This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction to ETLETL is a type of three-step data integration: Extraction, Transformation, Load are processing, used to combine data from multiple sources. It is commonly used to build BigData.
This article was published as a part of the Data Science Blogathon A data scientist’s ability to extract value from data is closely related to how well-developed a company’s data storage and processing infrastructure is.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
Introduction AWS Glue helps Data Engineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. The managed service offers a simple and cost-effective method of categorizing and managing bigdata in an enterprise. It provides organizations with […].
Ahead of AI & BigData Expo Europe , Han Heloir, EMEA gen AI senior solutions architect at MongoDB , discusses the future of AI-powered applications and the role of scalable databases in supporting generative AI and enhancing business processes. Check out AI & BigData Expo taking place in Amsterdam, California, and London.
Ahead of AI & BigData Expo Europe, AI News caught up with Ivo Everts, Senior Solutions Architect at Databricks , to discuss several key developments set to shape the future of open-source AI and data governance. With our GenAI app you can generate your own cartoon picture, all running on the Data Intelligence Platform.”
With their own unique architecture, capabilities, and optimum use cases, data warehouses and bigdata systems are two popular solutions. The differences between data warehouses and bigdata have been discussed in this article, along with their functions, areas of strength, and considerations for businesses.
With the advent of bigdata in the modern world, RTOS is becoming increasingly important. As software expert Tim Mangan explains, a purpose-built real-time OS is more suitable for apps that involve tons of data processing. The BigData and RTOS connection IoT and embedded devices are among the biggest sources of bigdata.
Our composable CDP ensures your data is AI-ready, helping you collect, clean, and activate customer data with our open, API-first platform and 450+ pre-built connectors that enable you to start with data anywhere and activate it everywhere. HT: Twilio Segment is excited to be taking part in AI & BigData Expo Europe in 2023!
“Data is at the center of every application, process, and business decision,” wrote Swami Sivasubramanian, VP of Database, Analytics, and Machine Learning at AWS, and I couldn’t agree more. A common pattern customers use today is to build data pipelines to move data from Amazon Aurora to Amazon Redshift.
Apart from the time-sensitive necessity of running a business with perishable, delicate goods, the company has significantly adopted Azure, moving some existing ETL applications to the cloud, while Hershey’s operations are built on a complex SAP environment. Check out AI & BigData Expo taking place in Amsterdam, California, and London.
ELT Pipelines: Typically used for bigdata, these pipelines extract data, load it into data warehouses or lakes, and then transform it. It is suitable for distributed and scalable large-scale data processing, providing quick big-data query and analysis capabilities.
Existing research emphasizes the significance of distributed processing and data quality control for enhancing LLMs. Utilizing frameworks like Slurm and Spark enables efficient bigdata management, while data quality improvements through deduplication, decontamination, and sentence length adjustments refine training datasets.
She has experience across analytics, bigdata, ETL, cloud operations, and cloud infrastructure management. Data Engineer at Amazon Ads. He builds and manages data-driven solutions for recommendation systems, working together with a diverse and talented team of scientists, engineers, and product managers.
It offers both open-source and enterprise/paid versions and facilitates bigdata management. Key Features: Seamless integration with cloud and on-premise environments, extensive data quality, and governance tools. Pros: Scalable, strong data governance features, support for bigdata.
To handle the log data efficiently, raw logs were centralized into an Amazon Simple Storage Service (Amazon S3) bucket. An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark.
It offers both open-source and enterprise/paid versions and facilitates bigdata management. Key Features: Seamless integration with cloud and on-premise environments, extensive data quality, and governance tools. Pros: Scalable, strong data governance features, support for bigdata.
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. What is ETL? ETL stands for Extract, Transform, and Load.
Extract, Transform, and Load are referred to as ETL. ETL is the process of gathering data from numerous sources, standardizing it, and then transferring it to a central database, data lake, data warehouse, or data store for additional analysis. Involved in each step of the end-to-end ETL process are: 1.
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
In this digital economy, data is paramount. Today, all sectors, from private enterprises to public entities, use bigdata to make critical business decisions. However, the data ecosystem faces numerous challenges regarding large data volume, variety, and velocity. Enter data warehousing!
It is ideal for handling unstructured or semi-structured data, making it perfect for modern applications that require scalability and fast access. Apache Spark Apache Spark is a powerful data processing framework that efficiently handles BigData. It integrates well with various data sources, making analysis easier.
Summary: HDFS in BigData uses distributed storage and replication to manage massive datasets efficiently. By co-locating data and computations, HDFS delivers high throughput, enabling advanced analytics and driving data-driven insights across various industries. It fosters reliability. between 2024 and 2030.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
Automation has been a key trend in the past few years and that ranges from the design to building of a data warehouse to loading and maintaining, all of that can be automated.
Transform raw insurance data into CSV format acceptable to Neptune Bulk Loader , using an AWS Glue extract, transform, and load (ETL) job. When the data is in CSV format, use an Amazon SageMaker Jupyter notebook to run a PySpark script to load the raw data into Neptune and visualize it in a Jupyter notebook.
Nowadays most businesses use data science, whether a business is product-based or service-based they use data science for their growth. Data Science and BigData There is an Umbrella of Bigdata and what is BigData?
The first generation of data architectures represented by enterprise data warehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized data engineers understood, resulting in an under-realized positive impact on the business.
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines.
About the Authors Noritaka Sekiyama is a Principal BigData Architect on the AWS Glue team. Chiho Sugimoto is a Cloud Support Engineer on the AWS BigData Support team. She is passionate about helping customers build data lakes using ETL workloads. BigData Architect. Zach Mitchell is a Sr.
The embeddings are captured in Amazon Simple Storage Service (Amazon S3) via Amazon Kinesis Data Firehose , and we run a combination of AWS Glue extract, transform, and load (ETL) jobs and Jupyter notebooks to perform the embedding analysis. Set the parameters for the ETL job as follows and run the job: Set --job_type to BASELINE.
The ORC and Parquet are columnal storage and they are famous in the BigData world because of their efficient storage. Create a new Glue Crawler to discover and catalog your data in S3. This is necessary for Glue to understand the structure of your data. Create a Glue Job to perform ETL operations on your data.
In the ever-evolving world of bigdata, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Unlike traditional data warehouses or relational databases, data lakes accept data from a variety of sources, without the need for prior data transformation or schema definition.
Introduction Enterprises here and now catalyze vast quantities of data, which can be a high-end source of business intelligence and insight when used appropriately. Delta Lake allows businesses to access and break new data down in real time.
Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation. With a user-friendly interface and robust features, NiFi simplifies complex data workflows and enhances real-time data integration. Its visual interface allows users to design complex ETL workflows with ease.
You may use OpenRefine for more than just data cleaning; it can also help you find mistakes and outliers that could compromise your data’s quality. Apache Griffin Apache Griffin is an open-source data quality tool that aims to enhance bigdata processes.
It discusses performance, use cases, and cost, helping you choose the best framework for your bigdata needs. Introduction Apache Spark and Hadoop are potent frameworks for bigdata processing and distributed computing. Apache Spark is an open-source, unified analytics engine for large-scale data processing.
There are various architectural design patterns in data engineering that are used to solve different data-related problems. This article discusses five commonly used architectural design patterns in data engineering and their use cases. Finally, the transformed data is loaded into the target system.
Enhanced Data Quality : These tools ensure data consistency and accuracy, eliminating errors often occurring during manual transformation. Scalability : Whether handling small datasets or processing bigdata, transformation tools can easily scale to accommodate growing data volumes.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
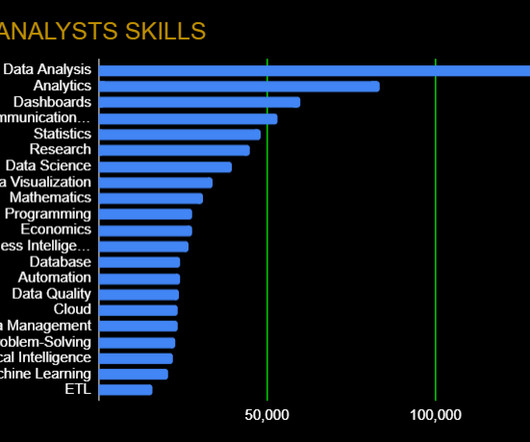
Data Wrangling: Data Quality, ETL, Databases, BigData The modern data analyst is expected to be able to source and retrieve their own data for analysis. Competence in data quality, databases, and ETL (Extract, Transform, Load) are essential.
Thus, making it easier for analysts and data scientists to leverage their SQL skills for BigData analysis. It applies the data structure during querying rather than data ingestion. This integration allows users to combine the strengths of different tools and frameworks to solve complex big-data challenges.
This article lists the top data analysis courses that can help you build the essential skills needed to excel in this rapidly growing field. Introduction to Data Analytics This course provides a comprehensive introduction to data analysis, covering the roles of data professionals, data ecosystems, and BigData tools like Hadoop and Spark.
Data Quality: Without proper governance, data quality can become an issue. Performance: Query performance can be slower compared to optimized data stores. Business Applications: BigData Analytics : Supporting advanced analytics, machine learning, and artificial intelligence applications.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content