

Search enterprise data assets using LLMs backed by knowledge graphs
NOVEMBER 27, 2024
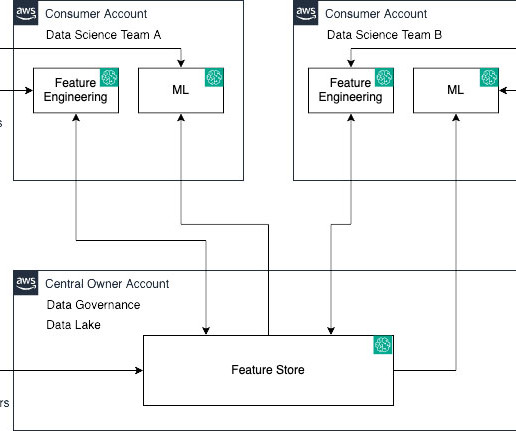
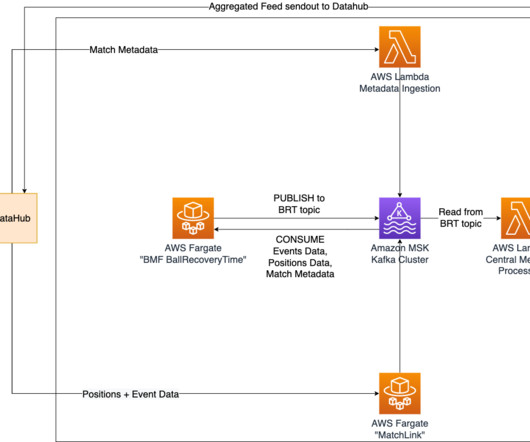
The application needs to search through the catalog and show the metadata information related to all of the data assets that are relevant to the search context. The following diagram illustrates the end-to-end architecture, consisting of the metadata API layer, ingestion pipeline, embedding generation workflow, and frontend UI.










































Let's personalize your content