This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One effective way to improve context relevance is through metadata filtering, which allows you to refine search results by pre-filtering the vector store based on custom metadata attributes. By combining the capabilities of LLM function calling and Pydantic data models, you can dynamically extract metadata from user queries.
Amazon Bedrock Knowledge Bases has a metadata filtering capability that allows you to refine search results based on specific attributes of the documents, improving retrieval accuracy and the relevance of responses. These metadata filters can be used in combination with the typical semantic (or hybrid) similarity search.
The post AWS Glue for Handling Metadata appeared first on Analytics Vidhya. The managed service offers a simple and cost-effective method of categorizing and managing big data in an enterprise. It provides organizations with […].
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
Introduction to LAION-DISCO-12M To address this gap, LAION AI has released LAION-DISCO-12M—a collection of 12 million links to publicly available YouTube samples, paired with metadata designed to support foundational machine learning research in audio and music.
If we log in to the VSI, we can see the volume disks: [root@test-metadata ~]# ls -la /dev/disk/by-id total 0 drwxr-xr-x. vdb If we want to find the data volume named test-metadata-volume , we see that it is the vdd disk. Recently, IBM Cloud VPC introduced the metadata service. 2 root root 200 Apr 7 12:58. drwxr-xr-x.
What role does metadata authentication play in ensuring the trustworthiness of AI outputs? Metadata authentication helps increase our confidence that assurances about an AI model or other mechanism are reliable. for a specific purpose.
Today, the company announced a $16 million Series A funding round to scale its groundbreaking solution and unveiled Ivo Search Agent, a tool that eliminates manual metadata tagging for contract search and analysis.
However, information about one dataset can be in another dataset, called metadata. Without using metadata, your retrieval process can cause the retrieval of unrelated results, thereby decreasing FM accuracy and increasing cost in the FM prompt token. This change allows you to use metadata fields during the retrieval process.
OpenAI is joining the Coalition for Content Provenance and Authenticity (C2PA) steering committee and will integrate the open standard’s metadata into its generative AI models to increase transparency around generated content.
With metadata filtering now available in Knowledge Bases for Amazon Bedrock, you can define and use metadata fields to filter the source data used for retrieving relevant context during RAG. Metadata filtering gives you more control over the RAG process for better results tailored to your specific use case needs.
This article will focus on LLM capabilities to extract meaningful metadata from product reviews, specifically using OpenAI API. Data processing Since our main area of interest is extracting metadata from reviews, we had to choose a subset of reviews and label it manually with selected fields of interest.
This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata. Generate metadata for the page. Generate metadata for the full document. Upload the content and metadata to Amazon S3.
Any type of contextual information, like device context, conversational context, and metadata, […]. However, we can improve the system’s accuracy by leveraging contextual information. The post Underlying Engineering Behind Alexa’s Contextual ASR appeared first on Analytics Vidhya.
Avi Perez, CTO of Pyramid Analytics, explained that his business intelligence software’s AI infrastructure was deliberately built to keep data away from the LLM , sharing only metadata that describes the problem and interfacing with the LLM as the best way for locally-hosted engines to run analysis.”There’s
Metadata boosting To improve the accuracy of responses from Amazon Q Business application with CSV files, you can add metadata to documents in an S3 bucket by using a metadata file. To learn about metadata search, refer to Configuring metadata controls in Amazon Q Business. About the author Jiten Dedhia is a Sr.
Unlike previous frameworks that require predefined tool configurations, OctoTools introduces tool cards, which encapsulate tool functionalities and metadata. The planner first analyzes the user query and determines the appropriate tools based on metadata associated with each tool card.
Solution overview By combining the powerful vector search capabilities of OpenSearch Service with the access control features provided by Amazon Cognito , this solution enables organizations to manage access controls based on custom user attributes and document metadata. If you don’t already have an AWS account, you can create one.
A JSON metadata file for each document containing additional information to customize chat results for end-users and apply boosting techniques to enhance user experience (which we discuss more in the next section). For the metadata file used in this example, we focus on boosting two key metadata attributes: _document_title and services.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
The Cyberspace Administration of China just released regulations that requires the explicit marking of AI-generated content — both visually and in its metadata.
This archive includes over 24 million image-text pairs from 6 million articles enriched with metadata and expert annotations. Articles and media files are downloaded from the NCBI server, extracting metadata, captions, and figure references from nXML files and the Entrez API.
When using the FAISS adapter, translation units are stored into a local FAISS index along with the metadata. You can enhance this technique by using metadata-driven filtering to collect the relevant pairs according to the source text. The request is sent to the prompt generator. Cohere Embed supports 108 languages.
Often support for metadata filtering alongside vector search Popular vector databases include FAISS (Facebook AI Similarity Search), Pinecone, Weaviate, Milvus, and Chroma. Fast similarity search using algorithms like HNSW, IVF, or exact search 2. Support for various distance metrics (cosine, euclidean, dot product) 3.
The platform automatically analyzes metadata to locate and label structured data without moving or altering it, adding semantic meaning and aligning definitions to ensure clarity and transparency. When onboarding customers, we automatically retrain these ontologies on their metadata.
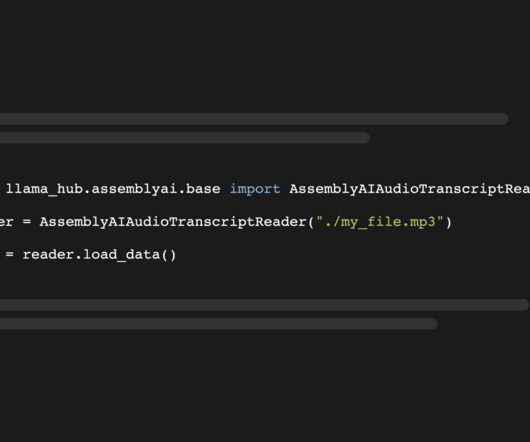
The metadata contains the full JSON response of our API with more meta information: print(docs[0].metadata) The metadata needs to be smaller than the text chunk size, and since it contains the full JSON response with extra information, it is quite large. You can read more about the integration in the official Llama Hub docs.
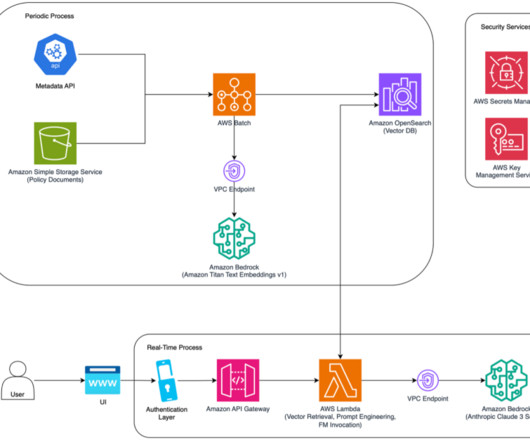
Along with each document slice, we store the metadata associated with it using an internal Metadata API, which provides document characteristics like document type, jurisdiction, version number, and effective dates. This process has been implemented as a periodic job to keep the vector database updated with new documents.
Also, a lakehouse can introduce definitional metadata to ensure clarity and consistency, which enables more trustworthy, governed data. Watsonx.data enables users to access all data through a single point of entry, with a shared metadata layer deployed across clouds and on-premises environments. All of this supports the use of AI.
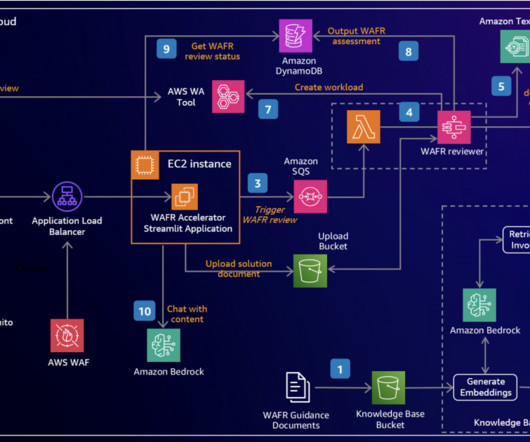
Metadata filtering is used to improve retrieval accuracy. The WAFR reviewer uses Amazon Bedrock Knowledge Bases fully managed RAG workflow to query the vector database in OpenSearch Serverless, retrieving relevant WAFR guidance based on the selected WAFR pillar and questions.
For instance, we use query rewriting techniques such as expansion, relaxation, and segmentation, and extract metadata from queries to dynamically build filters for more targeted searches.
It also mandates the labelling of deepfakes with permanent unique metadata or other identifiers to prevent misuse. Furthermore, the document outlines plans for implementing a “consent popup” mechanism to inform users about potential defects or errors produced by AI.
print("-" * 50) interactive_search() Let’s add the ability to filter our search results by metadata: Copy Code Copied Use a different Browser def filtered_search(query, filter_source=None, n_results=5): """ Search with optional filtering by source. Copy Code Copied Use a different Browser dataset = load_dataset("wikipedia", "20220301.en",
These applications leverage AI tasks such as object detection, segmentation, video metadata and re-identification to rapidly and accurately identify legitimate vs. suspicious or abnormal people or behavior and trigger responses in real time. The most common AI use cases in surveillance systems include perimeter protection and access control.
Solution overview Data and metadata discovery is one of the primary requirements in data analytics, where data consumers explore what data is available and in what format, and then consume or query it for analysis. But in the case of unstructured data, metadata discovery is challenging because the raw data isn’t easily readable.
Image Source The core innovation behind olmOCR is document anchoring, a technique that combines textual metadata with image-based analysis. Utilizes document anchoring to combine textual metadata with image-based information, significantly improving the extraction accuracy for structured content.
Data engineers contribute to the data lineage process by providing the necessary information and metadata about the data transformations they perform. It handles the actual maintenance and management of data lineage information, using the metadata provided by data engineers to build and maintain the data lineage.
This capability enables organizations to create custom inference profiles for Bedrock base foundation models, adding metadata specific to tenants, thereby streamlining resource allocation and cost monitoring across varied AI applications.
In exchange, Smith offered metadata such as song titles and artist names, and offered a share of streaming earnings. According to the indictment, Smith began working with the CEO of an undisclosed AI music firm around 2018. This co-conspirator allegedly provided Smith with thousands of AI-generated tracks each month.
In addition, 3FS incorporates stateless metadata services that are supported by a transactional key-value store, such as FoundationDB. By decoupling metadata management from the storage layer, the system not only becomes more scalable but also reduces potential bottlenecks related to metadata operations.
It stores information such as job ID, status, creation time, and other metadata. The following is a screenshot of the DynamoDB table where you can track the job status and other types of metadata related to the job. The DynamoDB table is crucial for tracking and managing the batch inference jobs throughout their lifecycle.
When you initiate a sync, Amazon Q will crawl the data source to extract relevant documents, then sync them to the Amazon Q index, making them searchable After syncing data sources, you can configure the metadata controls in Amazon Q Business. An Amazon Q Business index has fields that you can map your document attributes to.
Storage array maker says customers can get data from any NFS storage to use in RAG for internal enterprise AI projects, and claims its OS metadata expertise enables this
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content