This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This requires a careful, segregated network deployment process into various “functional layers” of DevOps functionality that, when executed in the correct order, provides a complete automated deployment that aligns closely with the IT DevOps capabilities. It also takes care of the major upgrades on the network function.
This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata. Generate metadata for the page. Generate metadata for the full document. Upload the content and metadata to Amazon S3.
Archival data in research institutions and national laboratories represents a vast repository of historical knowledge, yet much of it remains inaccessible due to factors like limited metadata and inconsistent labeling. Ian Lunsford is an Aerospace Cloud Consultant at AWS Professional Services.
This is where AgentOps comes in; a concept modeled after DevOps and MLOps but tailored for managing the lifecycle of FM-based agents. The Taxonomy of Traceable Artifacts The paper introduces a systematic taxonomy of artifacts that underpin AgentOps observability: Agent Creation Artifacts: Metadata about roles, goals, and constraints.
The functional architecture with different capabilities is implemented using a number of AWS services, including AWS Organizations , Amazon SageMaker , AWS DevOps services, and a data lake. Data engineers contribute to the data lineage process by providing the necessary information and metadata about the data transformations they perform.
The use of multiple external cloud providers complicated DevOps, support, and budgeting. This includes file type verification, size validation, and metadata extraction before routing to Amazon Textract. Each processed document maintains references to its source file, extraction timestamp, and processing metadata.
At its core, keyword search provides the essential baseline functionality of accurately matching user queries to product data and metadata, making sure explicit product names, brands, or attributes can be reliably retrieved. Then, it stores the vector embeddings, text, and metadata in an OpenSearch Service domain.
Choose the right technology and tools Select tools that support data cataloging, lineage tracking, metadata management and data quality monitoring, helping to ensure integration with the organization’s existing data management infrastructure for a seamless transition.
The embeddings, along with metadata about the source documents, are indexed for quick retrieval. He has over 6 years of experience in helping customers architecting a DevOps strategy for their cloud workloads. The embeddings are stored in the Amazon OpenSearch Service owner manuals index. He holds a Master’s in Information Systems.
OpenTelemetry and Prometheus enable the collection and transformation of metrics, which allows DevOps and IT teams to generate and act on performance insights. Benefits of OpenTelemetry The OpenTelemetry protocol (OTLP) simplifies observability by collecting telemetry data, like metrics, logs and traces, without changing code or metadata.
Lived through the DevOps revolution. Founded neptune.ai , a modular MLOps component for ML metadata store , aka “experiment tracker + model registry”. If you’d like a TLDR, here it is: MLOps is an extension of DevOps. There will be only one type of ML metadata store (model-first), not three. Came to ML from software.
Qovery Qovery stands out as a powerful DevOps Automation Platform that aims to streamline the development process and reduce the need for extensive DevOps hiring. This article explores the top internal developer platforms that are improving the way development teams work, deploy applications, and manage their infrastructure.
DevOps engineers often use Kubernetes to manage and scale ML applications, but before an ML model is available, it must be trained and evaluated and, if the quality of the obtained model is satisfactory, uploaded to a model registry. They often work with DevOps engineers to operate those pipelines. curl for transmitting data with URLs.
He is a technology enthusiast and a builder with a core area of interest in AI/ML, data analytics, serverless, and DevOps. Publish the BYOC image to Amazon ECR Create a script named model_quality_monitoring.py amazonaws.com/sm-mm-mqm-byoc:1.0", instance_count=1, instance_type='ml.m5.xlarge', Raju Patil is a Sr.
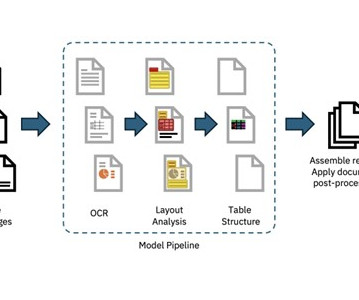
Each text, including the rotated text on the left of the page, is identified and extracted as a stand-alone text element with coordinates and other metadata that makes it possible to render a document very close to the original PDF but from a structured JSONformat.
It automatically keeps track of model artifacts, hyperparameters, and metadata, helping you to reproduce and audit model versions. As you move from pilot and test phases to deploying generative AI models at scale, you will need to apply DevOps practices to ML workloads.
The Annotated type is used to provide additional metadata about the return value, specifically that it should be included in the response body. With over 4 years at AWS and 2 years of previous experience as a DevOps engineer, Marwen works closely with customers to implement AWS best practices and troubleshoot complex technical challenges.
Machine learning operations (MLOps) applies DevOps principles to ML systems. Just like DevOps combines development and operations for software engineering, MLOps combines ML engineering and IT operations. Conclusion In summary, MLOps is critical for any organization that aims to deploy ML models in production systems at scale.
model.create() creates a model entity, which will be included in the custom metadata registered for this model version and later used in the second pipeline for batch inference and model monitoring. In Studio, you can choose any step to see its key metadata. large", accelerator_type="ml.eia1.medium", large", accelerator_type="ml.eia1.medium",
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Can you compare images?
That is where Provectus , an AWS Premier Consulting Partner with competencies in Machine Learning, Data & Analytics, and DevOps, stepped in. They needed a cloud platform and a strategic partner with proven expertise in delivering production-ready AI/ML solutions, to quickly bring EarthSnap to the market.
This feature will compute some DataRobot monitoring calculations outside of DataRobot and send the summary metadata to MLOps. 1 IDC, MLOps – Where ML Meets DevOps, doc #US48544922, March 2022. New DataRobot Large Scale Monitoring allows you to access aggregated prediction statistics. Learn More About DataRobot MLOps.
He has experience in backend and frontend programming languages, as well as system design and implementation of DevOps practices. You can find the campaign ARN in the Amazon Personalize console menu. These items brought in new movie genre (‘Animation|Children|Drama|Fantasy|Musical’) the top 5 recommendations.
The output of a SageMaker Ground Truth labeling job is a file in JSON-lines format containing the labels and additional metadata. With a passion for automation, Joerg has worked as a software developer, DevOps engineer, and Site Reliability Engineer in his pre-AWS life.
DevSecOps includes all the characteristics of DevOps, such as faster deployment, automated pipelines for build and deployment, extensive testing, etc., In this case, the provenance of the collected data is analyzed and the metadata is logged for future audit purposes.
Furthermore, metadata being redacted is being reported back to the business through an Elasticsearch dashboard, enabling alerts and further action. Since joining Very in 1998, Andy has undertaken a wide variety of roles covering content management and catalog production, stock management, production support, DevOps, and Fusion Middleware.
It combines principles from DevOps, such as continuous integration, continuous delivery, and continuous monitoring, with the unique challenges of managing machine learning models and datasets. As the adoption of machine learning in various industries continues to grow, the demand for robust MLOps tools has also increased. What is MLOps?
You can visualize the indexed metadata using OpenSearch Dashboards. Intelligent index and search With the OpenSearchPushInvoke Lambda function, the extracted expense metadata is pushed to an OpenSearch Service index and is available for search. His interests and experience include containers, serverless technology, and DevOps.
TR’s AI Platform microservices are built with Amazon SageMaker as the core engine, AWS serverless components for workflows, and AWS DevOps services for CI/CD practices. Increase transparency and collaboration by creating a centralized view of all models across TR alongside metadata and health metrics. Model deployment.
New GitHub Marketplace Action for CI/CD integrates DataRobot into your existing DevOps practices, custom inference metrics for tracking business performance , and an expanded suite of drift management capabilities ensure models perform as expected.
This is done on the features that security vendors might sign, starting from hardcoded strings, IP/domain names of C&C servers, registry keys, file paths, metadata, or even mutexes, certificates, offsets, as well as file extensions that are correlated to the encrypted files by ransomware.
The examples focus on questions on chunk-wise business knowledge while ignoring irrelevant metadata that might be contained in a chunk. He has touched on most aspects of these projects, from infrastructure and DevOps to software development and AI/ML. You can customize the prompt examples to fit your ground truth use case.
The metadata store is where MLflow keeps the experiment and model metadata. In my experience, even solo data scientists prefer setting up a tracking server rather than directly interfacing with metadata and artifact stores. After all, it exposes the UI, collects the metadata, and provides access to the model artifacts.
Metadata about the request/response pairings are logged to Amazon CloudWatch. Shuyu Yang is Generative AI and Large Language Model Delivery Lead and also leads CoE (Center of Excellence) Accenture AI (AWS DevOps professional) teams.
As per the definition and the required ML expertise, MLOps is required mostly for providers and fine-tuners, while consumers can use application productionization principles, such as DevOps and AppDev to create the generative AI applications. AppDev and DevOps – They develop the front end (such as a website) of the generative AI application.
To make that possible, your data scientists would need to store enough details about the environment the model was created in and the related metadata so that the model could be recreated with the same or similar outcomes. Collaboration The principles you have learned in this guide are mostly born out of DevOps principles.
Data scientists, ML engineers, IT staff, and DevOps teams must work together to operationalize models from research to deployment and maintenance. The model registry maintains records of model versions, their associated artifacts, lineage, and metadata. Building a robust MLOps pipeline demands cross-functional collaboration.
This data version is frequently recorded into your metadata management solution to ensure that your model training is versioned and repeatable. In addition to supporting batch and streaming data processing, Delta Lake also offers scalable metadata management. Neptune serves as a consolidated metadata store for each MLOps workflow.
Model cards are intended to be a single source of truth for business and technical metadata about the model that can reliably be used for auditing and documentation purposes. His core area of focus includes Machine Learning, DevOps, and Containers. They provide a fact sheet of the model that is important for model governance.
Anant Sharma is a software engineer at AWS Annapurna Labs specializing in DevOps. Amazon EKS configuration For Amazon EKS, create a simple pod YAML file to use the extended Neuron DLC. In his free time, he enjoys challenging himself with badminton, swimming and other various sports, and immersing himself in music.
The functional architecture with different capabilities is implemented using a number of AWS services, including AWS Organizations , SageMaker, AWS DevOps services, and a data lake. The architecture maps the different capabilities of the ML platform to AWS accounts.
The model artifacts and associated metadata are stored in the SageMaker Model Registry as the last step of the training process. All of the metadata for these experiments can be tracked using Amazon SageMaker Experiments during development. Shelbee Eigenbrode is a Principal AI and Machine Learning Specialist Solutions Architect at AWS.
These files contain metadata, current state details, and other information useful in planning and applying changes to infrastructure. This is critical especially when multiple DevOps team members are working on the configuration. In Terraform, the state files are important as they play a crucial role in monitoring resources.
Building a tool for managing experiments can help your data scientists; 1 Keep track of experiments across different projects, 2 Save experiment-related metadata, 3 Reproduce and compare results over time, 4 Share results with teammates, 5 Or push experiment outputs to downstream systems.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content