This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When we talk about data integrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. DataqualityDataquality is essentially the measure of data integrity.
Illumex enables organizations to deploy genAI analytics agents by translating scattered, cryptic data into meaningful, context-rich business language with built-in governance. By creating business terms, suggesting metrics, and identifying potential conflicts, Illumex ensures data governance at the highest standards.
It serves as the hub for defining and enforcing data governance policies, data cataloging, data lineage tracking, and managing data access controls across the organization. Data lake account (producer) – There can be one or more data lake accounts within the organization.
Connecting AI models to a myriad of data sources across cloud and on-premises environments AI models rely on vast amounts of data for training. Once trained and deployed, models also need reliable access to historical and real-time data to generate content, make recommendations, detect errors, send proactive alerts, etc.
Access to high-qualitydata can help organizations start successful products, defend against digital attacks, understand failures and pivot toward success. Emerging technologies and trends, such as machine learning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good dataquality.
An enterprise data catalog does all that a library inventory system does – namely streamlining data discovery and access across data sources – and a lot more. For example, data catalogs have evolved to deliver governance capabilities like managing dataquality and data privacy and compliance.
Early and proactive detection of deviations in model quality enables you to take corrective actions, such as retraining models, auditing upstream systems, or fixing quality issues without having to monitor models manually or build additional tooling. DataScientist with AWS Professional Services. Raju Patil is a Sr.
Some popular end-to-end MLOps platforms in 2023 Amazon SageMaker Amazon SageMaker provides a unified interface for data preprocessing, model training, and experimentation, allowing datascientists to collaborate and share code easily. It provides a high-level API that makes it easy to define and execute data science workflows.
In addition, organizations that rely on data must prioritize dataquality review. Data profiling is a crucial tool. For evaluating dataquality. Data profiling gives your company the tools to spot patterns, anticipate consumer actions, and create a solid data governance plan.
This blog explores their strategies, including custom chunking techniques, hybrid retrieval methods, and robust development frameworks designed for seamless collaboration between datascientists and machine learning engineers. Metadata tagging and filtering mechanisms safeguard proprietary data.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
Furthermore, evaluation processes are important not only for LLMs, but are becoming essential for assessing prompt template quality, input dataquality, and ultimately, the entire application stack. In this post, we show how to use FMEval and Amazon SageMaker to programmatically evaluate LLMs.
With 2,400+ expertly curated datasets that span healthcare, medical terminology, life sciences, and societal sectors, this massive data library promises to revolutionize the capabilities of datascientists across the industry. The data is regularly updated, and is available in a variety of formats with enriched metadata.
Amazon DataZone allows you to create and manage data zones , which are virtual data lakes that store and process your data, without the need for extensive coding or infrastructure management. Solution overview In this section, we provide an overview of three personas: the data admin, data publisher, and datascientist.
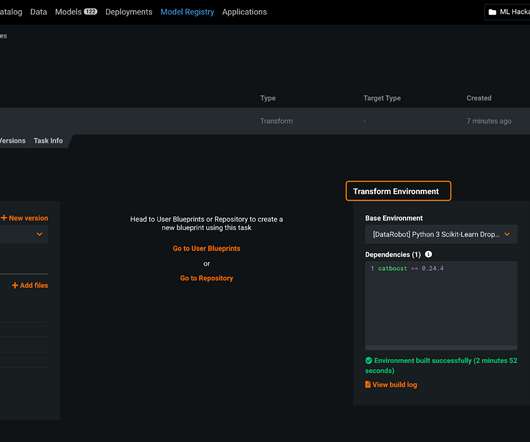
See the following code: # Configure the DataQuality Baseline Job # Configure the transient compute environment check_job_config = CheckJobConfig( role=role_arn, instance_count=1, instance_type="ml.c5.xlarge", In Studio, you can choose any step to see its key metadata. large", accelerator_type="ml.eia1.medium", medium', 'ml.m5.xlarge'],
It includes processes for monitoring model performance, managing risks, ensuring dataquality, and maintaining transparency and accountability throughout the model’s lifecycle. Runs are executions of some piece of data science code and record metadata and generated artifacts.
In contrast, data warehouses and relational databases adhere to the ‘Schema-on-Write’ model, where data must be structured and conform to predefined schemas before being loaded into the database. These snapshots can be used to roll back to a previous state or track data lineage.
Therefore, when the Principal team started tackling this project, they knew that ensuring the highest standard of data security such as regulatory compliance, data privacy, and dataquality would be a non-negotiable, key requirement. He has 20 years of enterprise software development experience.
With SageMaker MLOps tools, teams can easily train, test, troubleshoot, deploy, and govern ML models at scale to boost productivity of datascientists and ML engineers while maintaining model performance in production. Data Management – Efficient data management is crucial for AI/ML platforms.
Streamlining Unstructured Data for Retrieval Augmented Generatio n Matt Robinson | Open Source Tech Lead | Unstructured Learn about the complexities of handling unstructured data, and practical strategies for extracting usable text and metadata from it. You’ll also discuss loading processed data into destination storage.
As an MLOps engineer on your team, you are often tasked with improving the workflow of your datascientists by adding capabilities to your ML platform or by building standalone tools for them to use. And since you are reading this article, the datascientists you support have probably reached out for help.
Data Observability and DataQuality are two key aspects of data management. The focus of this blog is going to be on Data Observability tools and their key framework. The growing landscape of technology has motivated organizations to adopt newer ways to harness the power of data. What is Data Observability?
Models valuing customer retention or optimized business processes enable data-driven cost/benefit analysis. Broker connections between datascientists eager to innovate using machine learning and business leaders focused on driving revenue. Applying consistent semantic standards and metadata makes governance scalable.
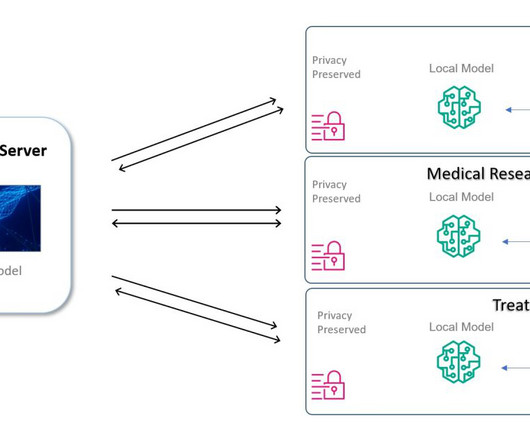
This is a guest blog post written by Nitin Kumar, a Lead DataScientist at T and T Consulting Services, Inc. In this decentralized ML approach, the ML model is shared between organizations for training on proprietary data subsets, unlike traditional centralized ML training, where the model generally trains on aggregated datasets.
The first step would be to make sure that the data used at the beginning of the model development process is thoroughly vetted, so that it is appropriate for the use case at hand. This requirement makes sure that no faulty data variables are being used to design a model, so erroneous results are not outputted. To reference SR 11-7: .
For any machine learning (ML) problem, the datascientist begins by working with data. This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process.
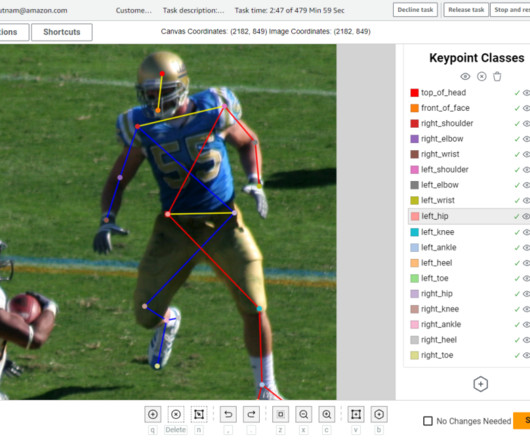
Labeling mistakes are important to identify and prevent because model performance for pose estimation models is heavily influenced by labeled dataquality and data volume. This custom workflow helps streamline the labeling process and minimize labeling errors, thereby reducing the cost of obtaining high-quality pose labels.
Unlike traditional databases, Data Lakes enable storage without the need for a predefined schema, making them highly flexible. Importance of Data Lakes Data Lakes play a pivotal role in modern data analytics, providing a platform for DataScientists and analysts to extract valuable insights from diverse data sources.
Together, Snorkel AI and Seldon enable enterprises to adopt AI across the business at scale by dramatically accelerating development and deployment and tightening the feedback loop to rapidly respond to data drift or changing business requirements. Model Management Simply having a model deployed covers the bare minimum of the MLOps lifecycle.
Together, Snorkel AI and Seldon enable enterprises to adopt AI across the business at scale by dramatically accelerating development and deployment and tightening the feedback loop to rapidly respond to data drift or changing business requirements. Model Management Simply having a model deployed covers the bare minimum of the MLOps lifecycle.
Cybersecurity Analyst Safeguarding organisations by analysing data to identify and prevent cyber threats, ensuring the security and integrity of digital systems. Spatial DataScientist Utilising geographical data to gain insights, solve location-based problems, and contribute to urban planning, environmental conservation, and logistics.
Master Nodes The master node is responsible for managing the cluster’s resources and coordinating the data processing tasks. It typically runs several critical services: NameNode: This service manages the Hadoop Distributed File System (HDFS) metadata, keeping track of the location of data blocks across the cluster.
This data source may be related to the sales sector, the manufacturing industry, finance, health, and R&D… Briefly, I am talking about a field-specific data source. The domain of the data. Regardless, the data fabric must be consistent for all its components. Data fabric needs metadata management maturity.
It is a central hub for researchers, datascientists, and Machine Learning practitioners to access real-world data crucial for building, testing, and refining Machine Learning models. DataQuality and Consistency Issues Many datasets in the UCI Repository suffer from incomplete, inconsistent, or noisy data.
Stefan is a software engineer, datascientist, and has been doing work as an ML engineer. He also ran the data platform in his previous company and is also co-creator of open-source framework, Hamilton. To a junior datascientist, it doesn’t matter if you’re using Airflow, Prefect , Dexter.
With the exponential growth of data and increasing complexities of the ecosystem, organizations face the challenge of ensuring data security and compliance with regulations. Data Processes and Organizational Structure Data Governance access controls enable the end-users to see how data processing works inside an organization.
Organizations struggle in multiple aspects, especially in modern-day data engineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. The second is that it can be really hard to classify and catalog data assets for discovery.
Organizations struggle in multiple aspects, especially in modern-day data engineering practices and getting ready for successful AI outcomes. One of them is that it is really hard to maintain high dataquality with rigorous validation. The second is that it can be really hard to classify and catalog data assets for discovery.
Collaboration : Ensuring that all teams involved in the project, including datascientists, engineers, and operations teams, are working together effectively. In the case of our CI/CD-MLOPs system, we stored the model versions and metadata in the data storage services offered by AWS i.e S3 buckets.
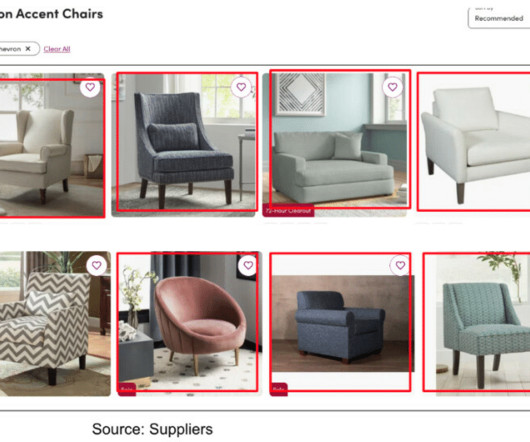
Wayfair x Snorkel computer vision Snorkel’s main product, the Snorkel Flow platform, enabled our datascientists to use an iterative process to programmatically label large sets of data leveraging foundation models and weak supervision rather than manually hand-labeling every data point.
Wayfair x Snorkel computer vision Snorkel’s main product, the Snorkel Flow platform, enabled our datascientists to use an iterative process to programmatically label large sets of data leveraging foundation models and weak supervision rather than manually hand-labeling every data point.
Wayfair x Snorkel computer vision Snorkel’s main product, the Snorkel Flow platform, enabled our datascientists to use an iterative process to programmatically label large sets of data leveraging foundation models and weak supervision rather than manually hand-labeling every data point.
The platform typically includes components for the ML ecosystem like data management, feature stores, experiment trackers, a model registry, a testing environment, model serving, and model management. Data validation (writing tests to check for dataquality). Data preprocessing.
This type of siloed thinking leads to data redundancy and slower data-retrieval speeds, so companies need to prioritize cross-functional communications and collaboration from the beginning. Here are four best practices to help future-proof your data strategy: 1.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content