This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The relevance of this context directly impacts the model’s ability to generate accurate and contextually appropriate responses. One effective way to improve context relevance is through metadata filtering, which allows you to refine search results by pre-filtering the vector store based on custom metadata attributes.
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
As generative AI continues to drive innovation across industries and our daily lives, the need for responsibleAI has become increasingly important. At AWS, we believe the long-term success of AI depends on the ability to inspire trust among users, customers, and society.
This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata. It offers a broad set of capabilities to build generative AI applications with security, privacy, and responsibleAI practices.
Database metadata can be expressed in various formats, including schema.org and DCAT. ML data has unique requirements, like combining and extracting data from structured and unstructured sources, having metadata allowing for responsible data use, or describing ML usage characteristics like training, test, and validation sets.
Gartner predicts that the market for artificial intelligence (AI) software will reach almost $134.8 Achieving ResponsibleAI As building and scaling AI models for your organization becomes more business critical, achieving ResponsibleAI (RAI) should be considered a highly relevant topic. billion by 2025.
At the forefront of using generative AI in the insurance industry, Verisks generative AI-powered solutions, like Mozart, remain rooted in ethical and responsibleAI use. For the generative AI description of change, Verisk wanted to capture the essence of the change instead of merely highlighting the differences.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsibleAI.
Challenges around managing risk and reputation Customers, employees and shareholders expect organizations to use AIresponsibly, and government entities are starting to demand it. ResponsibleAI use is critical, especially as more and more organizations share concerns about potential damage to their brand when implementing AI.
But the implementation of AI is only one piece of the puzzle. The tasks behind efficient, responsibleAI lifecycle management The continuous application of AI and the ability to benefit from its ongoing use require the persistent management of a dynamic and intricate AI lifecycle—and doing so efficiently and responsibly.
Built with responsibleAI, Amazon Bedrock Data Automation enhances transparency with visual grounding and confidence scores, allowing outputs to be validated before integration into mission-critical workflows. It helps ensure high accuracy and cost efficiency while significantly lowering processing costs.
An AI-native data abstraction layer acts as a controlled gateway, ensuring your LLMs only access relevant information and follow proper security protocols. It can also enable consistent access to metadata and context no matter what models you are using. AI governance manages three things.
Strong data governance is foundational to robust artificial intelligence (AI) governance. Companies developing or deploying responsibleAI must start with strong data governance to prepare for current or upcoming regulations and to create AI that is explainable, transparent and fair.
It stores information such as job ID, status, creation time, and other metadata. The following is a screenshot of the DynamoDB table where you can track the job status and other types of metadata related to the job. The DynamoDB table is crucial for tracking and managing the batch inference jobs throughout their lifecycle.
Additionally, the metadata of SeamlessAlign – the largest multimodal translation dataset ever compiled, consisting of 270,000 hours of mined speech and text alignments – has been released. The result is a model that outperforms previous leaders: To ensure the accuracy and safety of the system, Meta adheres to a responsibleAI framework.
In this second part, we expand the solution and show to further accelerate innovation by centralizing common Generative AI components. We also dive deeper into access patterns, governance, responsibleAI, observability, and common solution designs like Retrieval Augmented Generation. This logic sits in a hybrid search component.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. The image was generated using the Stability AI (SDXL 1.0) model on Amazon Bedrock.
In addition, the CPO AI Ethics Project Office supports all of these initiatives, serving as a liaison between governance roles, supporting implementation of technology ethics priorities, helping establish AI Ethics Board agendas and ensuring the board is kept up to date on industry trends and company strategy.
AI governance refers to the practice of directing, managing and monitoring an organization’s AI activities. It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. Monitor, catalog and govern models from anywhere across your AI’s lifecycle.
The Amazon Bedrock evaluation tool provides a comprehensive assessment framework with eight metrics that cover both response quality and responsibleAI considerations. Implement metadata filtering , adding contextual layers to chunk retrieval. For example, prioritizing recent information in time-sensitive scenarios.
Participants learn to build metadata for documents containing text and images, retrieve relevant text chunks, and print citations using Multimodal RAG with Gemini. Introduction to ResponsibleAI This course explains what responsibleAI is, its importance, and how Google implements it in its products.
Building enhanced semantic search capabilities that analyze media contextually would lay the groundwork for creating AI-generated content, allowing customers to produce customized media more efficiently. With recent advances in large language models (LLMs), Veritone has updated its platform with these powerful new AI capabilities.
You can use metadata filtering to narrow down search results by specifying inclusion and exclusion criteria. ResponsibleAI Implementing responsibleAI practices is crucial for maintaining ethical and safe deployment of RAG systems. You can use Amazon Bedrock Guardrails for implementing responsibleAI policies.
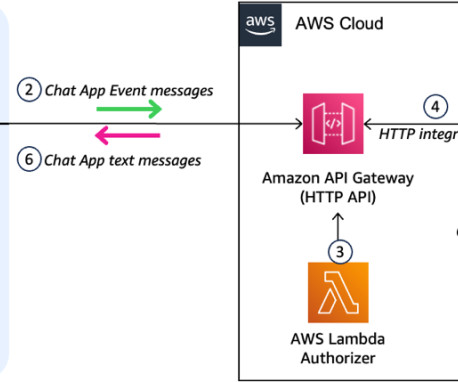
This request contains the user’s message and relevant metadata. Consider integrating Amazon Bedrock Guardrails to implement safeguards customized to your application requirements and responsibleAI policies. The custom Google Chat app, configured for HTTP integration, sends an HTTP request to an API Gateway endpoint.
Retrieve images stored in S3 bucket response = s3.list_objects_v2(Bucket=BUCKET_NAME) To tag each embedding with the image file name, you must also add a mapping field under Metadata management. client('s3') bedrock_client = boto3.client( You can use the following code to fulfill both requirements. b64encode(resized_image).decode('utf-8')
Gemma was developed from the same research and technology used to create the company’s Gemini models and is built for responsibleAI development. With CLIP support in ChatRTX, users can interact with photos and images on their local devices through words, terms and phrases, without the need for complex metadata labeling.
Designed with responsibleAI and data privacy in mind, Jupyter AI empowers users to choose their preferred LLM, embedding model, and vector database to suit their specific needs. Moreover, it saves metadata about model-generated content, facilitating tracking of AI-generated code within the workflow.
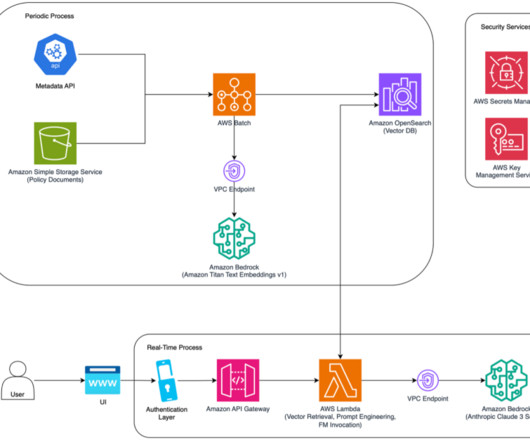
Set up the policy documents and metadata in the data source for the knowledge base We use Amazon Bedrock Knowledge Bases to manage our documents and metadata. Upload a few insurance policy documents and metadata documents to the S3 bucket to mimic the naming conventions as shown in the following screenshot.
The embedding representations of text chunks along with related metadata are indexed in OpenSearch Service. In this step, the user asks a question about the ingested documents and expects a response in natural language. The application uses Amazon Textract to get the text and tables from the input documents.
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. Today, generative AI can help bridge this knowledge gap for nontechnical users to generate SQL queries by using a text-to-SQL application. The FM generates the SQL query based on the final input.
Twilio’s use case Twilio wanted to provide an AI assistant to help their data analysts find data in their data lake. They used the metadata layer (schema information) over their data lake consisting of views (tables) and models (relationships) from their data reporting tool, Looker , as the source of truth.
By investing in robust evaluation practices, companies can maximize the benefits of LLMs while maintaining responsibleAI implementation and minimizing potential drawbacks. To support robust generative AI application development, its essential to keep track of models, prompt templates, and datasets used throughout the process.
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Can you compare images?
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsibleAI.
You then format these pairs as individual text files with corresponding metadata JSON files , upload them to an S3 bucket, and ingest them into your cache knowledge base.
Evolving Trends in Prompt Engineering for Large Language Models (LLMs) with Built-in ResponsibleAI Practices Editor’s note: Jayachandran Ramachandran and Rohit Sroch are speakers for ODSC APAC this August 22–23. As LLMs become integral to AI applications, ethical considerations take center stage.
structured: | Process the pdf invoice and list all metadata and values in json format for the variables with descriptions in tags. In this post, we provide a step-by-step guide with the building blocks needed for creating a Streamlit application to process and review invoices from multiple vendors.
This layer serves as the cornerstone for secure, compliant, and agile consumption of FMs through the Generative AI Gateway, promoting responsibleAI practices within the organization. This table will hold the endpoint, metadata, and configuration parameters for the model.
Manifest relies on runtime metadata, such as a function’s name, docstring, arguments, and type hints. It uses this metadata to compose a prompt and sends it to an LLM. Feedback Loops in Generative AI: How AI May Shoot Itself in the Foot by Anthony Demeusy Generative AI can enhance creativity, but beware of feedback loops!
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsibleAI.
The MOF defines 17 essential components for model openness, including datasets, data preprocessing code, model architecture, trained model parameters, metadata, training, inference code, evaluation code, data, supporting libraries, and tools.
It’s a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like Anthropic, Cohere, Meta, Mistral AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsibleAI.
Finding relevant content usually requires searching through text-based metadata such as timestamps, which need to be manually added to these files. For example, for the S3 object AI-Accelerators.json, we tag it with key = “title” and value = “Episode 20: AI Accelerators in the Cloud.”
This blog post outlines various use cases where we’re using generative AI to address digital publishing challenges. However, when the article is complete, supporting information and metadata must be defined, such as an article summary, categories, tags, and related articles.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content