

Introduction to Large Language Models (LLMs): An Overview of BERT, GPT, and Other Popular Models
John Snow Labs
JUNE 27, 2023
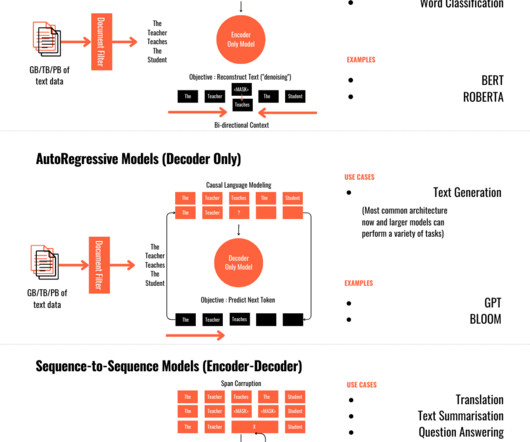
In this section, we will provide an overview of two widely recognized LLMs, BERT and GPT, and introduce other notable models like T5, Pythia, Dolly, Bloom, Falcon, StarCoder, Orca, LLAMA, and Vicuna. BERT excels in understanding context and generating contextually relevant representations for a given text.
























Let's personalize your content