This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
You can use this framework as a starting point to monitor your custom metrics or handle other unique requirements for model quality monitoring in your AI/ML applications. Data Scientist at AWS, bringing a breadth of data science, MLengineering, MLOps, and AI/ML architecting to help businesses create scalable solutions on AWS.
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for Data Science and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for data scientists and machine learning (ML) engineers.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Third, despite the larger adoption of centralized analytics solutions like data lakes and warehouses, complexity rises with different table names and other metadata that is required to create the SQL for the desired sources.
Data preparation isn’t just a part of the MLengineering process — it’s the heart of it. This step, often done with data engineers, ensures a reproducible data snapshot from sources like production databases or APIs. This member-only story is on us. Upgrade to access all of Medium.
In this post, we introduce an example to help DevOps engineers manage the entire ML lifecycle—including training and inference—using the same toolkit. Solution overview We consider a use case in which an MLengineer configures a SageMaker model building pipeline using a Jupyter notebook.
FMEval is an open source LLM evaluation library, designed to provide data scientists and machine learning (ML) engineers with a code-first experience to evaluate LLMs for various aspects, including accuracy, toxicity, fairness, robustness, and efficiency. This allows you to keep track of your ML experiments.
Introduction to AI and Machine Learning on Google Cloud This course introduces Google Cloud’s AI and ML offerings for predictive and generative projects, covering technologies, products, and tools across the data-to-AI lifecycle.
Machine learning (ML) engineers must make trade-offs and prioritize the most important factors for their specific use case and business requirements. You can use metadata filtering to narrow down search results by specifying inclusion and exclusion criteria.
It automatically keeps track of model artifacts, hyperparameters, and metadata, helping you to reproduce and audit model versions. The SageMaker Pipelines decorator feature helps convert local ML code written as a Python program into one or more pipeline steps. SageMaker Pipelines can handle model versioning and lineage tracking.
Artificial intelligence (AI) and machine learning (ML) are becoming an integral part of systems and processes, enabling decisions in real time, thereby driving top and bottom-line improvements across organizations. However, putting an ML model into production at scale is challenging and requires a set of best practices.
In this example, the MLengineering team is borrowing 5 GPUs for their training task With SageMaker HyperPod, you can additionally set up observability tools of your choice. metadata: name: job-name namespace: hyperpod-ns-researchers labels: kueue.x-k8s.io/queue-name: queue-name: hyperpod-ns-researchers-localqueue kueue.x-k8s.io/priority-class:
In the ever-evolving landscape of machine learning, feature management has emerged as a key pain point for MLEngineers at Airbnb. A Seamless Integration for Airbnb’s ML Practitioners Chronon has proven to be a game-changer for Airbnb’s ML practitioners.
An MLengineer deploys the model pipeline into the ML team test environment using a shared services CI/CD process. After stakeholder validation, the ML model is deployed to the team’s production environment. ML operations This module helps LOBs and MLengineers work on their dev instances of the model deployment template.
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Can you compare images?
It is ideal for MLengineers, data scientists, and technical leaders, providing real-world training for production-ready generative AI using Amazon Bedrock and cloud-native services.
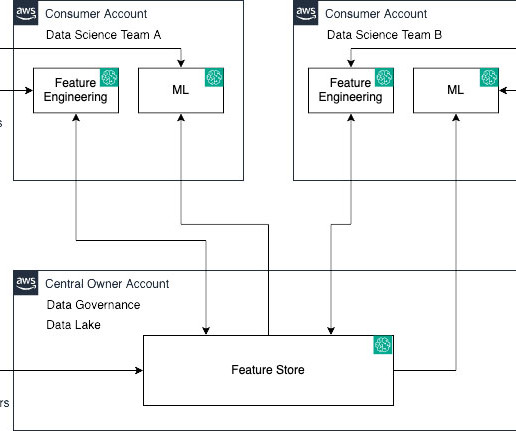
Let’s demystify this using the following personas and a real-world analogy: Data and MLengineers (owners and producers) – They lay the groundwork by feeding data into the feature store Data scientists (consumers) – They extract and utilize this data to craft their models Data engineers serve as architects sketching the initial blueprint.
Secondly, to be a successful MLengineer in the real world, you cannot just understand the technology; you must understand the business. We should start by considering the broad elements that should constitute any ML solution, as indicated in the following diagram: Figure 1.2:
Came to ML from software. Founded neptune.ai , a modular MLOps component for MLmetadata store , aka “experiment tracker + model registry”. Most of our customers are doing ML/MLOps at a reasonable scale, NOT at the hyperscale of big-tech FAANG companies. . – How about the MLengineer? Let me explain.
This post guides you through the steps to get started with setting up and deploying Studio to standardize ML model development and collaboration with fellow MLengineers and ML scientists. cdk.json – Contains metadata, and feature flags. Marcelo Aberle is an MLEngineer in the AWS AI organization.
Finally, you can store the model and other metadata information using the INSERT INTO command. Storing ML models in model registry A model registry is a central repository that can store, version, and manage machine learning models. It typically includes features like model versioning , metadata control, comparing model runs, etc.
Here, Amazon SageMaker Ground Truth allowed MLengineers to easily build the human-in-the-loop workflow (step v). The image is then uploaded into an Amazon Simple Storage Services (Amazon S3) bucket for images and the metadata about the image is stored in an Amazon DynamoDB table (step 6).
Specialist Data Engineering at Merck, and Prabakaran Mathaiyan, Sr. MLEngineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of software development. This post is co-written with Jayadeep Pabbisetty, Sr.
ML Governance: A Lean Approach Ryan Dawson | Principal Data Engineer | Thoughtworks Meissane Chami | Senior MLEngineer | Thoughtworks During this session, you’ll discuss the day-to-day realities of ML Governance. Some of the questions you’ll explore include How much documentation is appropriate?
Earth.com didn’t have an in-house MLengineering team, which made it hard to add new datasets featuring new species, release and improve new models, and scale their disjointed ML system. We initiated a series of enhancements to deliver managed MLOps platform and augment MLengineering.
We’ll see how this architecture applies to different classes of ML systems, discuss MLOps and testing aspects, and look at some example implementations. Understanding machine learning pipelines Machine learning (ML) pipelines are a key component of ML systems. But what is an ML pipeline?
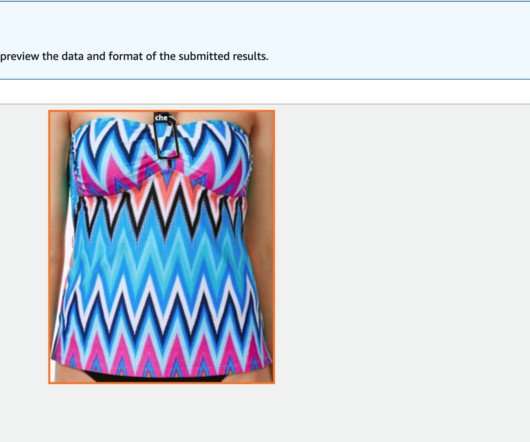
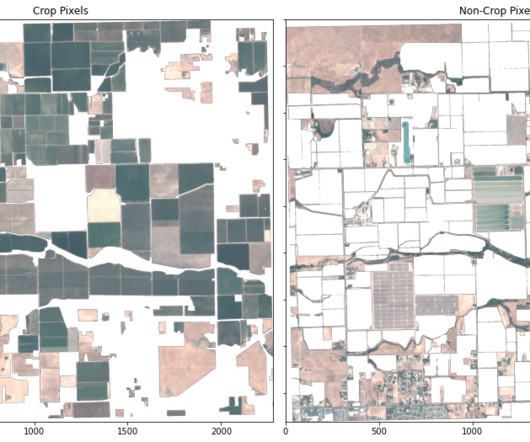
Solution overview Ground Truth is a fully self-served and managed data labeling service that empowers data scientists, machine learning (ML) engineers, and researchers to build high-quality datasets. For our example use case, we work with the Fashion200K dataset , released at ICCV 2017.
Planet and AWS’s partnership on geospatial ML SageMaker geospatial capabilities empower data scientists and MLengineers to build, train, and deploy models using geospatial data. It also contains each scene’s metadata, its image ID, and a preview image reference.
Fine-tuning an LLM can be a complex workflow for data scientists and machine learning (ML) engineers to operationalize. By logging your datasets with MLflow, you can store metadata, such as dataset descriptions, version numbers, and data statistics, alongside your MLflow runs.
Topics Include: Agentic AI DesignPatterns LLMs & RAG forAgents Agent Architectures &Chaining Evaluating AI Agent Performance Building with LangChain and LlamaIndex Real-World Applications of Autonomous Agents Who Should Attend: Data Scientists, Developers, AI Architects, and MLEngineers seeking to build cutting-edge autonomous systems.
Additionally, VitechIQ includes metadata from the vector database (for example, document URLs) in the model’s output, providing users with source attribution and enhancing trust in the generated answers. Prompt engineering Prompt engineering is crucial for the knowledge retrieval system.
Additionally, you can enable model invocation logging to collect invocation logs, full request response data, and metadata for all Amazon Bedrock model API invocations in your AWS account. Leveraging her expertise in Computer Vision and Deep Learning, she empowers customers to harness the power of the ML in AWS cloud efficiently.
He has experience with multiple programming languages, AWS cloud services, AI/ML technologies, product and operations management, pre and early seed start-up ventures, and corporate finance. Geeta Gharpure is a senior software developer on the Annapurna MLengineering team. os operator: In values: - linux - key: node.kubernetes.io/instance-type
Amazon SageMaker provides purpose-built tools for machine learning operations (MLOps) to help automate and standardize processes across the ML lifecycle. In this post, we describe how Philips partnered with AWS to develop AI ToolSuite—a scalable, secure, and compliant ML platform on SageMaker.
You will notice the content of this file as JSON with a text transcript available under the key transcripts, along with other metadata. Rushabh Lokhande is a Senior Data & MLEngineer with AWS Professional Services Analytics Practice. You can download a sample file and review the contents.
ML operations, known as MLOps, focus on streamlining, automating, and monitoring ML models throughout their lifecycle. Data scientists, MLengineers, IT staff, and DevOps teams must work together to operationalize models from research to deployment and maintenance.
You can call the SageMaker ListWorkteams or DescribeWorkteam APIs to view workteams’ metadata, including the WorkerAccessConfiguration. Abhinay Sandeboina is a Engineering Manager at AWS Human In The Loop (HIL). He has been in AWS for over 2 years and his teams are responsible for managing ML platform services.
Solution overview The ML solution for LTV forecasting is composed of four components: the training dataset ETL pipeline, MLOps pipeline, inference dataset ETL pipeline, and ML batch inference. MLengineers no longer need to manage this training metadata separately.
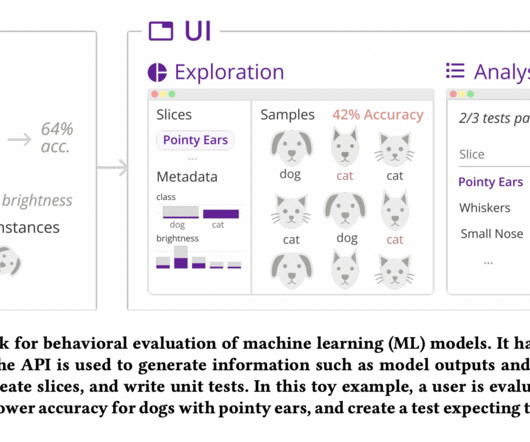
Stakeholders such as MLengineers, designers, and domain experts must work together to identify a model’s expected and potential faults. Instead, MLengineers collaborate with domain experts and designers to describe a model’s expected capabilities before it is iterated and deployed.
Model cards are intended to be a single source of truth for business and technical metadata about the model that can reliably be used for auditing and documentation purposes. They provide a fact sheet of the model that is important for model governance.
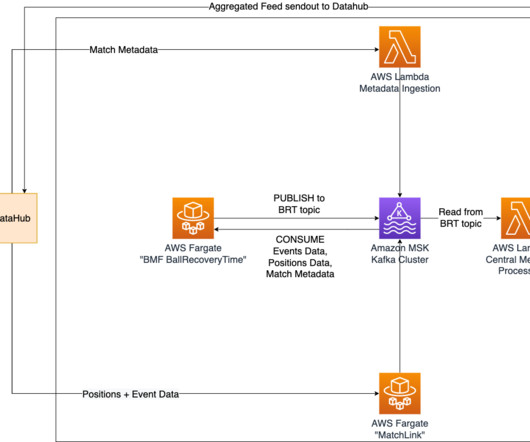
Metadata of the match is processed within the AWS Lambda function MetaDataIngestion , while positional data is ingested using the AWS Fargate container called MatchLink. Fotinos Kyriakides is an MLEngineer with AWS Professional Services. The following diagram illustrates the end-to-end workflow for Ball Recovery Time.
At Cruise, we noticed a wide gap between the complexity of cloud infrastructure, and the needs of the ML workforce. MLEngineers want to focus on writing Python logic, and visualizing the impact of their changes quickly. Could you please tell us about the vision and inspiration behind this project?
This post is co-written with Jad Chamoun, Director of Engineering at Forethought Technologies, Inc. and Salina Wu, Senior MLEngineer at Forethought Technologies, Inc. We defined logic that would take in model metadata, format the endpoint deterministically based on the metadata, and check whether the endpoint existed.
help data scientists systematically record, catalog, and analyze modeling artifacts and experiment metadata. is an experiment tracker for ML teams that struggle with debugging and reproducing experiments, sharing results, and messy model handover. Experiment trackers like neptune.ai Even though neptune.ai Aside neptune.ai
A session stores metadata and application-specific data known as session attributes. Ryan Gomes is a Data & MLEngineer with the AWS Professional Services Intelligence Practice. A session persists over time unless manually stopped or timed out. He leads the NYC machine learning and AI meetup.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content