This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One effective way to improve context relevance is through metadata filtering, which allows you to refine search results by pre-filtering the vector store based on custom metadata attributes. By combining the capabilities of LLM function calling and Pydantic data models, you can dynamically extract metadata from user queries.
One of these strategies is using Amazon Simple Storage Service (Amazon S3) folder structures and Amazon Bedrock Knowledge Bases metadata filtering to enable efficient data segmentation within a single knowledge base. The S3 bucket, containing customer data and metadata, is configured as a knowledge base data source.
Despite advances in image and text-based AI research, the audio domain lags due to the absence of comprehensive datasets comparable to those available for computer vision or naturallanguageprocessing. The alignment of metadata to each audio clip provides valuable contextual information, facilitating more effective learning.
Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB. This extracted text is then available for further analysis and the creation of metadata, adding layout-based structure and meaning to the raw data.
This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata. Generate metadata for the page. Generate metadata for the full document. Upload the content and metadata to Amazon S3.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
The Process Data Lambda function redacts sensitive data through Amazon Comprehend. Amazon Comprehend provides real-time APIs, such as DetectPiiEntities and DetectEntities , which use naturallanguageprocessing (NLP) machine learning (ML) models to identify text portions for redaction.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
This new capability integrates the power of graph data modeling with advanced naturallanguageprocessing (NLP). You can also supply a custom metadata file (each up to 10 KB) for each document in the knowledge base. More specifically, the graph created will connect chunks to documents, and entities to chunks.
This approach has two primary shortcomings: Missed Contextual Signals : Without considering metadata such as source URLs, LMs overlook important contextual information that could guide their understanding of a texts intent or quality. Addressing these inefficiencies is essential for developing more effective and versatile language models.
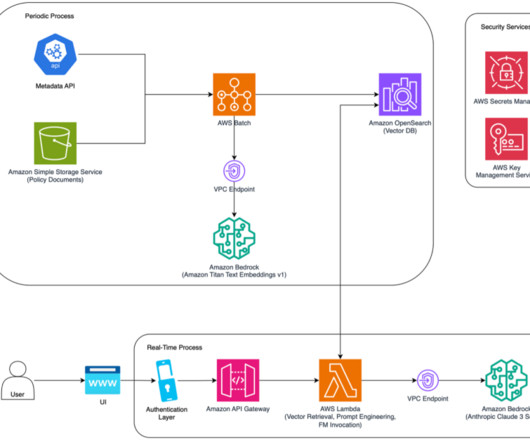
Along with each document slice, we store the metadata associated with it using an internal Metadata API, which provides document characteristics like document type, jurisdiction, version number, and effective dates. This process has been implemented as a periodic job to keep the vector database updated with new documents.
It stores models, organizes model versions, captures essential metadata and artifacts such as container images, and governs the approval status of each model. She has expertise in Machine Learning, covering naturallanguageprocessing, computer vision, and time-series analysis.
They are crucial for machine learning applications, particularly those involving naturallanguageprocessing and image recognition. Often support for metadata filtering alongside vector search Popular vector databases include FAISS (Facebook AI Similarity Search), Pinecone, Weaviate, Milvus, and Chroma.
Solution overview Data and metadata discovery is one of the primary requirements in data analytics, where data consumers explore what data is available and in what format, and then consume or query it for analysis. But in the case of unstructured data, metadata discovery is challenging because the raw data isn’t easily readable.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. It automates capturing model metadata and increases predictive accuracy to identify how AI tools are used and where model training needs to be done again. Track models and drive transparent processes.
A significant challenge with question-answering (QA) systems in NaturalLanguageProcessing (NLP) is their performance in scenarios involving extensive collections of documents that are structurally similar or ‘indistinguishable.’
Customers can use Amazon Bedrock Data Automation to support popular media analysis use cases such as: Digital asset management: in the M&E industry, digital asset management (DAM) refers to the organized storage, retrieval, and management of digital content such as videos, images, audio files, and metadata.
Generative AI uses an advanced form of machine learning algorithms that takes users prompts and uses naturallanguageprocessing (NLP) to generate answers to almost any question asked. Automatic capture of model metadata and facts provide audit support while driving transparent and explainable model outcomes.
Self-supervised learning has already shown its results in NaturalLanguageProcessing as it has allowed developers to train large models that can work with an enormous amount of data, and has led to several breakthroughs in fields of naturallanguage inference, machine translation, and question answering.
Third, the NLP Preset is capable of combining tabular data with NLP or NaturalLanguageProcessing tools including pre-trained deep learning models and specific feature extractors. Next, the LightAutoML inner datasets contain CV iterators and metadata that implement validation schemes for the datasets.
In this article, we will discuss the top Text Annotation tools for NaturalLanguageProcessing along with their characteristic features. Overview of Text Annotation Human language is highly diverse and is sometimes hard to decode for machines. It annotates images, videos, text documents, audio, and HTML, etc.
Alongside his professional role, he is pursuing a PhD in Machine Learning Engineering at the University of Regensburg, where his research focuses on applied naturallanguageprocessing in scientific domains.
Previously, you had a choice between human-based model evaluation and automatic evaluation with exact string matching and other traditional naturallanguageprocessing (NLP) metrics. This includes watermarking, content moderation, and C2PA support (available in Amazon Nova Canvas) to add metadata by default to generated images.
However, as technology advanced, so did the complexity and capabilities of AI music generators, paving the way for deep learning and NaturalLanguageProcessing (NLP) to play pivotal roles in this tech. Initially, the attempts were simple and intuitive, with basic algorithms creating monotonous tunes.
It uses metadata and data management tools to organize all data assets within your organization. An enterprise data catalog automates the process of contextualizing data assets by using: Business metadata to describe an asset’s content and purpose. Technical metadata to describe schemas, indexes and other database objects.
Can you explain how HeavyIQ leverages naturallanguageprocessing to facilitate data exploration and visualization? IQ is about making data exploration and visualization as intuitive as possible by using naturallanguageprocessing (NLP). This includes not only data but also several kinds of metadata.
This lack of resources leads to AI models that better understand and process English than other languages in tasks like recognition, machine translation, and other naturallanguageprocessing tasks.
Artificial Intelligence is a very vast branch in itself with numerous subfields including deep learning, computer vision , naturallanguageprocessing , and more.
In addition, the Amazon Bedrock Knowledge Bases team worked closely with us to address several critical elements, including expanding embedding limits, managing the metadata limit (250 characters), testing different chunking methods, and syncing throughput to the knowledge base.
First, you extract label and celebrity metadata from the images, using Amazon Rekognition. You then generate an embedding of the metadata using a LLM. You store the celebrity names, and the embedding of the metadata in OpenSearch Service. Overview of solution The solution is divided into two main sections.
Advanced parsing Advanced parsing is the process of analyzing and extracting meaningful information from unstructured or semi-structured documents. It involves breaking down the document into its constituent parts, such as text, tables, images, and metadata, and identifying the relationships between these elements.
In NaturalLanguageProcessing (NLP) tasks, data cleaning is an essential step before tokenization, particularly when working with text data that contains unusual word separations such as underscores, slashes, or other symbols in place of spaces.
You then format these pairs as individual text files with corresponding metadata JSON files , upload them to an S3 bucket, and ingest them into your cache knowledge base.
Scientific metadata in research literature holds immense significance, as highlighted by flourishing research in scientometricsa discipline dedicated to analyzing scholarly literature. Metadata improves the findability and accessibility of scientific documents by indexing and linking papers in a massive graph.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. This generative AI task is called text-to-SQL, which generates SQL queries from naturallanguageprocessing (NLP) and converts text into semantically correct SQL. We use Anthropic Claude v2.1
Large language models (LLMs) are revolutionizing fields like search engines, naturallanguageprocessing (NLP), healthcare, robotics, and code generation. A media metadata store keeps the promotion movie list up to date. A feature store maintains user profile data.
This allows users to accomplish different NaturalLanguageProcessing (NLP) functional tasks and take advantage of IBM vetted pre-trained open-source foundation models. Encoder-decoder and decoder-only large language models are available in the Prompt Lab today. To bridge the tuning gap, watsonx.ai
You can use metadata filtering to narrow down search results by specifying inclusion and exclusion criteria. She leads machine learning projects in various domains such as computer vision, naturallanguageprocessing, and generative AI. In her free time, she likes to go for long runs along the beach.
Participants learn to build metadata for documents containing text and images, retrieve relevant text chunks, and print citations using Multimodal RAG with Gemini. NaturalLanguageProcessing on Google Cloud This course introduces Google Cloud products and solutions for solving NLP problems.
Using naturallanguageprocessing (NLP) and OpenAPI specs, Amazon Bedrock Agents dynamically manages API sequences, minimizing dependency management complexities. Set up the policy documents and metadata in the data source for the knowledge base We use Amazon Bedrock Knowledge Bases to manage our documents and metadata.
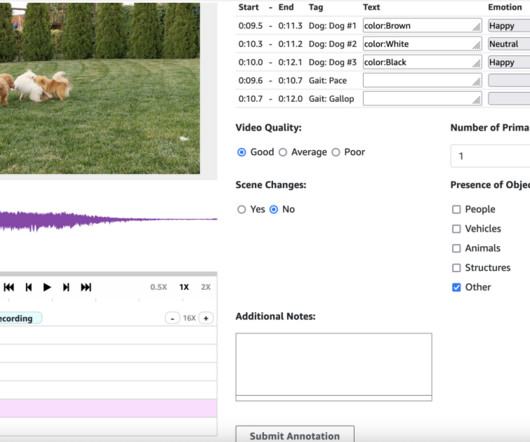
We start with a simple scenario: you have an audio file stored in Amazon S3, along with some metadata like a call ID and its transcription. What feature would you like to see added ? " } You can adapt this structure to include additional metadata that your annotation workflow requires.
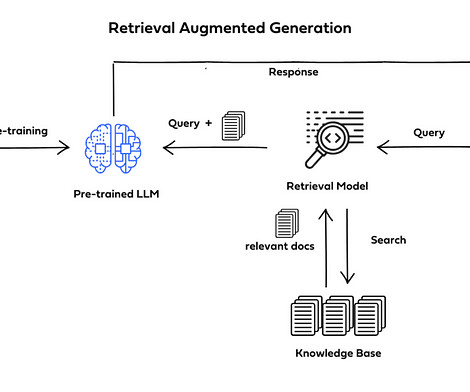
Retrieval-Augmented Generation (RAG) is a cutting-edge method of naturallanguageprocessing that produces precise and contextually relevant answers by fusing the strength of large language models (LLMs) with an external knowledge retrieval system. _pages_and_chunks( pages_and_texts ) # Create chunks with metadata.
AI content detectors use a combination of machine learning (ML), naturallanguageprocessing (NLP), and pattern recognition techniques to differentiate AI-generated content from human-generated content. These markers, such as sentence embeddings, hash functions, or metadata tags, help AI detectors spot machine-generated content.
By understanding its significance, readers can grasp how it empowers advancements in AI and contributes to cutting-edge innovation in naturallanguageprocessing. By incorporating metadata tagging and maintaining a transparent development process, the dataset promotes both usability and adaptability for cutting-edge AI research.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content