This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
LargeLanguageModels (LLMs) are capable of understanding and generating human-like text, making them invaluable for a wide range of applications, such as chatbots, content generation, and language translation. LargeLanguageModels (LLMs) are a type of neural network model trained on vast amounts of text data.
The evolution of LargeLanguageModels (LLMs) allowed for the next level of understanding and information extraction that classical NLP algorithms struggle with. This article will focus on LLM capabilities to extract meaningful metadata from product reviews, specifically using OpenAI API.
It is probably good to also to mention that I wrote all of these summaries myself and they are not generated by any languagemodels. Are Emergent Abilities of LargeLanguageModels a Mirage? Do LargeLanguageModels Latently Perform Multi-Hop Reasoning? Here we go. NeurIPS 2023. ArXiv 2024.
Largelanguagemodels (LLMs) have exploded in popularity over the last few years, revolutionizing natural language processing and AI. What are LargeLanguageModels and Why are They Important? Their foundational nature allows them to be fine-tuned for a wide variety of downstream NLP tasks.
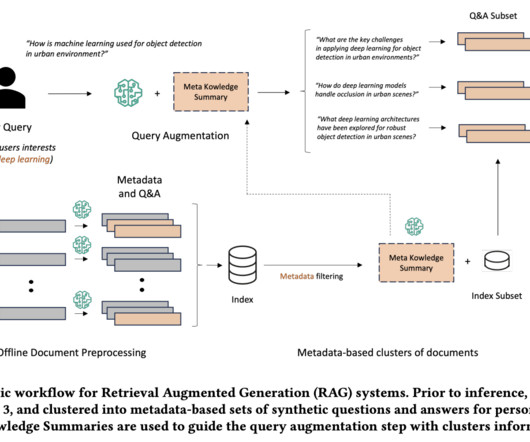
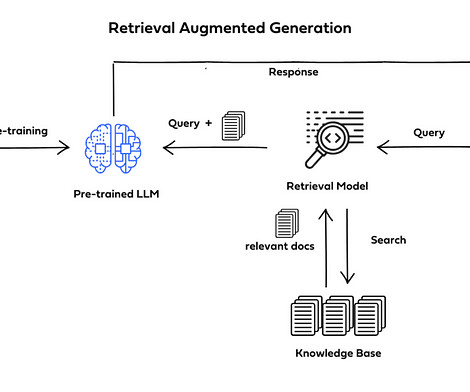
Retrieval Augmented Generation (RAG) represents a cutting-edge advancement in Artificial Intelligence, particularly in NLP and Information Retrieval (IR). Image Source The proposed methodology processes documents by generating custom metadata and QA pairs using advanced LLMs, such as Claude 3 Haiku.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
To bridge this gap, Amazon Bedrock now introduces application inference profiles , a new capability that allows organizations to apply custom cost allocation tags to track, manage, and control their Amazon Bedrock on-demand model costs and usage. He focuses on Deep learning including NLP and Computer Vision domains.
Largelanguagemodels (LLMs) like OpenAI's GPT series have been trained on a diverse range of publicly accessible data, demonstrating remarkable capabilities in text generation, summarization, question answering, and planning. Data Indexes : Post data ingestion, LlamaIndex assists in indexing this data into a retrievable format.
The recent NLP Summit served as a vibrant platform for experts to delve into the many opportunities and also challenges presented by largelanguagemodels (LLMs). Largelanguagemodels (LLMs) are a powerful new technology with the potential to revolutionize many industries. Unstructured.IO
Languagemodels are statistical methods predicting the succession of tokens in sequences, using natural text. Largelanguagemodels (LLMs) are neural network-based languagemodels with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical.
However, traditional machine learning approaches often require extensive data-specific tuning and model customization, resulting in lengthy and resource-heavy development. Enter Chronos , a cutting-edge family of time series models that uses the power of largelanguagemodel ( LLM ) architectures to break through these hurdles.
Solution overview Data and metadata discovery is one of the primary requirements in data analytics, where data consumers explore what data is available and in what format, and then consume or query it for analysis. But in the case of unstructured data, metadata discovery is challenging because the raw data isn’t easily readable.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. Foundation models: The power of curated datasets Foundation models , also known as “transformers,” are modern, large-scale AI models trained on large amounts of raw, unlabeled data.
In Natural Language Processing (NLP) tasks, data cleaning is an essential step before tokenization, particularly when working with text data that contains unusual word separations such as underscores, slashes, or other symbols in place of spaces. The post Is There a Library for Cleaning Data before Tokenization?
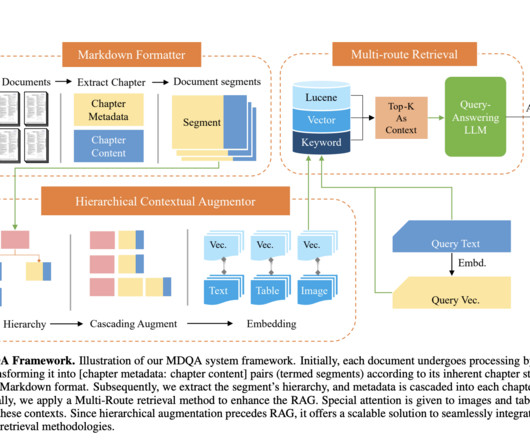
Participants learn to build metadata for documents containing text and images, retrieve relevant text chunks, and print citations using Multimodal RAG with Gemini. TensorFlow on Google Cloud This course covers designing TensorFlow input data pipelines and building ML models with TensorFlow and Keras.
I’m so excited to talk to you about LanguageModels! They’re these incredible creations called LargeLanguageModels (LLMs) that have the power to understand and generate human-like text. Prompt Usage Tracker: Working and iterating on LargeLanguagemodels may require us to use paid APIs.
A significant challenge with question-answering (QA) systems in Natural Language Processing (NLP) is their performance in scenarios involving extensive collections of documents that are structurally similar or ‘indistinguishable.’
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. This generative AI task is called text-to-SQL, which generates SQL queries from natural language processing (NLP) and converts text into semantically correct SQL. We use Anthropic Claude v2.1
.” Sean Im, CEO, Samsung SDS America “In the field of generative AI and foundation models, watsonx is a platform that will enable us to meet our customers’ requirements in terms of optimization and security, while allowing them to benefit from the dynamism and innovations of the open-source community.”
The award, totaling $299,208 for one year, will be used for research and development of LLMs for automated named entity recognition (NER), relation extraction, and ontology metadata enrichment from free-text clinical notes.
Using natural language processing (NLP) and OpenAPI specs, Amazon Bedrock Agents dynamically manages API sequences, minimizing dependency management complexities. Set up the policy documents and metadata in the data source for the knowledge base We use Amazon Bedrock Knowledge Bases to manage our documents and metadata.
Evolving Trends in Prompt Engineering for LargeLanguageModels (LLMs) with Built-in Responsible AI Practices Editor’s note: Jayachandran Ramachandran and Rohit Sroch are speakers for ODSC APAC this August 22–23. This trainable custom model can then be progressively improved through a feedback loop as shown above.
Retrieval-Augmented Generation (RAG) is a cutting-edge method of natural language processing that produces precise and contextually relevant answers by fusing the strength of largelanguagemodels (LLMs) with an external knowledge retrieval system. _pages_and_chunks( pages_and_texts ) # Create chunks with metadata.
The Pile dataset is a massive, diverse, and high-quality dataset designed for training largelanguagemodels (LLMs) like GPT. It consolidates data from multiple sources to provide a broad representation of human knowledge, ensuring models trained on it can generate nuanced, context-aware, and accurate outputs.
These models have been packaged to be securely and easily deployable via Amazon SageMaker APIs. The new SageMaker JumpStart Foundation Hub allows you to easily deploy largelanguagemodels (LLM) and integrate them with your applications. You then generate an embedding of the metadata using a LLM.
Articles ThunderMLA from Stanford researchers, a new optimization approach for variable-length sequence processing to largelanguagemodel inference that addresses critical performance bottlenecks in attention mechanisms. verl is a flexible, efficient and production-ready RL training library for largelanguagemodels (LLMs).
Largelanguagemodels (LLMs) are revolutionizing fields like search engines, natural language processing (NLP), healthcare, robotics, and code generation. A media metadata store keeps the promotion movie list up to date. A feature store maintains user profile data.
Conversational AI has come a long way in recent years thanks to the rapid developments in generative AI, especially the performance improvements of largelanguagemodels (LLMs) introduced by training techniques such as instruction fine-tuning and reinforcement learning from human feedback.
It was built using a combination of in-house and external cloud services on Microsoft Azure for largelanguagemodels (LLMs), Pinecone for vectorized databases, and Amazon Elastic Compute Cloud (Amazon EC2) for embeddings. Opportunities for innovation CreditAI by Octus version 1.x x uses Retrieval Augmented Generation (RAG).
Retrieval Augmented Generation (RAG) is an AI framework that optimizes the output of a LargeLanguageModel (LLM) by referencing a credible knowledge base outside of its training sources. LLMs are crucial for driving intelligent chatbots and other NLP applications.
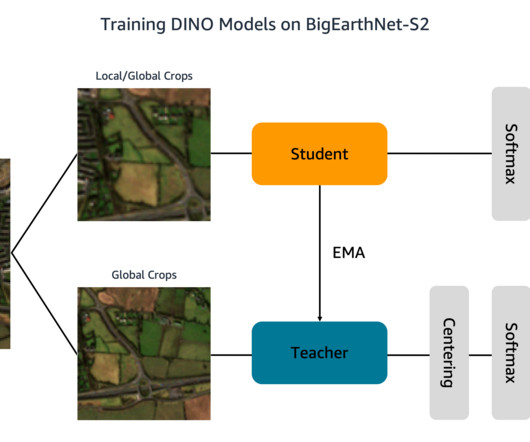
Additionally, each folder contains a JSON file with the image metadata. To perform statistical analyses of the data and load images during DINO training, we process the individual metadata files into a common geopandas Parquet file. We store the BigEarthNet-S2 images and metadata file in an S3 bucket. tif" --include "_B03.tif"
Using machine learning (ML) and natural language processing (NLP) to automate product description generation has the potential to save manual effort and transform the way ecommerce platforms operate. BLIP-2 consists of three models: a CLIP-like image encoder, a Querying Transformer (Q-Former) and a largelanguagemodel (LLM).
Let’s start with a brief introduction to Spark NLP and then discuss the details of pretrained pipelines with some concrete results. Spark NLP & LLM The Healthcare Library is a powerful component of John Snow Labs’ Spark NLP platform, designed to facilitate NLP tasks within the healthcare domain. word embeddings).
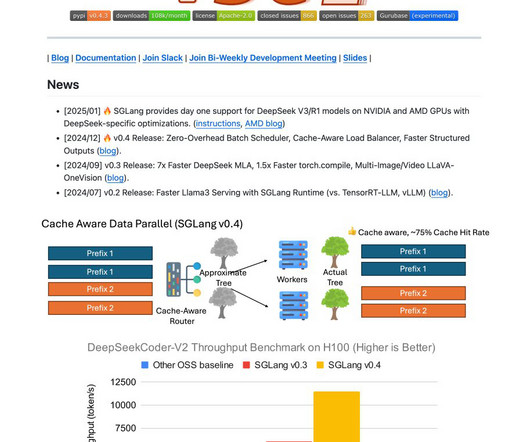
The scheduler keeps the GPUs continuously engaged by running one batch ahead and preparing all necessary metadata for the next batch. Profiling has shown that this design reduces idle time and achieves measurable speed improvements, especially in configurations that involve smaller models and extensive tensor parallelism.
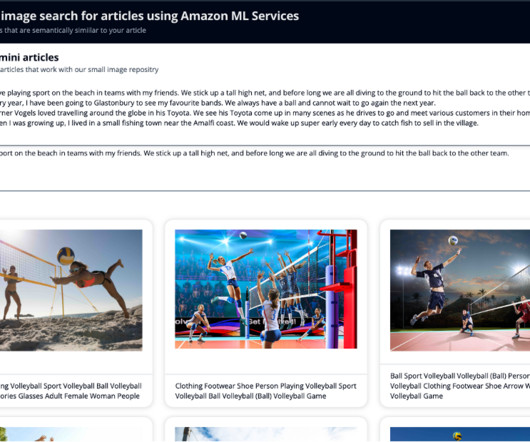
Images can often be searched using supplemented metadata such as keywords. However, it takes a lot of manual effort to add detailed metadata to potentially thousands of images. Generative AI (GenAI) can be helpful in generating the metadata automatically. This helps us build more refined searches in the image search process.
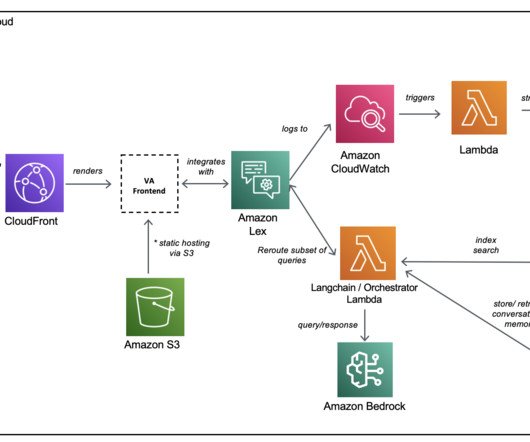
Each request/response interaction is facilitated by the AWS SDK and sends network traffic to Amazon Lex (the NLP component of the bot). Metadata about the request/response pairings are logged to Amazon CloudWatch. Several webpages were ingested into the Amazon Kendra index and used as the data source.
Genomic languagemodels are a new and exciting field in the application of largelanguagemodels to challenges in genomics. In this blog post and open source project , we show you how you can pre-train a genomics languagemodel, HyenaDNA , using your genomic data in the AWS Cloud.
As a first step, they wanted to transcribe voice calls and analyze those interactions to determine primary call drivers, including issues, topics, sentiment, average handle time (AHT) breakdowns, and develop additional natural language processing (NLP)-based analytics.
The emergence of generative AI agents in recent years has contributed to the transformation of the AI landscape, driven by advances in largelanguagemodels (LLMs) and natural language processing (NLP). This post will discuss agentic AI driven architecture and ways of implementing.
This is where the integration of cutting-edge technologies, such as audio-to-text translation and largelanguagemodels (LLMs), holds the potential to revolutionize the way patients receive, process, and act on vital medical information. These insights can include: Potential adverse event detection and reporting.
To tackle this challenge, AWS Generative AI Innovation Center scientists explored a variety of solutions to optimize GPT-2 inference performance, resulting in lowering the model latency by 50% on average and improving the QPS by 200%. model_fp16.onnx onnx.engine batch_size = 10 max_sequence_length = 42 profiles = [Profile().add( model_fp16.onnx
Additionally, we examine potential solutions to enhance the capabilities of largelanguagemodels (LLMs) and visual languagemodels (VLMs) with advanced LangChain capabilities, enabling them to generate more comprehensive, coherent, and accurate outputs while effectively handling multimodal data.
Largelanguagemodels (LLMs) have transformed the way we engage with and process natural language. These powerful models can understand, generate, and analyze text, unlocking a wide range of possibilities across various domains and industries.
This is where metadata comes in. Metadata is essentially data about data. In the context of machine learning, dataset metadata provides information about the data itself, such as its format, size, and what it represents. Having high-quality metadata is essential for several reasons.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content