This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
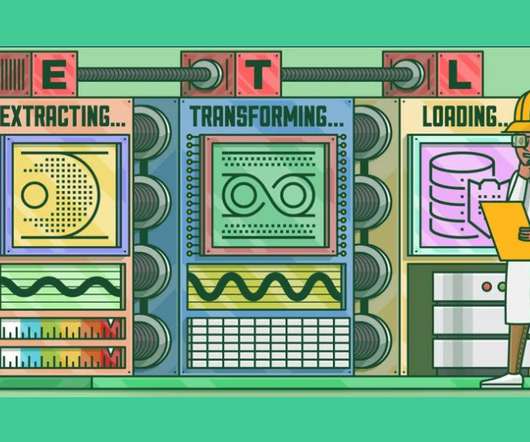
Introduction ETL pipelines look different today than they used to. The post Is manual ETL better than No-Code ETL: Are ETL tools dead? ArticleVideo Book This article was published as a part of the Data Science Blogathon. appeared first on Analytics Vidhya.
Introduction to ETLETL is a type of three-step data integration: Extraction, Transformation, Load are processing, used to combine data from multiple sources. The post Good ETL Practices with Apache Airflow appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
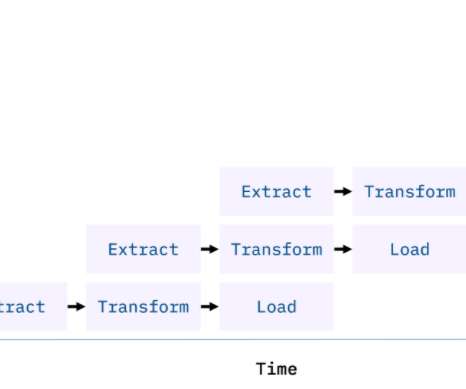
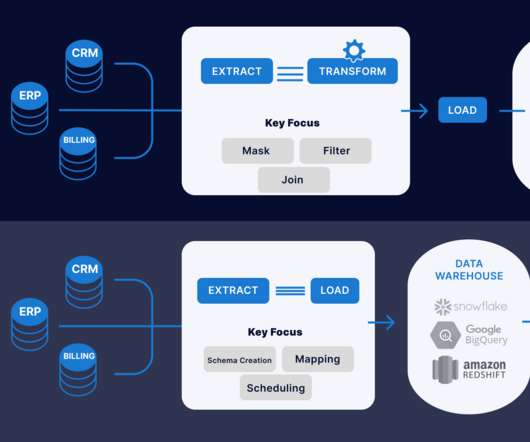
Introduction The data integration techniques ETL (Extract, Transform, Load) and ELT pipelines (Extract, Load, Transform) are both used to transfer data from one system to another.
Building an ETL pipeline using Apache […]. The post ETL Pipeline with Google DataFlow and Apache Beam appeared first on Analytics Vidhya. Introduction Processing large amounts of raw data from various sources requires appropriate tools and solutions for effective data integration.
Introduction on ETL Pipeline ETL pipelines are a set of processes used to transfer data from one or more sources to a database, like a data warehouse. The post A Complete Guide on Building an ETL Pipeline for Beginners appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
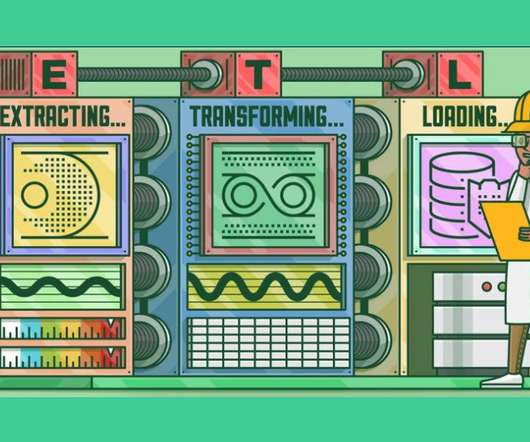
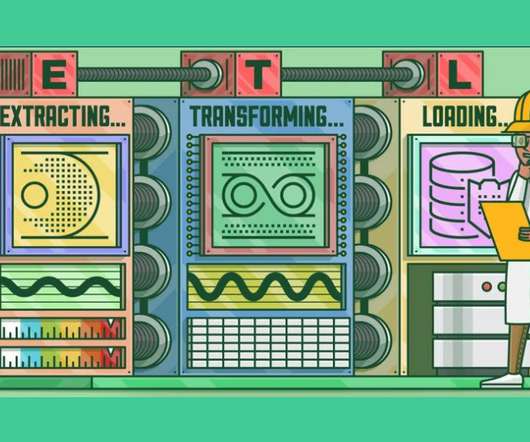
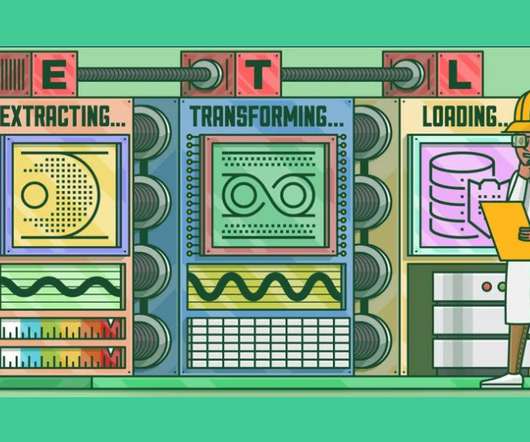
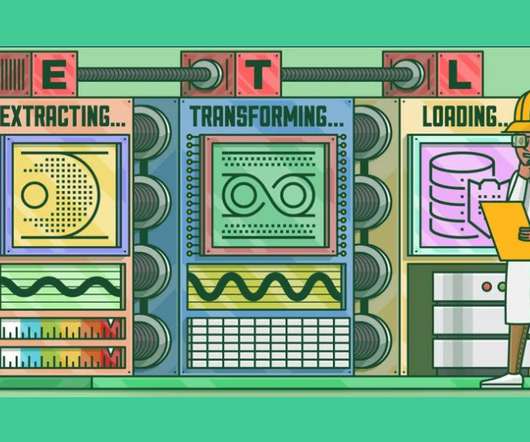
This crucial process, called Extract, Transform, Load (ETL), involves extracting data from multiple origins, transforming it into a consistent format, and loading it into a target system for analysis.
Introduction In this article, we attempt to capture the complexity of ETL and workflow orchestration tools, which aid in better data management and control by providing multiple alternatives for performing various operations in discrete blocks while maintaining visibility and clear goals for each action. We’ll continue […].
The post ETL vs ELT in 2022: Do they matter? Obtaining, structuring, and analyzing these data into new, relevant information is crucial in today’s world. Since contextual data exposes popular patterns and trends, we have arrived at the stage where businesses take data-driven decisions to […]. appeared first on Analytics Vidhya.
Introduction ETL pipelines can be built from bash scripts. You will learn about how shell scripting can implement an ETL pipeline, and how ETL scripts or tasks can be scheduled using shell scripting. The post ETL Pipeline using Shell Scripting | Data Pipeline appeared first on Analytics Vidhya. What is shell scripting?
Overview ETL (Extract, Transform, and Load) is a very common technique in data engineering. Traditionally, ETL processes are […]. The post Crafting Serverless ETL Pipeline Using AWS Glue and PySpark appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
Introduction At the highest level, ETL converts your data before uploading, while ELT converts data only after uploading to your repository. In this post, we will take a closer look at the differences between the way ETL and ELT work to help you […]. This article was published as a part of the Data Science Blogathon.
The post Implementing ETL Process Using Python to Learn Data Engineering appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon Overview: Assume the job of a Data Engineer, extracting data from.
Introduction on ETL Tools The amount of data being used or stored in today’s world is extremely huge. The post ETL Tools: A Brief Introduction appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon. While handling this huge amount of data, one has to […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction to ETLETL as the name suggests, Extract Transform and. The post Pandas Vs PETL for ETL appeared first on Analytics Vidhya.
Introduction This article will explain the difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) when data transformation occurs. In ETL, data is extracted from multiple locations to meet the requirements of the target data file and then placed into the file.
This article was published as a part of the Data Science Blogathon What is ETL? ETL is a process that extracts data from multiple source systems, changes it (through calculations, concatenations, and so on), and then puts it into the Data Warehouse system. ETL stands for Extract, Transform, and Load.
The post Apache Airflow used for Performing ETL appeared first on Analytics Vidhya. For example, they extract, transform and load data from various sources into their data warehouse. Sources include customer transactions, data from Software as a Service (SAAS) offerings, […].
Introduction In the era of Data storehouse, the need for assimilating the data from contrasting sources into a single consolidated database requires you to Extract the data from its parent source, Transform and amalgamate it, and thus, Load it into the consolidated database (ETL).
The post Introduction to Data Engineering- ETL, Star Schema and Airflow appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon A data scientist’s ability to extract value from data is closely related to how well-developed a company’s data storage and processing infrastructure is.
Users of Oozie can describe dependencies between various jobs […] The post Difference between ETL and ELT Pipeline appeared first on Analytics Vidhya. It enables users to plan and carry out complex data processing workflows while handling several tasks and operations throughout the Hadoop ecosystem.
Introduction ETL is the process that extracts the data from various data sources, transforms the collected data, and loads that data into a common data repository. The post Building an ETL Data Pipeline Using Azure Data Factory appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
Source: [link] Introduction If you are familiar with databases, or data warehouses, you have probably heard the term “ETL.” The post AWS Glue: Simplifying ETL Data Processing appeared first on Analytics Vidhya. As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well.
Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable. ETL/ELT tools typically have two components: a design time (to design data integration jobs) and a runtime (to execute data integration jobs).
In today’s data-driven world, extracting, transforming, and loading (ETL) data is crucial for gaining valuable insights. While many ETL tools exist, dbt (data build tool) is emerging as a game-changer. Introduction Have you ever struggled with managing complex data transformations?
Be it a streaming job or a batch job, ETL and ELT are irreplaceable. Before designing an ETL job, choosing optimal, performant, and cost-efficient tools […]. Introduction Data acclimates to countless shapes and sizes to complete its journey from a source to a destination.
Introduction on ETL Tools The amount of data being used or stored in today’s world is extremely huge. The post An Introduction on ETL Tools for Beginners appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon. While handling this huge amount of data, one has to […].
Introduction Apache Airflow is a powerful platform that revolutionizes the management and execution of Extracting, Transforming, and Loading (ETL) data processes. This article explores the intricacies of automating ETL pipelines using Apache Airflow on AWS EC2.
Introduction AWS Glue helps Data Engineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. This article was published as a part of the Data Science Blogathon. The managed service offers a simple and cost-effective method of categorizing and managing big data in an enterprise.
30% Off ODSC East, Fan-Favorite Speakers, Foundation Models for Times Series, and ETL Pipeline Orchestration The ODSC East 2025 Schedule isLIVE! Explore the must-attend sessions and cutting-edge tracks designed to equip AI practitioners, data scientists, and engineers with the latest advancements in AI and machine learning.
Introduction Azure data factory (ADF) is a cloud-based ETL (Extract, Transform, Load) tool and data integration service which allows you to create a data-driven workflow. This article was published as a part of the Data Science Blogathon. The data-driven workflow in ADF orchestrates and automates the data movement and data transformation.
It's the initial step in the larger process of ETL (Extract, Transform, Load), which involves pulling data (extracting), converting it into a usable format (transforming), and then loading it into a database or data warehouse (loading). Standing out in the ETL tool realm, Integrate.io What is Data Extraction?
Today, Databricks sets a new standard for ETL (Extract, Transform, Load) price and performance. While customers have been using Databricks for their ETL.
And so, there is no doubt that Data Engineers use it extensively to build and manage their ETL pipelines. Introduction Apache Airflow is the most popular tool for workflow management. But not all the pipelines you build in Airflow will be straightforward. Some are complex and require running one out of the many tasks based […].
This requires developing a lot of ETL jobs and transforming the data to guarantee a consistent structure for making it available at any next step in the […]. This article was published as a part of the Data Science Blogathon. The post Understand Apache Drill and its Working appeared first on Analytics Vidhya.
Introduction Azure data factory (ADF) is a cloud-based data ingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.
ArticleVideos I will admit, AWS Data Wrangler has become my go-to package for developing extract, transform, and load (ETL) data pipelines and other day-to-day. The post Using AWS Data Wrangler with AWS Glue Job 2.0 appeared first on Analytics Vidhya.
Coding in English at the speed of thoughtHow To Use ChatGPT as your next OCR & ETL Solution, Credit: David Leibowitz For a recent piece of research, I challenged ChatGPT to outperform Kroger’s marketing department in earning my loyalty.
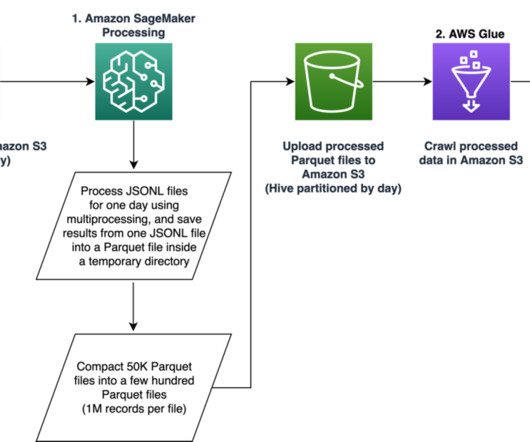
Our pipeline belongs to the general ETL (extract, transform, and load) process family that combines data from multiple sources into a large, central repository. The solution does not require porting the feature extraction code to use PySpark, as required when using AWS Glue as the ETL solution. session.Session().region_name
In this article, we will look at some data engineering basics for developing a so-called ETL pipeline. For example, recently, I started working on developing a model in an open-science manner for the European Space Agency for fine-tuning an LLM on data concerning earth observation and earth science.
“Data is at the center of every application, process, and business decision,” wrote Swami Sivasubramanian, VP of Database, Analytics, and Machine Learning at AWS, and I couldn’t agree more. A common pattern customers use today is to build data pipelines to move data from Amazon Aurora to Amazon Redshift.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content