

How IBM HR and the Chief Data Office partnered to drive data quality, increased productivity and a move to higher value work
IBM Journey to AI blog
AUGUST 2, 2023
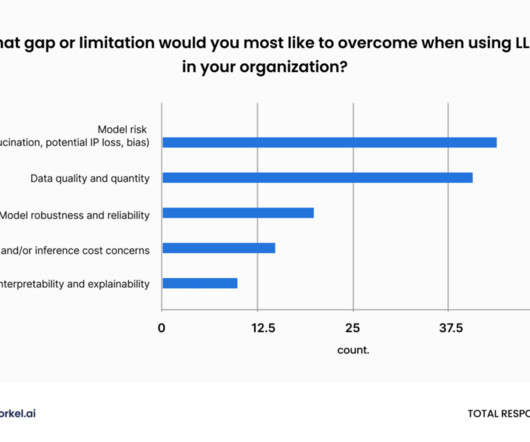
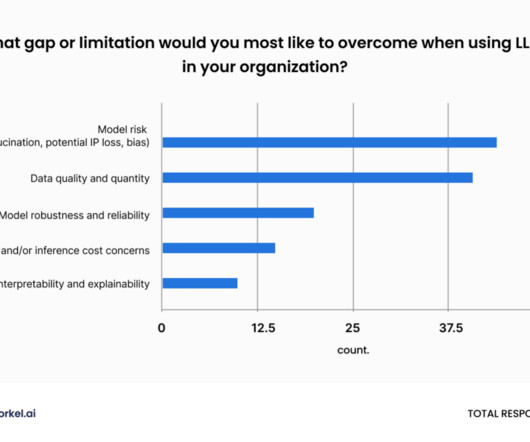
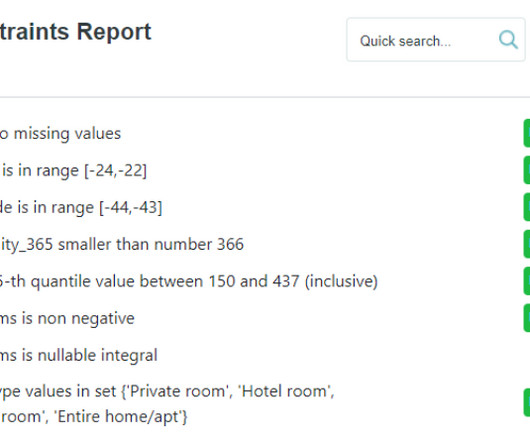
However, analytics are only as good as the quality of the data, which aims to be error-free, trustworthy, and transparent. According to a Gartner report , poor data quality costs organizations an average of USD $12.9 What is data quality? Data quality is critical for data governance.






































Let's personalize your content