This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
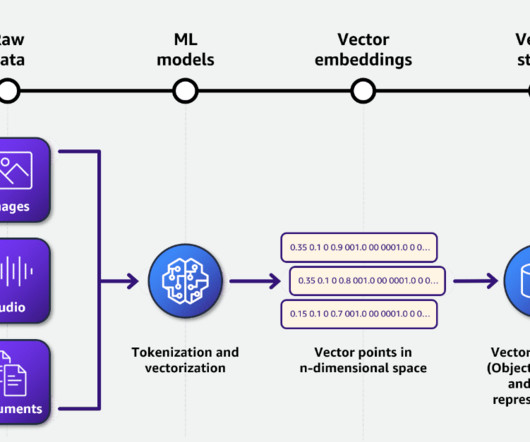
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
When building machine learning (ML) models using preexisting datasets, experts in the field must first familiarize themselves with the data, decipher its structure, and determine which subset to use as features. So much so that a basic barrier, the great range of data formats, is slowing advancement in ML.
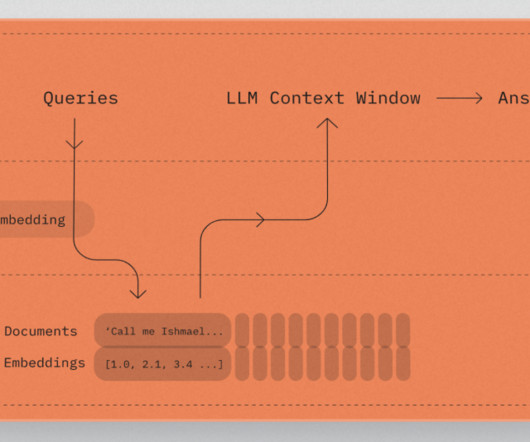
With metadata filtering now available in Knowledge Bases for Amazon Bedrock, you can define and use metadata fields to filter the source data used for retrieving relevant context during RAG. Metadata filtering gives you more control over the RAG process for better results tailored to your specific use case needs.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services. However, some components may incur additional usage-based costs.
Whether youre new to Gradio or looking to expand your machine learning (ML) toolkit, this guide will equip you to create versatile and impactful applications. Gradio is an open-source Python library that enables developers to create user-friendly and interactive web applications effortlessly. and the Ollama API, just keep reading.
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for Data Science and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for data scientists and machine learning (ML) engineers.
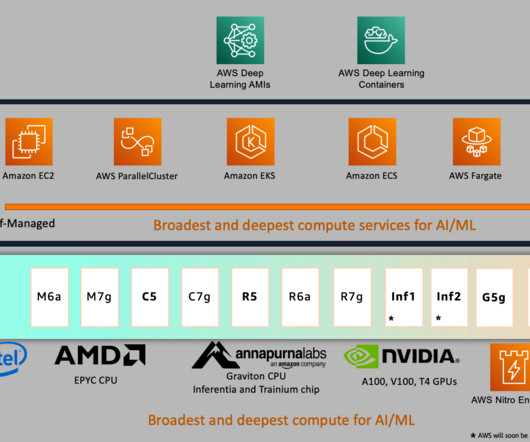
Real-world applications vary in inference requirements for their artificial intelligence and machine learning (AI/ML) solutions to optimize performance and reduce costs. SageMaker Model Monitor monitors the quality of SageMaker ML models in production. Your client applications invoke this endpoint to get inferences from the model.
When working on real-world machine learning (ML) use cases, finding the best algorithm/model is not the end of your responsibilities. Reusability & reproducibility: Building ML models is time-consuming by nature. Save vs package vs store ML models Although all these terms look similar, they are not the same.
We add the following to the end of the prompt: provide the response in json format with the key as “class” and the value as the class of the document We get the following response: { "class": "ID" } You can now read the JSON response using a library of your choice, such as the Python JSON library. The following image is of a gearbox.
This engine uses artificial intelligence (AI) and machine learning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call. This post provides guidance on how you can create a video insights and summarization engine using AWS AI/ML services.
Discover how metadata, the hidden gem of your knowledge base, can be transformed into a powerful tool for enriching your RAG pipeline and… Continue reading on MLearning.ai »
Researchers at the Allen Institute for AI introduced olmOCR , an open-source Python toolkit designed to efficiently convert PDFs into structured plain text while preserving logical reading order. Image Source The core innovation behind olmOCR is document anchoring, a technique that combines textual metadata with image-based analysis.
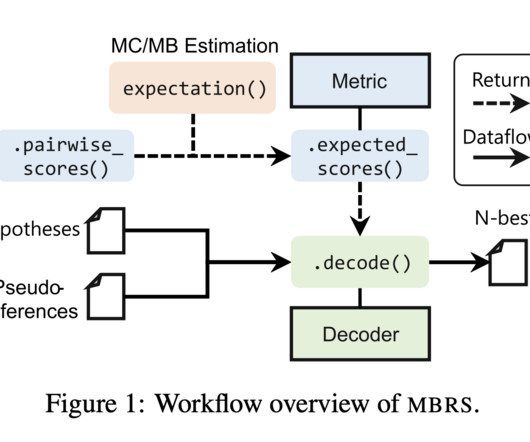
The MBRS library is implemented primarily in Python and PyTorch and offers several key features. Additionally, MBRS provides metadata analysis capabilities, allowing users to analyze the origins of output texts and visualize the decision-making process of MBR decoding. If you like our work, you will love our newsletter.
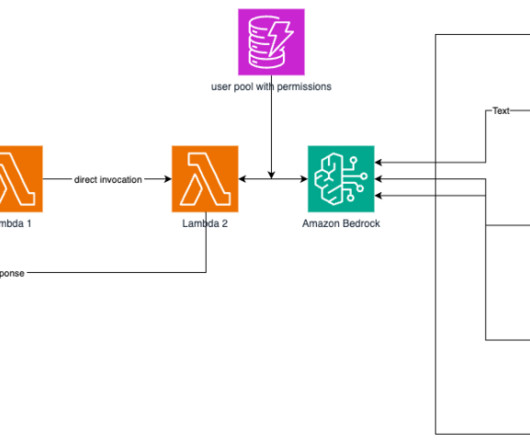
In this post, we show you how to convert Python code that fine-tunes a generative AI model in Amazon Bedrock from local files to a reusable workflow using Amazon SageMaker Pipelines decorators. You can use Amazon SageMaker Model Building Pipelines to collaborate between multiple AI/ML teams.
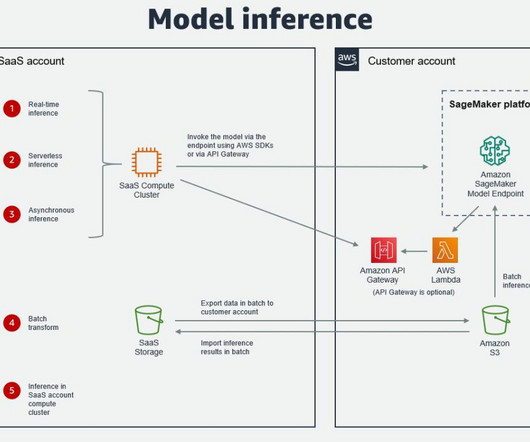
Many organizations choose SageMaker as their ML platform because it provides a common set of tools for developers and data scientists. There are a few different ways in which authentication across AWS accounts can be achieved when data in the SaaS platform is accessed from SageMaker and when the ML model is invoked from the SaaS platform.
aws sagemaker create-cluster --cli-input-json file://cluster-config.json --region $AWS_REGION You should be able to see your cluster by navigating to SageMaker Hyperpod in the AWS Management Console and see a cluster named ml-cluster listed. Step 1: Environment setup You first need to install the required Python packages for fine tuning.
Chroma can be used to create word embeddings using Python or JavaScript programming. Each referenced string can have extra metadata that describes the original document. Researchers fabricated some metadata to use in the tutorial. Metadata (or IDs) can also be queried in the Chroma database.
FMEval is an open source LLM evaluation library, designed to provide data scientists and machine learning (ML) engineers with a code-first experience to evaluate LLMs for various aspects, including accuracy, toxicity, fairness, robustness, and efficiency. This allows you to keep track of your ML experiments.
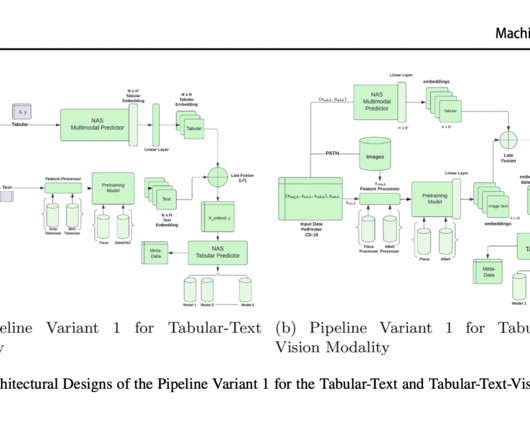
An improvement in AutoML for dealing with complicated data modalities, including tabular-text, text-vision, and vision-text-tabular configurations, the proposed method simplifies and guarantees the efficiency and adaptability of multimodal ML pipelines. This collection was chosen after the pipeline variants had been designed.
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. Embedding is usually performed by a machine learning (ML) model. Streamlit This open source Python library makes it straightforward to create and share beautiful, custom web apps for ML and data science.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computer vision and natural language processing. One of the primary reasons that customers are choosing a PyTorch framework is its simplicity and the fact that it’s designed and assembled to work with Python.
Amazon Personalize makes it straightforward to personalize your website, app, emails, and more, using the same machine learning (ML) technology used by Amazon, without requiring ML expertise. If you use Amazon Personalize with generative AI, you can also feed the metadata into prompts. compared to previous versions.
Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve. For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc.,
Our commitment to innovation led us to a pivotal challenge: how to harness the power of machine learning (ML) to further enhance our competitive edge while balancing this technological advancement with strict data security requirements and the need to streamline access to our existing internal resources.
In addition, 3FS incorporates stateless metadata services that are supported by a transactional key-value store, such as FoundationDB. By decoupling metadata management from the storage layer, the system not only becomes more scalable but also reduces potential bottlenecks related to metadata operations.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Third, despite the larger adoption of centralized analytics solutions like data lakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources.
Veritone’s current media search and retrieval system relies on keyword matching of metadata generated from ML services, including information related to faces, sentiment, and objects. We use the Amazon Titan Text and Multimodal Embeddings models to embed the metadata and the video frames and index them in OpenSearch Service.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. IBM watsonx.ai With watsonx.ai, businesses can effectively train, validate, tune and deploy AI models with confidence and at scale across their enterprise.
In this comprehensive guide, we’ll explore the key concepts, challenges, and best practices for ML model packaging, including the different types of packaging formats, techniques, and frameworks. Best practices for ml model packaging Here is how you can package a model efficiently. What is model packaging in machine learning?
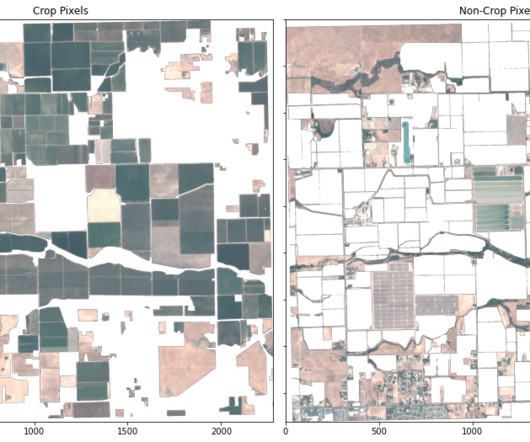
In this post, we illustrate how to use a segmentation machine learning (ML) model to identify crop and non-crop regions in an image. Identifying crop regions is a core step towards gaining agricultural insights, and the combination of rich geospatial data and ML can lead to insights that drive decisions and actions.
In this post, we discuss how the IEO developed UNDP’s artificial intelligence and machine learning (ML) platform—named Artificial Intelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
Second, because data, code, and other development artifacts like machine learning (ML) models are stored within different services, it can be cumbersome for users to understand how they interact with each other and make changes. Data and AI governance Publish your data products to the catalog with glossaries and metadata forms.
PyTorch is a machine learning (ML) framework that is widely used by AWS customers for a variety of applications, such as computer vision, natural language processing, content creation, and more. Our next generation release that is faster, more Pythonic and Dynamic as ever for details. With the recent PyTorch 2.0 Refer to PyTorch 2.0:
TL;DR Using CI/CD workflows to run ML experiments ensures their reproducibility, as all the required information has to be contained under version control. The compute resources offered by GitHub Actions directly are not suitable for larger-scale ML workloads. ML experiments are, by nature, full of uncertainty and surprises.
In Part 2 , we demonstrated how to use Amazon Neptune ML (in Amazon SageMaker ) to train the KG and create KG embeddings. This mapping can be done by manually mapping frequent OOC queries to catalog content or can be automated using machine learning (ML). Creates an OpenSearch Service domain for the search application.
Amazon SageMaker Serverless Inference is a purpose-built inference service that makes it easy to deploy and scale machine learning (ML) models. Data overview and preparation You can use a SageMaker Studio notebook with a Python 3 (Data Science) kernel to run the sample code. We use the first metadata file in this demo.
Astral, a company renowned for its high-performance developer tools in the Python ecosystem, has recently released uv: Unified Python packaging , a comprehensive tool designed to streamline Python package management. Developers can now use uv to generate and install cross-platform lockfiles based on standards-compliant metadata.
There was no mechanism to pass and store the metadata of the multiple experiments done on the model. We could re-use the previous Sagemaker Python SDK code to run the modules individually into Sagemaker Pipeline SDK based runs.
The search precision can also be improved with metadata filtering. To overcome these limitations, we propose a solution that combines RAG with metadata and entity extraction, SQL querying, and LLM agents, as described in the following sections. We use the following Python script to recreate tables as pandas DataFrames.
Featured Community post from the Discord Arwmoffat just released Manifest, a tool that lets you write a Python function and have an LLM execute it. Manifest relies on runtime metadata, such as a function’s name, docstring, arguments, and type hints. It uses this metadata to compose a prompt and sends it to an LLM.
CaMeL further strengthens security by assigning metadata or “capabilities” to each data value, defining strict policies about how each piece of information can be utilized. Also,feel free to follow us on Twitter and dont forget to join our 85k+ ML SubReddit. increase in input tokens and a 2.73 Check out the Paper.
This setup uses the AWS SDK for Python (Boto3) to interact with AWS services. You then format these pairs as individual text files with corresponding metadata JSON files , upload them to an S3 bucket, and ingest them into your cache knowledge base.
An example of “Conflicting attributes in the base class” query In Python, when a class subclasses multiple base classes, attribute lookup is performed from left to right amongst the base classes following a method called “method resolution order.”¹ CodeQueries has 52 public CodeQL queries python source code files from a common corpus³.
In this post, we discuss deploying scalable machine learning (ML) models for diarizing media content using Amazon SageMaker , with a focus on the WhisperX model. When selecting the Docker image, consider the following settings: framework (Hugging Face), task (inference), Python version, and hardware (for example, GPU).
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content