This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The popular ML Olympiad is back for its third round with over 20 community-hosted machine learning competitions on Kaggle. This year’s lineup includes challenges spanning areas like healthcare, sustainability, naturallanguageprocessing (NLP), computer vision, and more.
According to a recent report by Harnham , a leading data and analytics recruitment agency in the UK, the demand for ML engineering roles has been steadily rising over the past few years. Advancements in AI and ML are transforming the landscape and creating exciting new job opportunities.
This open-source model, built upon a hybrid architecture combining Mamba-2’s feedforward and sliding window attention layers, is a milestone development in naturallanguageprocessing (NLP). Parameter Open-Source Small Language Model Transforming NaturalLanguageProcessing Applications appeared first on MarkTechPost.
Large language models ( LLMs ) like GPT-4, PaLM, Bard, and Copilot have made a huge impact in naturallanguageprocessing (NLP). Dont Forget to join our 65k+ ML SubReddit. They can generate text, solve problems, and carry out conversations with remarkable accuracy.
Large language models’ (LLMs) training pipelines are the source of inspiration for this method in the field of naturallanguageprocessing (NLP). Tokenizing input is a crucial part of LLM training, and it’s commonly accomplished using byte pair encoding (BPE).
Large Language Models (LLMs) have shown remarkable capabilities across diverse naturallanguageprocessing tasks, from generating text to contextual reasoning. Dont Forget to join our 60k+ ML SubReddit. However, their efficiency is often hampered by the quadratic complexity of the self-attention mechanism.
The field of naturallanguageprocessing (NLP) has grown rapidly in recent years, creating a pressing need for better datasets to train large language models (LLMs). Dont Forget to join our 60k+ ML SubReddit. Also, dont forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
Addressing this challenge, researchers from Eindhoven University of Technology have introduced a novel method that leverages the power of pre-trained Transformer models, a proven success in various domains such as Computer Vision and NaturalLanguageProcessing. If you like our work, you will love our newsletter.
It often requires managing multiple machine learning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. He leads machine learning initiatives and projects across business domains, leveraging multimodal AI, generative models, computer vision, and naturallanguageprocessing.
70b by Mobius Labs, boasting 70 billion parameters, has been designed to enhance the capabilities in naturallanguageprocessing (NLP), image recognition, and data analysis. Its improvements in naturallanguageprocessing, image recognition, and data analysis, combined with its efficiency and scalability.
Amazon Connect forwards the user’s message to Amazon Lex for naturallanguageprocessing. She leads machine learning projects in various domains such as computer vision, naturallanguageprocessing, and generative AI. For returning users, it resumes their existing Amazon Connect session.
In the rapidly evolving field of naturallanguageprocessing (NLP), integrating external knowledge bases through Retrieval-Augmented Generation (RAG) systems represents a significant leap forward. Don’t Forget to join our 47k+ ML SubReddit Find Upcoming AI Webinars here The post Is the Future of Agentic AI Personal?
Considering the major influence of autoregressive ( AR ) generative models, such as Large Language Models in naturallanguageprocessing ( NLP ), it’s interesting to explore whether similar approaches can work for images. Don’t Forget to join our 55k+ ML SubReddit.
These findings highlight the impact of model size on RAG performance and provide valuable insights for naturallanguageprocessing research. By providing a standardized approach for assessment and a platform for innovation, RAGLAB is poised to become an essential tool for naturallanguageprocessing researchers.
With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value. She leads machine learning projects in various domains such as computer vision, naturallanguageprocessing, and generative AI. In her free time, she likes to go for long runs along the beach.
The rise of Transformer-based models has significantly advanced the field of naturallanguageprocessing. Don’t Forget to join our 50k+ ML SubReddit. However, the training of these models is often computationally intensive, requiring substantial resources and time. If you like our work, you will love our newsletter.
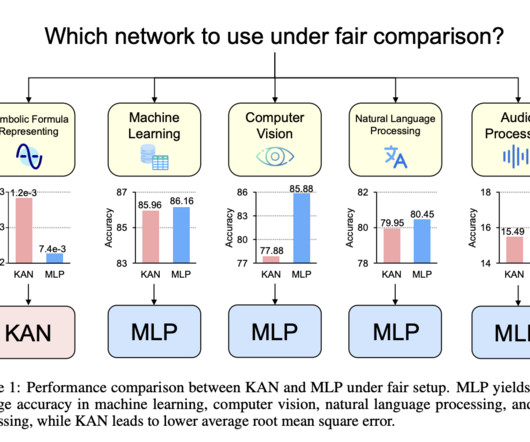
The researchers control parameters and FLOPs for both network types, evaluating their performance across diverse domains, including symbolic formula representation, machine learning, computer vision, naturallanguageprocessing, and audio processing. If you like our work, you will love our newsletter.
Recent advancements in LLMs have revolutionized naturallanguageprocessing, yet the persistent challenge of hallucinations necessitates a deeper examination of their fundamental nature and implications. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
This study highlighted the need for ongoing innovation in language model reasoning capabilities to address the full range of challenges in naturallanguageprocessing. Check out the Paper. All credit for this research goes to the researchers of this project. If you like our work, you will love our newsletter.
Transformers are a groundbreaking innovation in AI, particularly in naturallanguageprocessing and machine learning. Despite their pervasive use, the internal mechanics of Transformers remain a mystery to many, especially those who lack a deep technical background in machine learning.
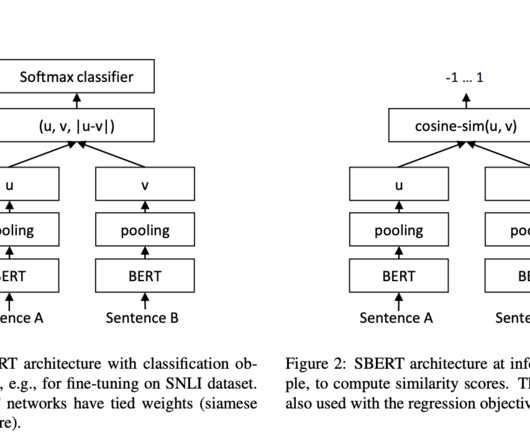
Researchers have focused on developing and building models to process and compare human language in naturallanguageprocessing efficiently. This technology is crucial for semantic search, clustering, and naturallanguage inference tasks. Check out the Paper.
The solution simplifies the setup process, allowing you to quickly deploy and start querying your data using the selected FM. He has successfully delivered state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
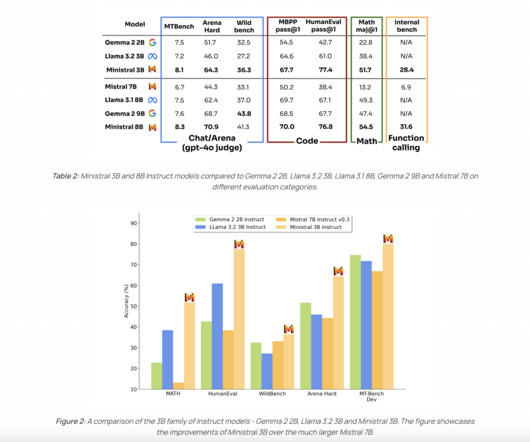
The models are named based on their respective parameter counts—3 billion and 8 billion parameters—which are notably efficient for edge environments while still being robust enough for a wide range of naturallanguageprocessing tasks. Don’t Forget to join our 50k+ ML SubReddit.
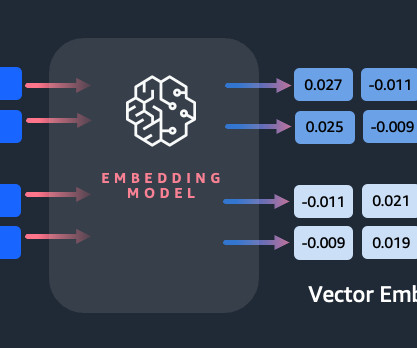
Embeddings play a key role in naturallanguageprocessing (NLP) and machine learning (ML). Text embedding refers to the process of transforming text into numerical representations that reside in a high-dimensional vector space. Nitin Eusebius is a Sr. In her free time, she likes to go for long runs along the beach.
These models have revolutionized naturallanguageprocessing, computer vision, and data analytics but have significant computational challenges. Specifically, as models grow larger, they require vast computational resources to process immense datasets. If you like our work, you will love our newsletter.
Large Language Models (LLMs) have achieved remarkable progress in the ever-expanding realm of artificial intelligence, revolutionizing naturallanguageprocessing and interaction. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
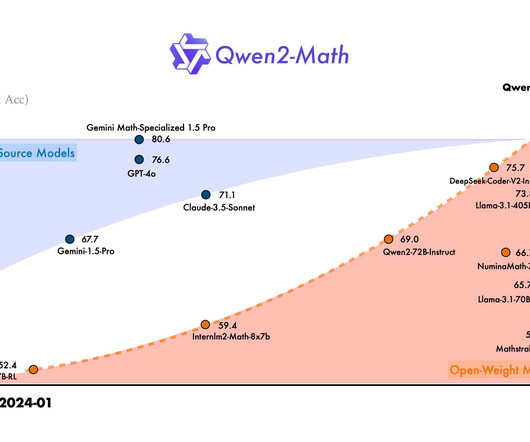
Image Source Each model in the series is built on a refined version of the architecture used in previous Qwen models, incorporating new techniques in deep learning, naturallanguageprocessing, and symbolic reasoning. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
Large Language Models (LLMs) have revolutionized naturallanguageprocessing, demonstrating remarkable capabilities in various applications. Transformer architecture has emerged as a major leap in naturallanguageprocessing, significantly outperforming earlier recurrent neural networks.
This research paper addresses the limitations of existing agentic frameworks in naturallanguageprocessing (NLP) tasks, particularly the inefficiencies in handling dynamic and complex queries that require context refinement and interactive problem-solving. If you like our work, you will love our newsletter.
The field of naturallanguageprocessing has made substantial strides with the advent of Large Language Models (LLMs), which have shown remarkable proficiency in tasks such as question answering. These models, trained on extensive datasets, can generate highly plausible and contextually appropriate responses.
Overall, this work presents a significant advancement in generative modeling techniques, provides a promising pathway toward better naturallanguageprocessing outcomes, and marks a new benchmark for similar future research in this domain. Don’t Forget to join our 50k+ ML SubReddit. Check out the Paper and GitHub.
The recent development of large language models (LLMs) has transformed the field of NaturalLanguageProcessing (NLP). LLMs show human-level performance in many professional and academic fields, showing a great understanding of language rules and patterns. If you like our work, you will love our newsletter.
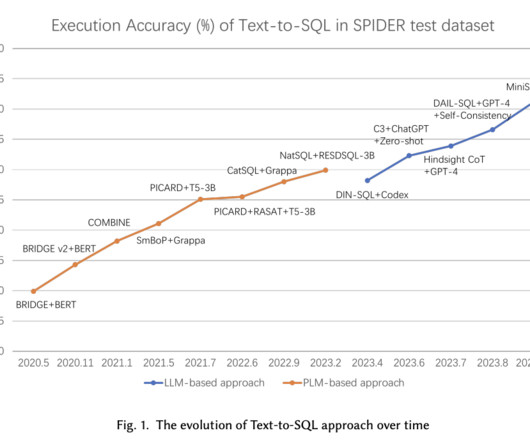
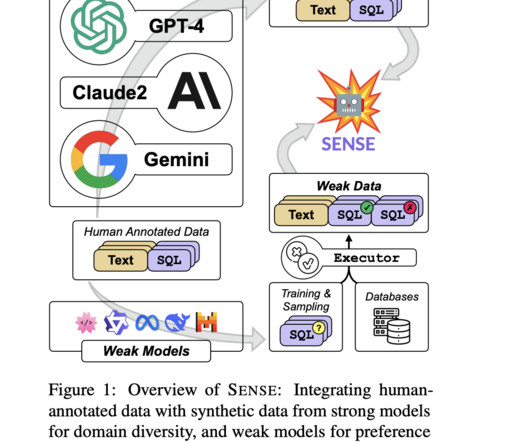
The inherent complexity of SQL syntax and the intricacies involved in database schema understanding make this a significant problem in naturallanguageprocessing (NLP) and database management. The proposed method in this paper leverages LLMs for Text-to-SQL tasks through two main strategies: prompt engineering and fine-tuning.
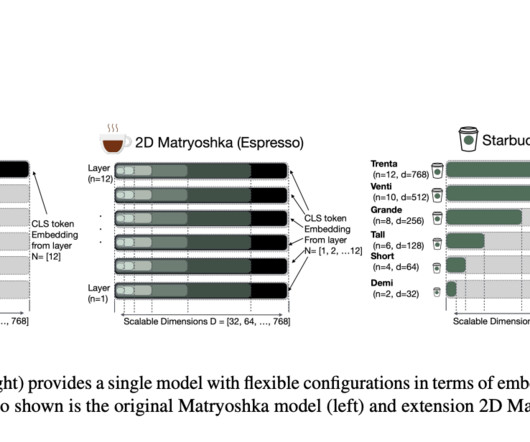
The empirical results of the Starbucks methodology demonstrate that it performs very well by improving the relevant performance metrics on the given tasks of naturallanguageprocessing, particularly while considering the assessment task of text similarity and semantic comparison, as well as its information retrieval variant.
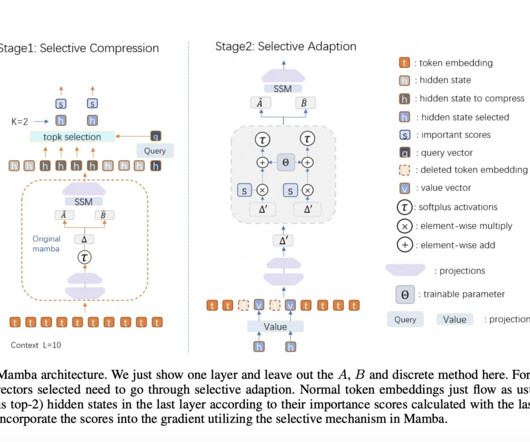
In naturallanguageprocessing (NLP), handling long text sequences effectively is a critical challenge. Traditional transformer models, widely used in large language models (LLMs), excel in many tasks but must be improved when processing lengthy inputs. Check out the Paper. Point Boost on LongBench and 1.6-Point
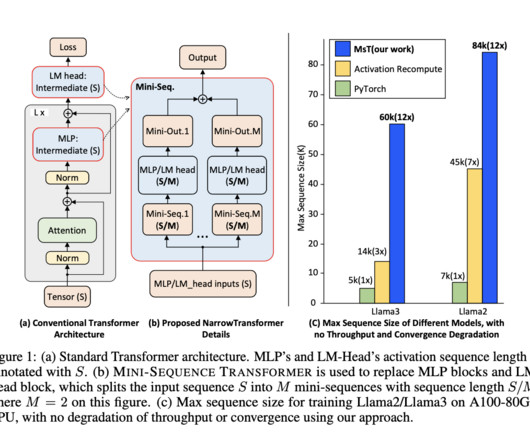
The evolution of Transformer models has revolutionized naturallanguageprocessing (NLP) by significantly advancing model performance and capabilities. However, this rapid development has introduced substantial challenges, particularly regarding the memory requirements for training these large-scale models.
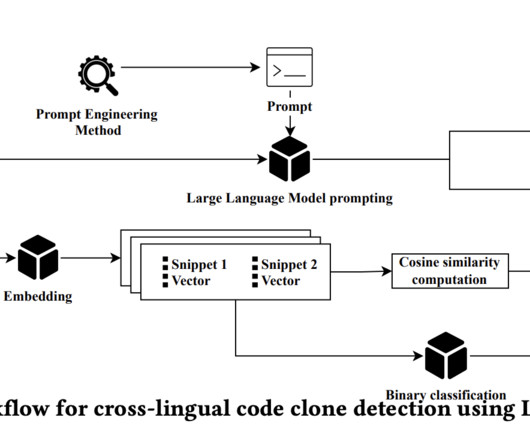
Recent advances in Artificial Intelligence and Machine Learning have made tremendous progress in handling many computing jobs possible, especially with the introduction of Large Language Models (LLMs). The study contrasts LLM performance with traditional ML techniques using learned code representations as a basis.
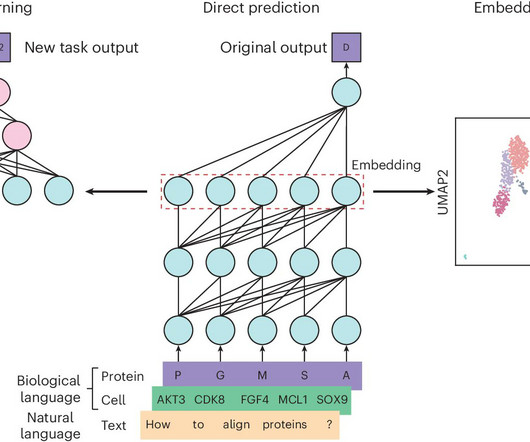
Biological data, such as DNA, RNA, and protein sequences, are fundamentally different from naturallanguage text, yet they share sequential characteristics that make them amenable to similar processing techniques. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
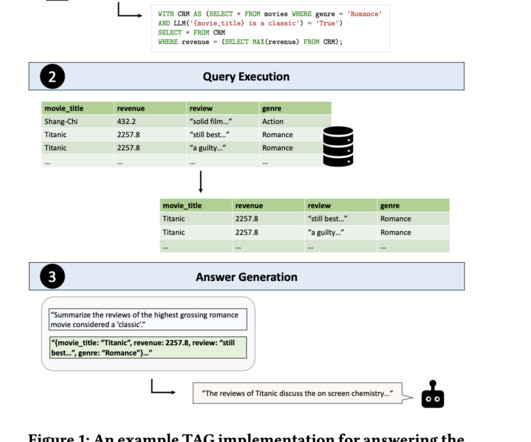
AI systems integrating naturallanguageprocessing with database management can unlock significant value by enabling users to query custom data sources using naturallanguage. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
As a result, open-source LLMs gained great attention for offering similar performance to their closed-source counterparts in various naturallanguageprocessing tasks. However, adopting closed-source LLMs raises concerns about openness, privacy, and substantial costs. If you like our work, you will love our newsletter.
Source: [link] AI encompasses several subfields, including: Machine Learning (ML): Algorithms that learn from data to improve their performance over time. NaturalLanguageProcessing (NLP): Techniques for processing and understanding human language. Dont Forget to join our 65k+ ML SubReddit.
This comprehensive approach provides insights into LM hallucinations and their detectability, contributing to the field of naturallanguageprocessing. The study reveals that larger language models and extended training reduce hallucinations on fixed datasets, while increased dataset size elevates hallucination rates.
Thus, developing effective methods to reduce hallucinations without compromising the model’s performance is a significant goal in naturallanguageprocessing. These hallucinations can manifest as incorrect facts or misrepresentations, impacting the model’s utility in sensitive applications.
LLMs leverage the transformer architecture, particularly the self-attention mechanism, for high performance in naturallanguageprocessing tasks. Don’t Forget to join our 50k+ ML SubReddit. These “lazy layers” become redundant as they fail to learn meaningful representations.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content