
CMU Researchers Introduce ReLM: An AI System For Validating And Querying LLMs Using Standard Regular Expressions
Marktechpost
JUNE 8, 2023
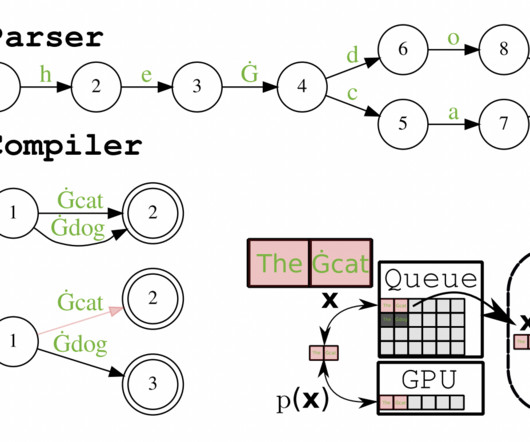
For the ever-growing challenge of LLM validation, ReLM provides a competitive and generalized starting point. ReLM is the first solution that allows practitioners to directly measure LLM behavior over collections too vast to enumerate by describing a query as the whole set of test patterns.












Let's personalize your content