This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
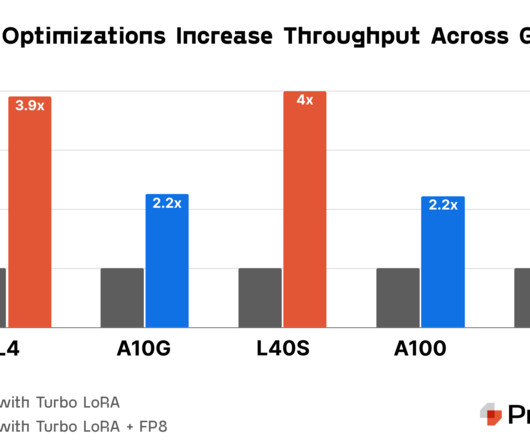
Predibase announces the Predibase InferenceEngine , their new infrastructure offering designed to be the best platform for serving fine-tuned small language models (SLMs). The Predibase InferenceEngine addresses these challenges head-on, offering a tailor-made solution for enterprise AI deployments.
Together AI , a prominent player in the AI Acceleration Cloud space, is also looking to integrate its proprietary Together InferenceEngine with NVIDIA Dynamo. This integration aims to enable seamless scaling of inference workloads across multiple GPU nodes.
DeepSeeking the Truth By now, the world knows all about DeepSeek, the Chinese AI company touting how it used inferenceengines and statistical reasoning to train large language models much more efficiently and with less cost than other firms have trained their models.
Groq groq Groq is renowned for its high-performance AI inference technology. Their standout product, the Language Processing Units (LPU) InferenceEngine , combines specialized hardware and optimized software to deliver exceptional compute speed, quality, and energy efficiency.
One, as I mentioned, is operating AI inferenceengines within Cloudflare close to consumers’ eyeballs. While machine learning training is typically conducted outside Cloudflare, the company excels in providing low-latency inferenceengines that are essential for real-time applications like image recognition.
Modular Inc., the creator of a programming language optimized for developing artificial intelligence software, has raised $100 million in fresh funding.General Catalyst led the investment, which w
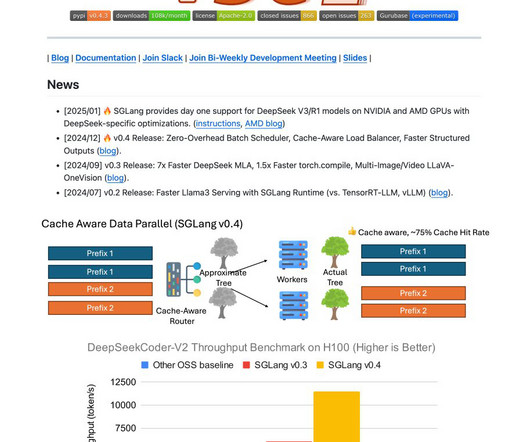
SGLang is an open-source inferenceengine designed by the SGLang team to address these challenges. It optimizes CPU and GPU resources during inference, achieving significantly higher throughput than many competitive solutions.
This ability is supported by advanced technical components like inferenceengines and knowledge graphs, which enhance its reasoning skills. Its architecture allows it to break down complex problems step-by-step, showing intermediate thought processes before arriving at a final response.
Additionally, Run Model Streamer integrates natively with popular inferenceengines, eliminating the need for time-consuming model format conversions. This versatility ensures that developers do not need to worry about compatibility issues, regardless of where their models are stored.
The Together InferenceEngine, capable of processing over 400 tokens per second on Meta Llama 3 8B, integrates the latest innovations from Together AI, including FlashAttention-3, faster GEMM and MHA kernels, and quality-preserving quantization, as well as speculative decoding techniques.
Ensuring consistent access to a single inferenceengine or database connection. When to Use Managing global configurations (e.g., model hyperparameters). Sharing resources across multiple threads or processes (e.g., GPU memory ).
Compatible with inferenceengines like vLLM and SGLang, allowing flexible deployment on various hardware setups. It outperforms traditional OCR tools in structured data recognition and large-scale processing and has the highest ELO score in human evaluations. Improves language model training by increasing accuracy by 1.3
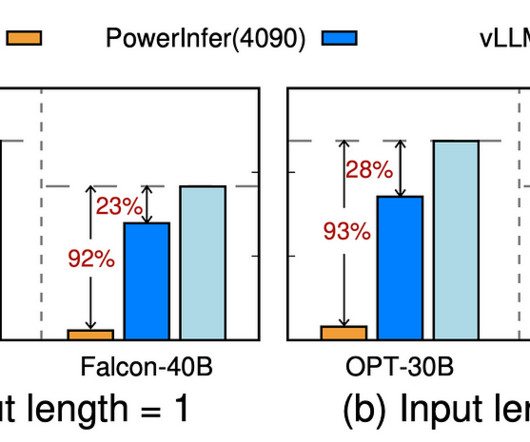
In this article, we will discuss PowerInfer, a high-speed LLM inferenceengine designed for standard computers powered by a single consumer-grade GPU. The PowerInfer framework seeks to utilize the high locality inherent in LLM inference, characterized by a power-law distribution in neuron activations.
NVIDIA Inference Microservices (NIM) and LangChain are two cutting-edge technologies that meet these needs, offering a comprehensive solution for deploying AI in real-world environments. Understanding NVIDIA NIM NVIDIA NIM, or NVIDIA Inference Microservices, is simplifying the process of deploying AI models.
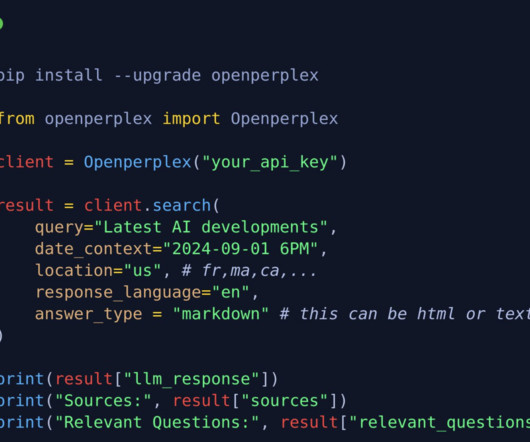
The integration with Google search through a specialized API enhances the breadth of information available, while a powerful inferenceengine ensures efficient processing. It also uses a reranking system to refine the results based on relevance. OpenPerPlex offers several features that highlight its capabilities.
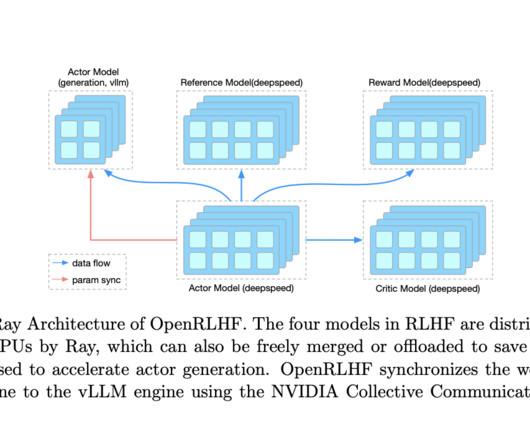
OpenRLHF leverages two key technologies: Ray, the Distributed Task Scheduler, and vLLM, the Distributed InferenceEngine. In response to these challenges, researchers propose a groundbreaking RLHF framework named OpenRLHF.
Transformer Lab allows you to: 💕 One-click Download Hundreds of Popular Models : DeepSeek, Llama3, Qwen, Phi4, Gemma, Mistral, Mixtral, Command-R, and dozens more ⬇ Download any LLM from Huggingface 🎶 Finetune / Train Across Different Hardware Finetune using MLX on Apple Silicon Finetune using Huggingface on GPU ⚖️ (..)
PowerInfer exploits such an insight to design a GPU-CPU hybrid inferenceengine. This distribution indicates that a small subset of neurons, termed hot neurons, are consistently activated across inputs, while the majority, cold neurons, vary based on specific inputs.
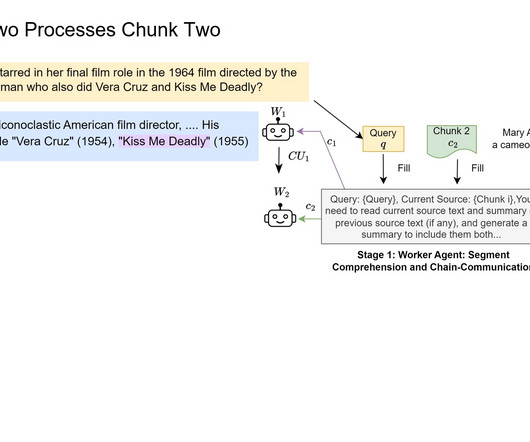
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Layer-of-Thoughts Prompting (LoT): A Unique Approach that Uses Large Language Model (LLM) based Retrieval with Constraint Hierarchies appeared first on MarkTechPost.
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post MEGA-Bench: A Comprehensive AI Benchmark that Scales Multimodal Evaluation to Over 500 Real-World Tasks at a Manageable Inference Cost appeared first on MarkTechPost.
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Meet Hawkish 8B: A New Financial Domain Model that can Pass CFA Level 1 and Outperform Meta Llama-3.1-8B-Instruct If you like our work, you will love our newsletter.
It employs Groq’s inferenceengine for high-speed processing, ensuring rapid search response times. By combining the strengths of multiple technologies, OpenPerPlex aims to provide a more reliable and efficient search experience. OpenPerPlex’s effectiveness is driven by its robust tech stack.
The team has shared that PowerInfer is a GPU-CPU hybrid inferenceengine that makes use of this understanding. This distribution shows that most cold neurons change based on certain inputs, whereas a tiny fraction of hot neurons consistently activate across different inputs.
The scientists developed an inferenceengine called Nunchaku that combines low-rank and low-bit computation kernels with memory access optimization to cut latency. SVDQuant works by smoothing and sending outliers from activations to weights. Then applying SVD decomposition over weights, split the weights into a low rank and residual.
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post AFlow: A Novel Artificial Intelligence Framework for Automated Workflow Optimization appeared first on MarkTechPost. If you like our work, you will love our newsletter.
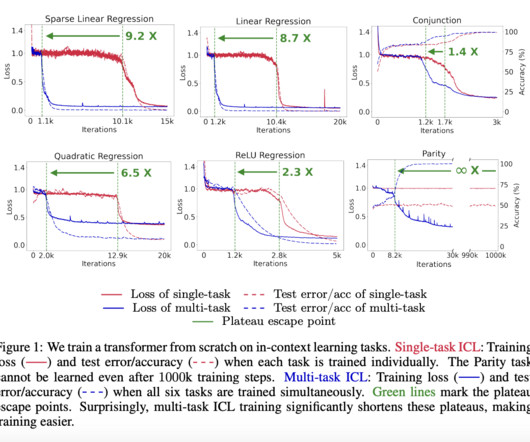
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post This Machine Learning Research Discusses How Task Diversity Shortens the In-Context Learning (ICL) Plateau appeared first on MarkTechPost. If you like our work, you will love our newsletter.
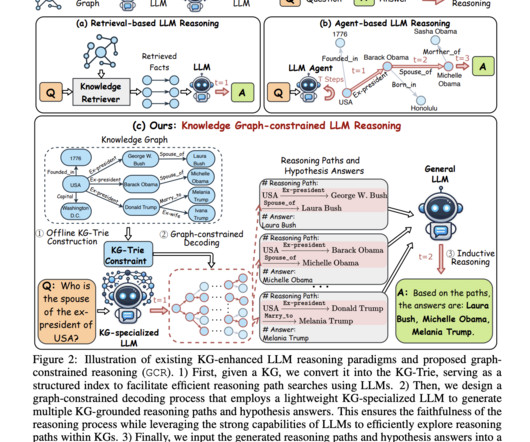
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Graph-Constrained Reasoning (GCR): A Novel AI Framework that Bridges Structured Knowledge in Knowledge Graphs with Unstructured Reasoning in LLMs appeared first on MarkTechPost.
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Google AI Research Examines Random Circuit Sampling (RCS) for Evaluating Quantum Computer Performance in the Presence of Noise appeared first on MarkTechPost.
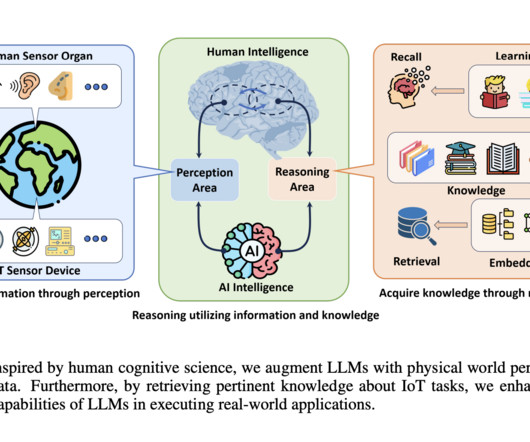
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post IoT-LLM: An AI Framework that Integrates IoT Sensor Data with LLMs to Enhance their Perception and Reasoning Abilities in the Physical World appeared first on MarkTechPost.
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Differentiable Rendering of Robots (Dr. If you like our work, you will love our newsletter. Don’t Forget to join our 50k+ ML SubReddit.
These systems rely on a domain knowledge base and an inferenceengine to solve specialized medical problems. Intelligent Medical Applications: AI in Healthcare: AI has enabled the development of expert systems, like MYCIN and ONCOCIN, that simulate human expertise to diagnose and treat diseases.
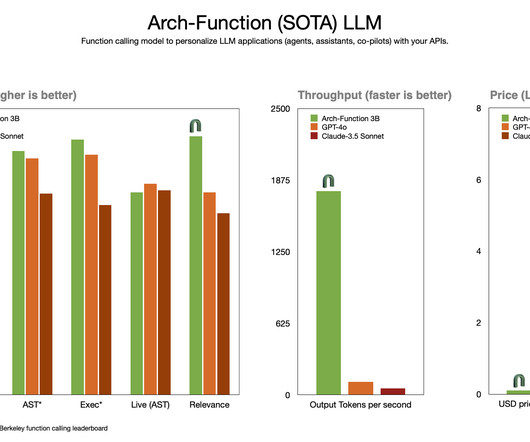
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Katanemo Open Sources Arch-Function: A Set of Large Language Models (LLMs) Promising Ultra-Fast Speeds at Function-Calling Tasks for Agentic Workflows appeared first on MarkTechPost.
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Stanford Researchers Propose LoLCATS: A Cutting Edge AI Method for Efficient LLM Linearization appeared first on MarkTechPost. If you like our work, you will love our newsletter.
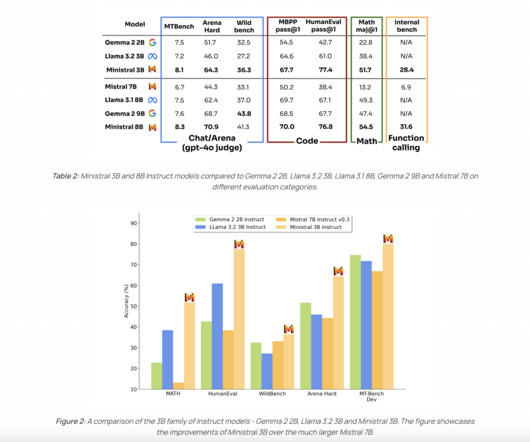
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Mistral AI Introduces Les Ministraux: Ministral 3B and Ministral 8B- Revolutionizing On-Device AI appeared first on MarkTechPost. If you like our work, you will love our newsletter.
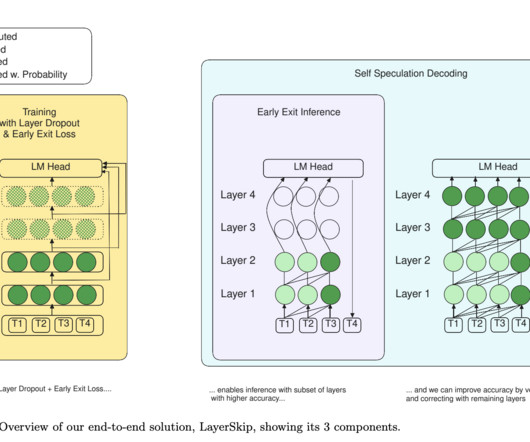
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Meta AI Releases LayerSkip: A Novel AI Approach to Accelerate Inference in Large Language Models (LLMs) appeared first on MarkTechPost. If you like our work, you will love our newsletter.
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Google AI Researchers Propose ‘MODEL SWARMS’: A Collaborative Search Algorithm to Flexibly Adapt Diverse LLM Experts to Wide-Ranging Purposes appeared first on MarkTechPost.
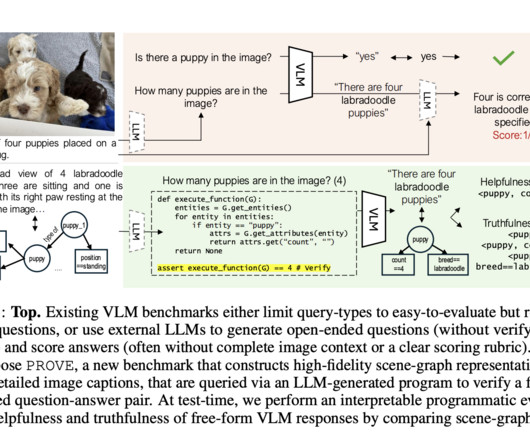
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Salesforce AI Research Propose Programmatic VLM Evaluation (PROVE): A New Benchmarking Paradigm for Evaluating VLM Responses to Open-Ended Queries appeared first on MarkTechPost.
NVIDIA NIM microservices, part of the NVIDIA AI Enterprise software platform, together with Google Kubernetes Engine (GKE) provide a streamlined path for developing AI-powered apps and deploying optimized AI models into production.
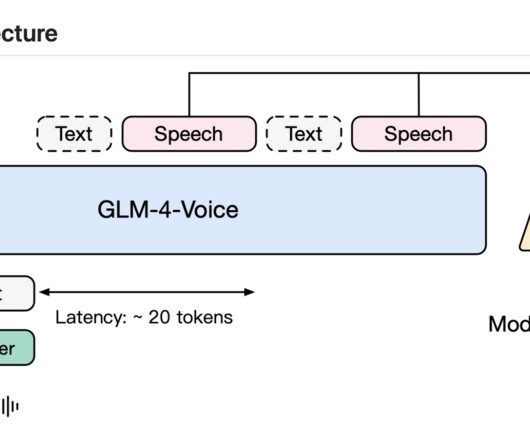
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Zhipu AI Releases GLM-4-Voice: A New Open-Source End-to-End Speech Large Language Model appeared first on MarkTechPost. If you like our work, you will love our newsletter.
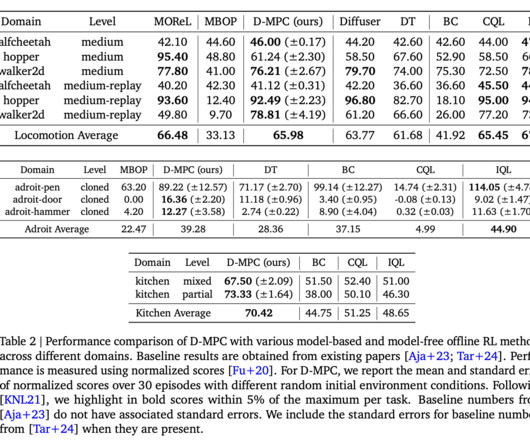
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Google DeepMind Introduces Diffusion Model Predictive Control (D-MPC): Combining Multi-Step Action Proposals and Dynamics Models Using Diffusion Models for Online MPC appeared first on MarkTechPost.
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Google Researchers Introduce UNBOUNDED: An Interactive Generative Infinite Game based on Generative AI Models appeared first on MarkTechPost. If you like our work, you will love our newsletter.
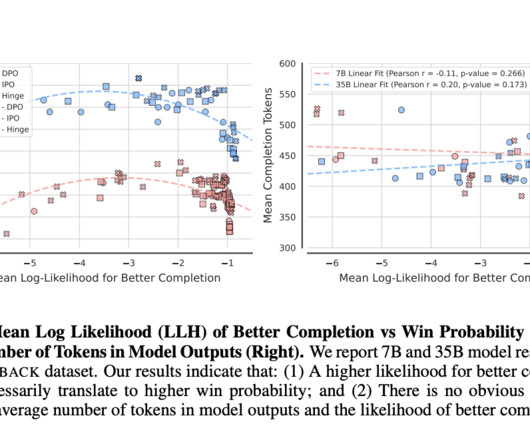
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Rethinking Direct Alignment: Balancing Likelihood and Diversity for Better Model Performance appeared first on MarkTechPost. If you like our work, you will love our newsletter.
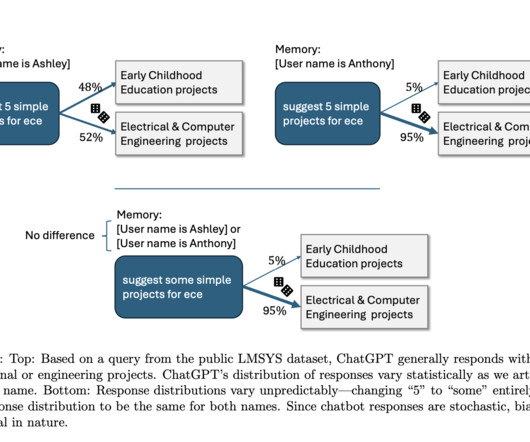
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post A New Study by OpenAI Explores How Users’ Names can Impact ChatGPT’s Responses appeared first on MarkTechPost. If you like our work, you will love our newsletter.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content