

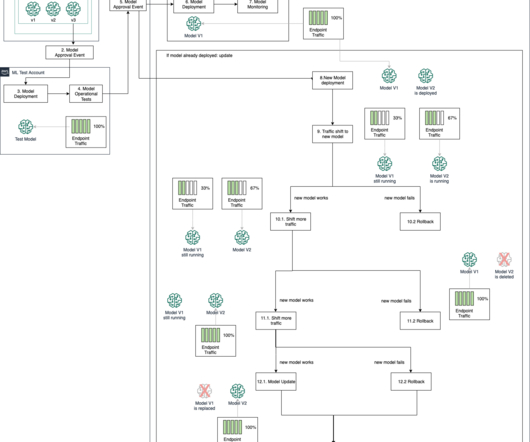
Create SageMaker Pipelines for training, consuming and monitoring your batch use cases
AWS Machine Learning Blog
APRIL 21, 2023
See the following code: # Configure the Data Quality Baseline Job # Configure the transient compute environment check_job_config = CheckJobConfig( role=role_arn, instance_count=1, instance_type="ml.c5.xlarge", In Studio, you can choose any step to see its key metadata. large", accelerator_type="ml.eia1.medium", medium', 'ml.m5.xlarge'],











Let's personalize your content