
A Simple Guide to Real-Time Data Ingestion
Pickl AI
JULY 24, 2023
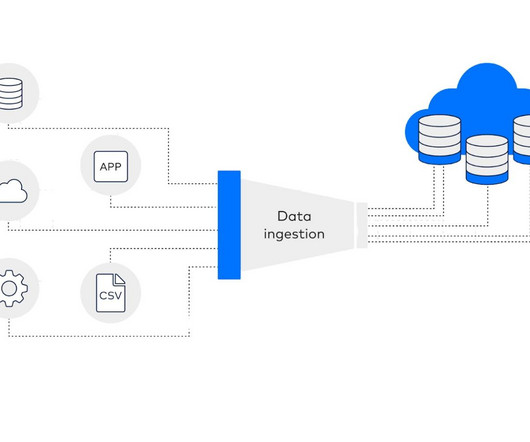
What is Real-Time Data Ingestion? Real-time data ingestion is the practise of gathering and analysing information as it is produced, without little to no lag between the emergence of the data and its accessibility for analysis. Traders need up-to-the-second information to make informed decisions.




















Let's personalize your content