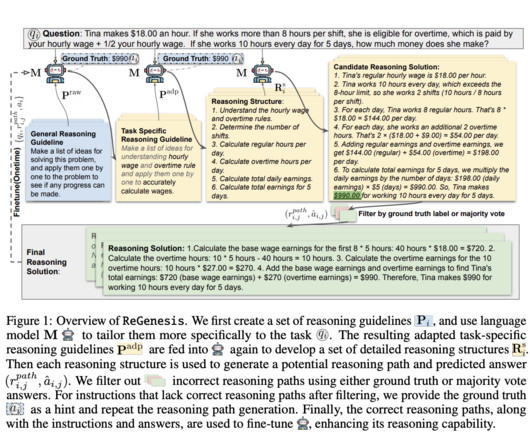
Largelanguagemodels (LLMs) have revolutionized how machines process and generate human language, but their ability to reason effectively across diverse tasks remains a significant challenge. Finally, the LLM uses these reasoning structures to create detailed reasoning paths.
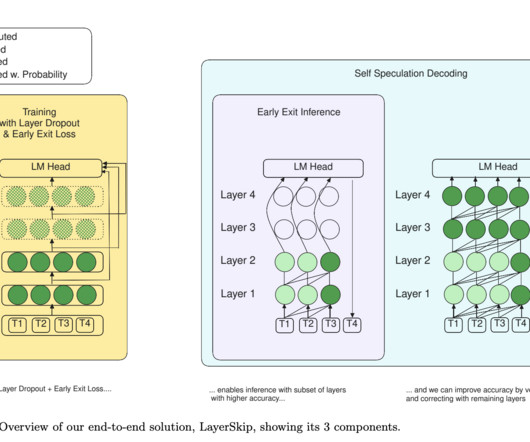
Accelerating inference in largelanguagemodels (LLMs) is challenging due to their high computational and memory requirements, leading to significant financial and energy costs. Check out the Paper , Model Series on Hugging Face , and GitHub. Don’t Forget to join our 50k+ ML SubReddit.
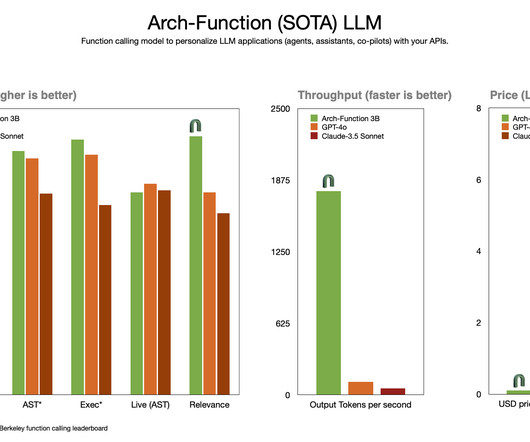
One of the biggest hurdles organizations face is implementing LargeLanguageModels (LLMs) to handle intricate workflows effectively. Enterprises struggle with the cumbersome nature of configuring LLMs for seamless collaboration across data sources, making it challenging to adopt them for operational efficiency.
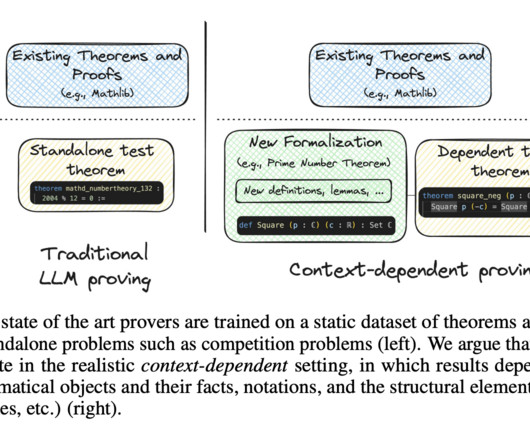
Formal theorem proving has emerged as a critical benchmark for assessing the reasoning capabilities of largelanguagemodels (LLMs), with significant implications for mathematical automation. Don’t Forget to join our 55k+ ML SubReddit.
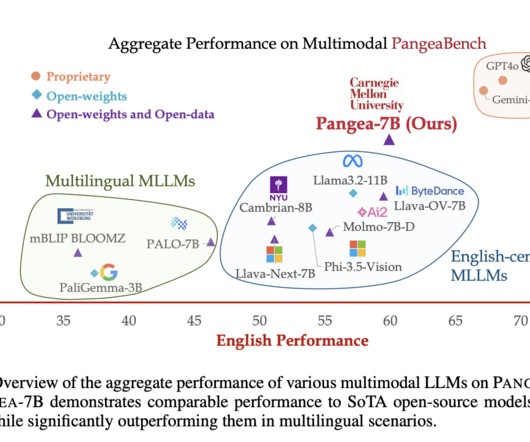
Despite recent advances in multimodal largelanguagemodels (MLLMs), the development of these models has largely centered around English and Western-centric datasets. PANGEA is trained on a newly curated dataset, PANGEAINS, which contains 6 million instruction samples across 39 languages.
LargeLanguageModels (LLMs) have demonstrated remarkable proficiency in In-Context Learning (ICL), which is a technique that teaches them to complete tasks using just a few examples included in the input prompt and no further training. The team has shared their primary contributions as follows. Llama-3, and Qwen.
Recent advancements in LargeLanguageModels (LLMs) have reshaped the Artificial intelligence (AI)landscape, paving the way for the creation of Multimodal LargeLanguageModels (MLLMs). It also provides multilingual support for languages such as English and Chinese.
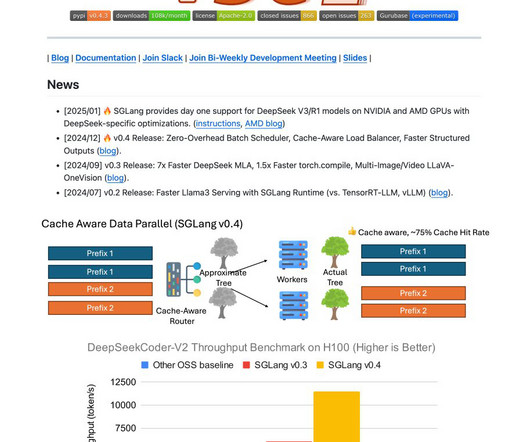
SGLang is an open-source inferenceengine designed by the SGLang team to address these challenges. It optimizes CPU and GPU resources during inference, achieving significantly higher throughput than many competitive solutions. RadixAttention is central to SGLang, which reuses shared prompt prefixes across multiple requests.
The problem with efficiently linearizing largelanguagemodels (LLMs) is multifaceted. The quadratic attention mechanism in traditional Transformer-based LLMs, while powerful, is computationally expensive and memory-intensive. Don’t Forget to join our 50k+ ML SubReddit.
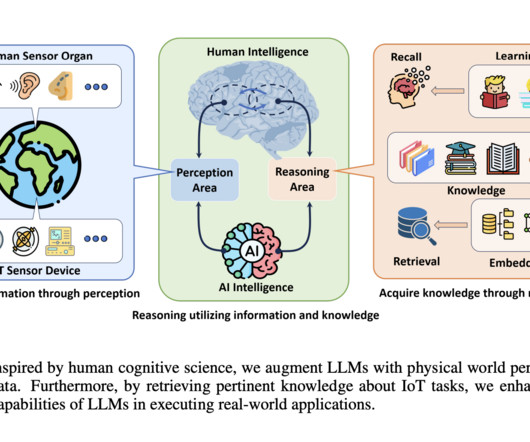
This requirement has prompted researchers to find effective ways to integrate real-time data and contextual understanding into LargeLanguageModels (LLMs), which have difficulty interpreting real-world tasks. The IoT-LLM framework consists of these three steps: 1. Don’t Forget to join our 50k+ ML SubReddit.
There is a need for flexible and efficient adaptation of largelanguagemodels (LLMs) to various tasks. Existing approaches, such as mixture-of-experts (MoE) and model arithmetic, struggle with requiring substantial tuning data, inflexible model composition, or strong assumptions about how models should be used.
Largelanguagemodels (LLMs) have become crucial in natural language processing, particularly for solving complex reasoning tasks. These models are designed to handle mathematical problem-solving, decision-making, and multi-step logical deductions. Check out the Paper.
Largelanguagemodels (LLMs) have revolutionized various fields by enabling more effective data processing, complex problem-solving, and natural language understanding. Specifically, while LLMs are becoming capable of handling longer input sequences, the increase in retrieved information can overwhelm the system.
The ever-increasing size of LargeLanguageModels (LLMs) presents a significant challenge for practical deployment. Despite their transformative impact on natural language processing, these models are often hindered by high memory transfer requirements, which pose a bottleneck during autoregressive generation.
NVIDIA Inference Microservices (NIM) and LangChain are two cutting-edge technologies that meet these needs, offering a comprehensive solution for deploying AI in real-world environments. Understanding NVIDIA NIM NVIDIA NIM, or NVIDIA Inference Microservices, is simplifying the process of deploying AI models.
The challenge lies in generating effective agentic workflows for LargeLanguageModels (LLMs). Despite their remarkable capabilities across diverse tasks, creating workflows that combine multiple LLMs into coherent sequences is labor-intensive, which limits scalability and adaptability to new tasks.
Accurate assessment of LargeLanguageModels is best done with complex tasks involving long input sequences. While examining the performance of capable LLMs on tasks involving long context lengths, researchers noticed a few underlying problems. Relative position introduces a bias in LLMs, thus affecting their performance.
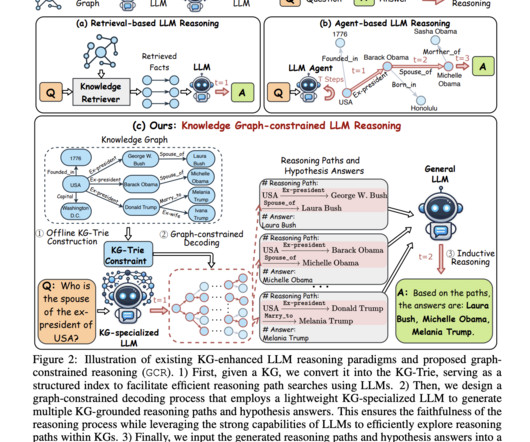
Largelanguagemodels (LLMs) have demonstrated significant reasoning capabilities, yet they face issues like hallucinations and the inability to conduct faithful reasoning. GCR introduces a trie-based index named KG-Trie to integrate KG structures directly into the LLM decoding process.
Google Research has introduced a novel framework called Chain-of-Agents (CoA) to address the challenges of long-context tasks in largelanguagemodels (LLMs). LLMs have demonstrated different capabilities in various tasks such as reasoning, knowledge retrieval, and generation.
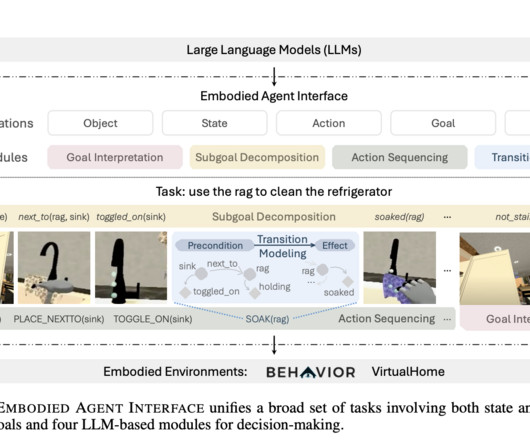
LargeLanguageModels (LLMs) need to be evaluated within the framework of embodied decision-making, i.e., the capacity to carry out activities in either digital or physical environments. In conclusion, the Embodied Agent Interface offers a thorough framework for evaluating LLM performance in tasks involving embodied AI.
There are rising worries about the potential negative impacts of largelanguagemodels (LLMs), such as data memorization, bias, and unsuitable language, despite LLMs’ widespread praise for their capacity to generate natural-sounding text. Regular Expression engine for LMs, or ReLM for short.
Teams from the companies worked closely together to accelerate the performance of Gemma — built from the same research and technology used to create Google DeepMind’s most capable model yet, Gemini — with NVIDIA TensorRT-LLM , an open-source library for optimizing largelanguagemodelinference, when running on NVIDIA GPUs.
Largelanguagemodels (LLMs) like GPT-4, Gemini, and Llama 3 have revolutionized natural language processing through extensive pre-training and supervised fine-tuning (SFT). However, these models come with high computational costs for training and inference. Check out the Paper.
Largelanguagemodels (LLMs) have gained widespread adoption due to their advanced text understanding and generation capabilities. By combining these features, AutoDAN-Turbo represents a significant advancement in the field of automated jailbreak attacks against largelanguagemodels.
Largelanguagemodels (LLMs) have advanced significantly in recent years. The need to make LLMs more accessible on smaller and resource-limited devices drives the development of more efficient frameworks for modelinference and deployment.
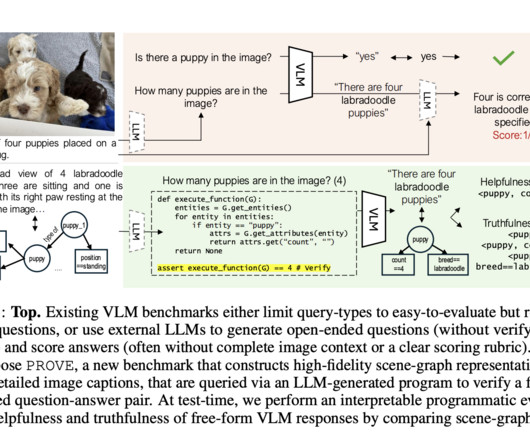
In PROVE, researchers use a high-fidelity scene graph representation constructed from hyper-detailed image captions and employ a largelanguagemodel (LLM) to generate diverse question-answer (QA) pairs along with executable programs to verify each QA pair. This approach allows the creation of a benchmark dataset of 10.5k
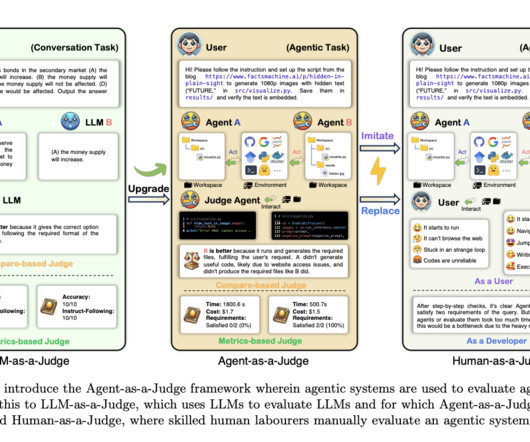
Current evaluation frameworks, such as LLM-as-a-Judge, which uses largelanguagemodels to judge outputs from other AI systems, must account for the entire task-solving process. These models often overlook intermediate stages, crucial for agentic systems because they mimic human-like problem-solving strategies.
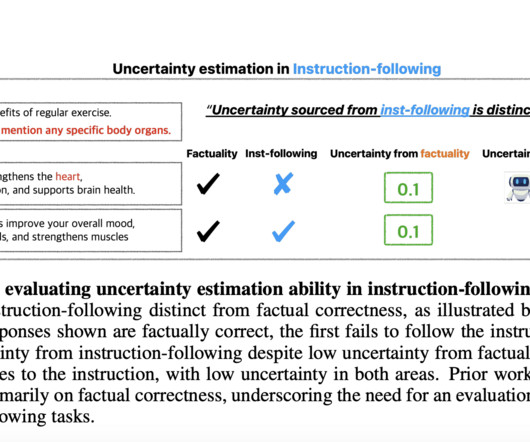
LargeLanguageModels (LLMs) have potential applications in education, healthcare, mental health support, and other domains. Sometimes, even sophisticated models misunderstand instructions or depart from them, which might reduce their effectiveness, particularly in delicate situations.
Largelanguagemodels (LLMs) are increasingly utilized for complex tasks requiring multiple generation calls, advanced prompting techniques, control flow, and structured inputs/outputs. SGLang, a newly introduced system, aims to address this by providing efficient execution of complex languagemodel programs.
Accelerating LLMInference with NVIDIA TensorRT While GPUs have been instrumental in training LLMs, efficient inference is equally crucial for deploying these models in production environments. Accelerating LLM Training with GPUs and CUDA. 122 ~/local 1 Verify the installation: ~/local/cuda-12.2/bin/nvcc
This is the kind of horsepower needed to handle AI-assisted digital content creation, AI super resolution in PC gaming, generating images from text or video, querying local largelanguagemodels (LLMs) and more. LLM performance is measured in the number of tokens generated by the model. Source: Jan.ai
Largelanguagemodels (LLMs) can understand and generate human-like text across various applications. However, despite their success, LLMs often need help in mathematical reasoning, especially when solving complex problems requiring logical, step-by-step thinking. Don’t Forget to join our 50k+ ML SubReddit.
The deployment of these super powerful models into production environments is NOT easy and time efficient. As we are halfway there to 2025, companies have to move beyond API calling pretrained LargeLanguageModels and go deep into thinking about deploying these full-scale models into production environment.
Traditionally, largelanguagemodels (LLMs) used for building TTS pipelines convert speech to text using automatic speech recognition (ASR), process it using an LLM, and then convert the output back to speech via TTS. If you like our work, you will love our newsletter. Don’t Forget to join our 50k+ ML SubReddit.
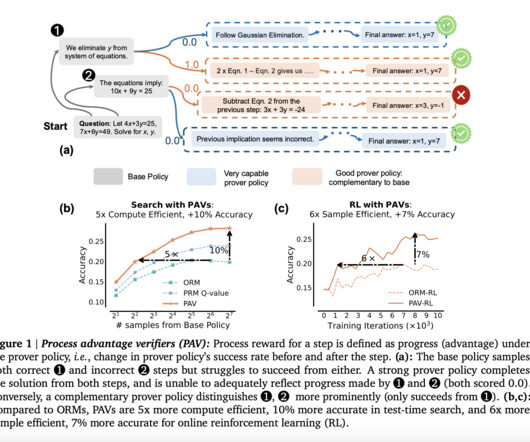
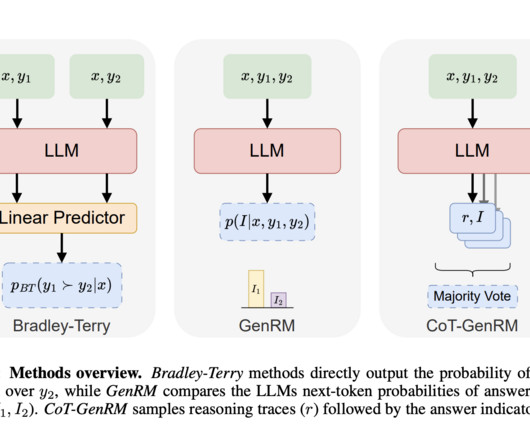
A recent approach, Reinforcement Learning from Human Feedback (RLHF), has brought remarkable improvements to largelanguagemodels (LLMs) by incorporating human preferences into the training process. GenRM leverages a large pre-trained LLM to generate reasoning chains that help decision-making.
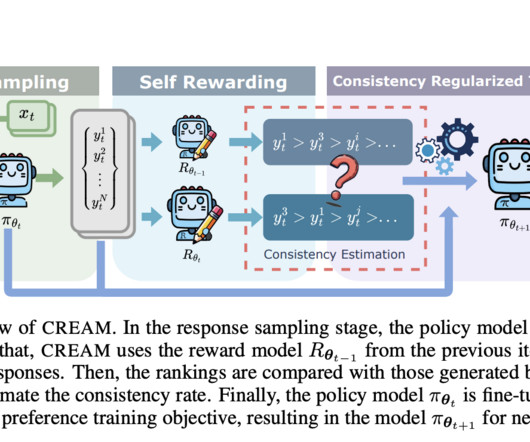
This is indeed a very serious challenge for the larger and more effective scaling of LLM modalities applied to real-world applications. These results further establish CREAM as a strong solution to the alignment problem by providing a scalable and effective method for optimizing largelanguagemodels.
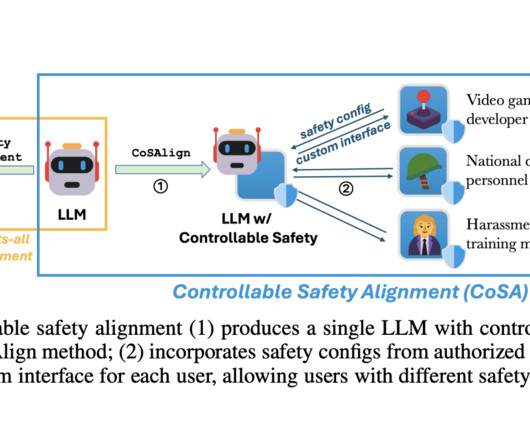
As largelanguagemodels (LLMs) become increasingly capable and better day by day, their safety has become a critical topic for research. To create a safe model, model providers usually pre-define a policy or a set of rules. The adapted strategy first produces an LLM that is easily controllable for safety.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content