This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
If you're looking to implement Automatic Speech Recognition (ASR) in Python, you may have noticed that there is a wide array of available options. Broadly, Python speech recognition and Speech-to-Text solutions can be categorized into two main types: open-source libraries and cloud-based services. What is Speech Recognition?
In addition to natural language reasoning steps, the model generates python syntax that is then executed in order to output the final answer. Additive embeddings are used for representing metadata about each note. Applying NLP systems to analyse thousands of company reports and the sustainability initiatives described in those reports.
On the other hand, a Node is a snippet or “chunk” from a Document, enriched with metadata and relationships to other nodes, ensuring a robust foundation for precise data retrieval later on. Behind the scenes, it dissects raw documents into intermediate representations, computes vector embeddings, and deduces metadata.
It allows for very fast similarity search, essential for many AI uses such as recommendation systems, picture recognition, and NLP. Chroma can be used to create word embeddings using Python or JavaScript programming. Each referenced string can have extra metadata that describes the original document.
How to save a trained model in Python? Saving trained model with pickle The pickle module can be used to serialize and deserialize the Python objects. For saving the ML models used as a pickle file, you need to use the Pickle module that already comes with the default Python installation. Now let’s see how we can save our model.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. This generative AI task is called text-to-SQL, which generates SQL queries from natural language processing (NLP) and converts text into semantically correct SQL. Today, generative AI can enable people without SQL knowledge.
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. With multiple families in plan, the first release is the Slate family of models, which represent an encoder-only architecture. To bridge the tuning gap, watsonx.ai
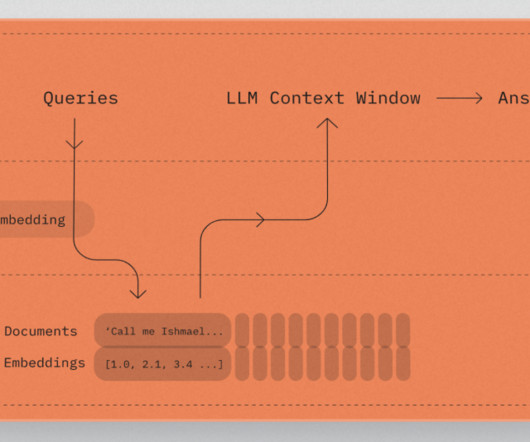
This method of enriching the LLM generation context with information retrieved from your internal data sources is called Retrieval Augmented Generation (RAG), and produces assistants that are domain specific and more trustworthy, as shown by Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
Word embeddings are considered as a type of representation used in natural language processing (NLP) to capture the meaning of words in a numerical form. Word embeddings are used in natural language processing (NLP) as a technique to represent words in a numerical format.
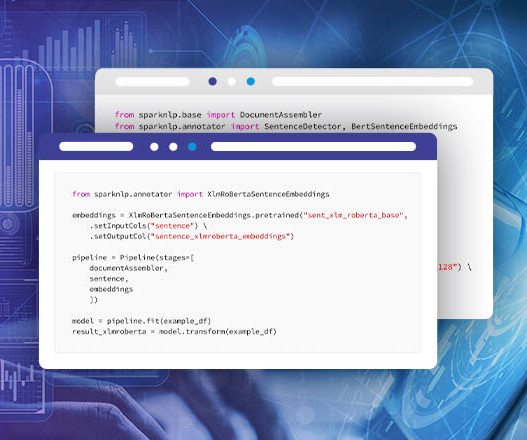
Sentence detection in Spark NLP is the process of identifying and segmenting a piece of text into individual sentences using the Spark NLP library. Sentence Detection in Spark NLP is the process of automatically identifying the boundaries of sentences in a given text.
The Normalizer annotator in Spark NLP performs text normalization on data. The Normalizer annotator in Spark NLP is often used as part of a preprocessing step in NLP pipelines to improve the accuracy and quality of downstream analyses and models. These transformations can be configured by the user to meet their specific needs.
Rule-based sentiment analysis in Natural Language Processing (NLP) is a method of sentiment analysis that uses a set of manually-defined rules to identify and extract subjective information from text data. Using Spark NLP, it is possible to analyze the sentiment in a text with high accuracy.
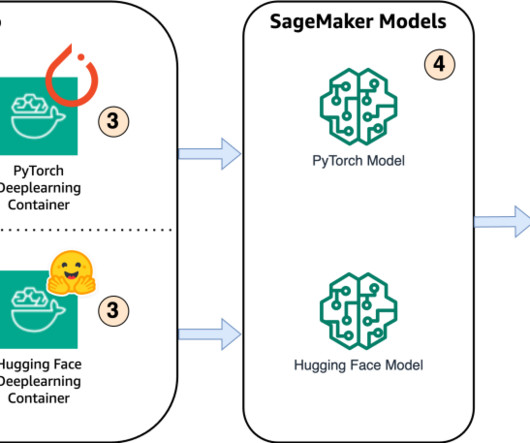
When selecting the Docker image, consider the following settings: framework (Hugging Face), task (inference), Python version, and hardware (for example, GPU). For other required Python packages, create a requirements.txt file with a list of packages and their versions. __dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir":
Stopwords removal in natural language processing (NLP) is the process of eliminating words that occur frequently in a language but carry little or no meaning. Stopwords cleaning in Spark NLP is the process of removing stopwords from the text data. Stopwords are commonly occurring words (like the, a, and, in , etc.)
They can include model parameters, configuration files, pre-processing components, as well as metadata, such as version details, authorship, and any notes related to its performance. Additionally, you can list the required Python packages in a requirements.txt file. This is also where we can incorporate custom parameters as needed.
In this article, we will discuss the use of Clinical NLP in understanding the rich meaning that lies behind the doctor’s written analysis (clinical documents/notes) of patients. Contextualization – It is very important for a clinical NLP system to understand the context of what a doctor is writing about. family members).
Let’s start with a brief introduction to Spark NLP and then discuss the details of pretrained pipelines with some concrete results. Spark NLP & LLM The Healthcare Library is a powerful component of John Snow Labs’ Spark NLP platform, designed to facilitate NLP tasks within the healthcare domain. word embeddings).
Sentence embeddings with Transformers are a powerful natural language processing (NLP) technique that use deep learning models known as Transformers to encode sentences into fixed-length vectors that can be used for a variety of NLP tasks. Introduction to Spark NLP Spark NLP is an open-source library maintained by John Snow Labs.
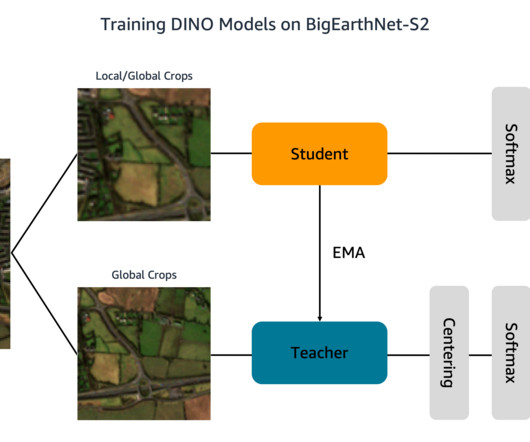
Additionally, each folder contains a JSON file with the image metadata. To perform statistical analyses of the data and load images during DINO training, we process the individual metadata files into a common geopandas Parquet file. We store the BigEarthNet-S2 images and metadata file in an S3 bucket. tif" --include "_B03.tif"
Prerequisites To start experimenting with Selective Execution, we need to first set up the following components of your SageMaker environment: SageMaker Python SDK – Ensure that you have an updated SageMaker Python SDK installed in your Python environment. or higher: python3 -m pip install sagemaker>=2.162.0
Prerequisite libraries: SageMaker Python SDK, Pinecone Client Solution Walkthrough Using SageMaker Studio notebook, we first need install prerequisite libraries: !pip Since we top_k = 1 , index.query returned the top result along side the metadata which reads Managed Spot Training can be used with all instances supported in Amazon.
Many different transformer models have already been implemented in Spark NLP, and specifically for text classification, Spark NLP provides various annotators that are designed to work with pretrained language models. The table shows the language models and the corresponding annotators for text classification provided by Spark NLP.
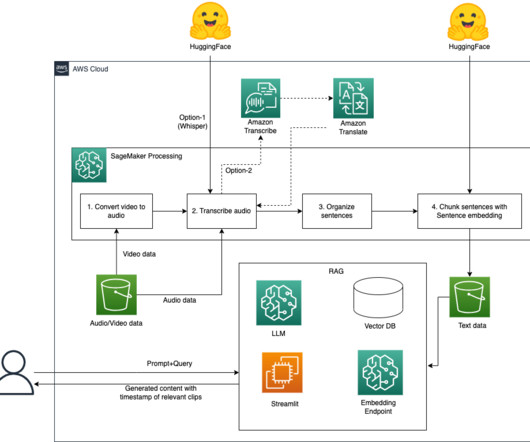
Unlike traditional natural language processing (NLP) approaches, such as classification methods, LLMs offer greater flexibility in adapting to dynamically changing categories and improved accuracy by using pre-trained knowledge embedded within the model. The following diagram illustrates the architecture and workflow of the proposed solution.
You can change the response for the models in the following way: ==baseline You can reverse a list in Python using the built-in `reverse()` method or slicing. You can reverse a list in Python using the built-in reverse() method or slicing. You can use the reverse method to reverse a list in Python. Here's how you can do it [.]
Install the required Python packages. The following Python packages are needed for this two-step conversion: tabulate toml torch sentencepiece==0.1.95 as_onnx_model(onnx_path, force_overwrite=False) return onnx_path, metadata def onnx2trt(onnx_path, metadata): trt_path = 'Your own path to save TensorRT-based model' # e.g.,/model_fp16.onnx.engine
Spark NLP’s deep learning models have achieved state-of-the-art results on sentiment analysis tasks, thanks to their ability to automatically learn features and representations from raw text data. Spark NLP has multiple approaches for detecting the sentiment (which is actually a text classification problem) in a text.
The postprocessing component uses bounding box metadata from Amazon Textract for intelligent data extraction. The Apache Tika open-source Python library is used for data extraction from word documents. Amazon DynamoDB is used for storing document metadata and keeping track of the document processing status across all key components.
These embeddings represent textual and visual data in a numerical format, which is essential for various natural language processing (NLP) tasks. For tables, the system retrieves relevant table locations and metadata, and computes the cosine similarity between the multimodal embedding and the vectors representing the table and its summary.
Using machine learning (ML) and natural language processing (NLP) to automate product description generation has the potential to save manual effort and transform the way ecommerce platforms operate. First, launch the notebook main.ipynb in SageMaker Studio by selecting the Image as Data Science and Kernel as Python 3.
Unlike traditional NLP models which rely on rules and annotations, LLMs like GPT-3 learn language skills in an unsupervised, self-supervised manner by predicting masked words in sentences. Their foundational nature allows them to be fine-tuned for a wide variety of downstream NLP tasks. This enables pretraining at scale.
Large language models (LLMs) have achieved remarkable success in various natural language processing (NLP) tasks, but they may not always generalize well to specific domains or tasks. You also need to add the mlflow and sagemaker-mlflow Python packages as dependencies in the pipeline setup.
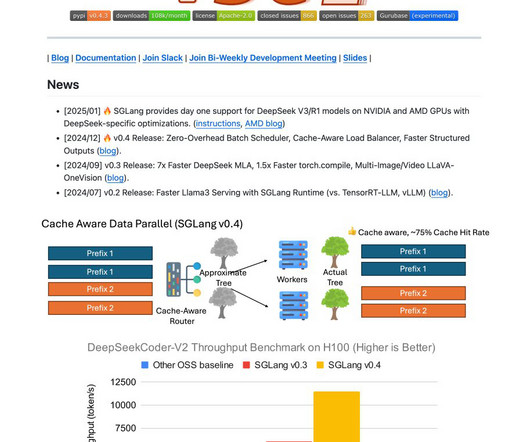
The scheduler keeps the GPUs continuously engaged by running one batch ahead and preparing all necessary metadata for the next batch. For example, ByteDance channels a large portion of its internal NLP pipelines through this engine, processing petabytes of data daily. SGLang is released under the Apache 2.0
Sentiment analysis and other natural language programming (NLP) tasks often start out with pre-trained NLP models and implement fine-tuning of the hyperparameters to adjust the model to changes in the environment. script, you likely need to run a Python job to preprocess the data. Visualize results on the W&B platform.
Using the LLM SDK to Log Prompts and Responses The LLM SDK supports logging prompts with its associated response and any associated metadata like token usage. metadata : Dict[str, Union[str, bool, float, None]] (optional) user-defined dictionary with additional metadata to the call. Logging full prompt and response.
Traditionally, companies attach metadata, such as keywords, titles, and descriptions, to these digital assets to facilitate search and retrieval of relevant content. In reality, most of the digital assets lack informative metadata that enables efficient content search. This is time consuming and requires a lot of manual effort.
Streamlining Unstructured Data for Retrieval Augmented Generatio n Matt Robinson | Open Source Tech Lead | Unstructured Learn about the complexities of handling unstructured data, and practical strategies for extracting usable text and metadata from it. You’ll also discuss loading processed data into destination storage.
To address the need for multiple steps in the inference logic, Forethought developed a Triton ensemble model with two steps: a Python backend preprocessing process and a PyTorch backend model call. He focuses on Deep learning including NLP and Computer Vision domains. To address this, we tried using ml.g4dn.2xlarge
Refer to our GitHub repository for detailed Python notebooks and a step-by-step walkthrough. Amazon Comprehend is a natural language processing (NLP) service that uses ML to extract insights from text. It acts as a knowledge source that aides NLP tasks in document processing pipelines.
Retailers can deliver more frictionless experiences on the go with natural language processing (NLP), real-time recommendation systems, and fraud detection. script to retrieve the JumpStart model artifacts and deploy the pre-trained model to your local machine: python train_model.py Run the train_model.py sourcedir.tar.gz
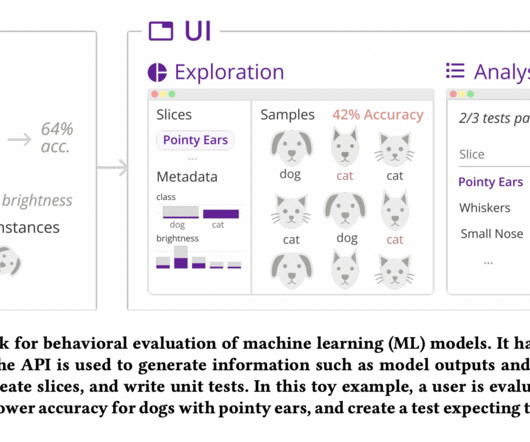
For instance, they could fail to embed fundamental capabilities like accurate grammar in NLP systems or cover up systemic flaws like societal prejudices. Zeno consists of a Python application programming interface (API) and a graphical user interface (GUI) (UI). Zeno is made available to the public via a Python script.
The preparation of a natural language processing (NLP) dataset abounds with share-nothing parallelism opportunities. FSx for Lustre uses distributed file storage (stripping) and physically separates file metadata from file content to achieve high-performance read/writes. This reduces iteration time and inter-job placement variability.
Taipy The inspiration for this open-source software for Python developers was the frustration felt by those who were trying, and struggling, to bring AI algorithms to end-users. Narrowing the communications gap between humans and machines is one of SAS’s leading projects in their work with NLP.
LLMs, like Llama2, have shown state-of-the-art performance on natural language processing (NLP) tasks when fine-tuned on domain-specific data. Python 3.10 He previously worked in the semiconductor industry developing large computer vision (CV) and natural language processing (NLP) models to improve semiconductor processes.
Such tasks include image recognition , video analytics , generative AI, voice recognition, text recognition, and NLP. The name “Jupyter” is a reference to the three core programming languages supported by Jupyter: Julia, Python, and R. The strategic importance of AI technology is growing exponentially across industries.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content