

Knowledge Bases for Amazon Bedrock now supports metadata filtering to improve retrieval accuracy
AWS Machine Learning Blog
APRIL 8, 2024
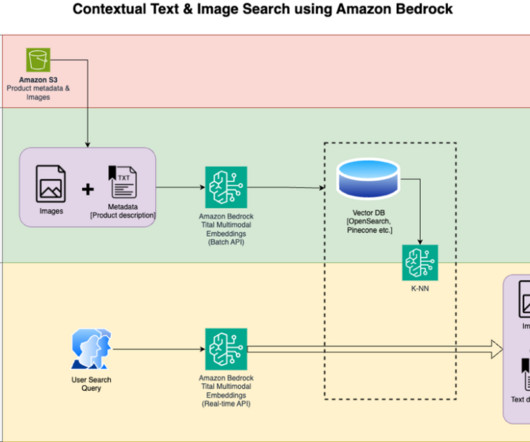
To refine the search results, you can filter based on document metadata to improve retrieval accuracy, which in turn leads to more relevant FM generations aligned with your interests. With this feature, you can now supply a custom metadata file (each up to 10 KB) for each document in the knowledge base. Virginia) and US West (Oregon).







































Let's personalize your content