

Evolving Trends in Prompt Engineering for Large Language Models (LLMs) with Built-in Responsible AI…
ODSC - Open Data Science
AUGUST 24, 2023
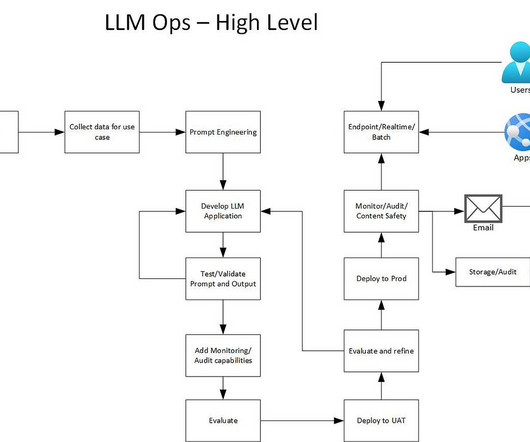
Evolving Trends in Prompt Engineering for Large Language Models (LLMs) with Built-in Responsible AI Practices Editor’s note: Jayachandran Ramachandran and Rohit Sroch are speakers for ODSC APAC this August 22–23. As LLMs become integral to AI applications, ethical considerations take center stage.










Let's personalize your content