This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
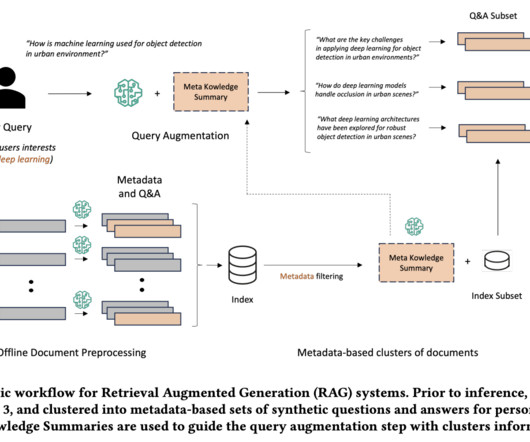
The effectiveness of RAG heavily depends on the quality of context provided to the largelanguagemodel (LLM), which is typically retrieved from vector stores based on user queries. The relevance of this context directly impacts the model’s ability to generate accurate and contextually appropriate responses.
Amazon Bedrock Knowledge Bases offers a fully managed Retrieval Augmented Generation (RAG) feature that connects largelanguagemodels (LLMs) to internal data sources. These metadata filters can be used in combination with the typical semantic (or hybrid) similarity search.
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
One of these strategies is using Amazon Simple Storage Service (Amazon S3) folder structures and Amazon Bedrock Knowledge Bases metadata filtering to enable efficient data segmentation within a single knowledge base. The S3 bucket, containing customer data and metadata, is configured as a knowledge base data source.
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
Largelanguagemodels (LLMs) have demonstrated promising capabilities in machine translation (MT) tasks. Depending on the use case, they are able to compete with neural translation models such as Amazon Translate. When using the FAISS adapter, translation units are stored into a local FAISS index along with the metadata.
The AI Commentary feature is a generative AI built from a largelanguagemodel that was trained on a massive corpus of language data. The world’s eyes were first opened to the power of largelanguagemodels last November when a chatbot application dominated news cycles.
What role does metadata authentication play in ensuring the trustworthiness of AI outputs? Metadata authentication helps increase our confidence that assurances about an AI model or other mechanism are reliable. How can organizations mitigate the risk of AI bias and hallucinations in largelanguagemodels (LLMs)?
TL;DR Multimodal LargeLanguageModels (MLLMs) process data from different modalities like text, audio, image, and video. Compared to text-only models, MLLMs achieve richer contextual understanding and can integrate information across modalities, unlocking new areas of application.
LargeLanguageModels (LLMs) are capable of understanding and generating human-like text, making them invaluable for a wide range of applications, such as chatbots, content generation, and language translation. LargeLanguageModels (LLMs) are a type of neural network model trained on vast amounts of text data.
LargeLanguageModels (LLMs) have revolutionized AI with their ability to understand and generate human-like text. Learning about LLMs is essential to harness their potential for solving complex language tasks and staying ahead in the evolving AI landscape.
Largelanguagemodels (LLMs) are limited by complex reasoning tasks that require multiple steps, domain-specific knowledge, or external tool integration. OctoTools is a modular, training-free, and extensible framework that standardizes how AI models interact with external tools.
It also mandates the labelling of deepfakes with permanent unique metadata or other identifiers to prevent misuse. Furthermore, the document outlines plans for implementing a “consent popup” mechanism to inform users about potential defects or errors produced by AI.
The evolution of LargeLanguageModels (LLMs) allowed for the next level of understanding and information extraction that classical NLP algorithms struggle with. This article will focus on LLM capabilities to extract meaningful metadata from product reviews, specifically using OpenAI API.
Knowledge bases allow Amazon Bedrock users to unlock the full potential of Retrieval Augmented Generation (RAG) by seamlessly integrating their company data into the languagemodel’s generation process. Metadata filtering gives you more control over the RAG process for better results tailored to your specific use case needs.
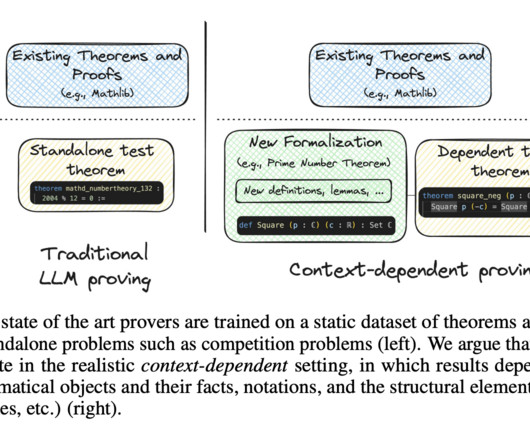
Formal theorem proving has emerged as a critical benchmark for assessing the reasoning capabilities of largelanguagemodels (LLMs), with significant implications for mathematical automation. Each approach brought specific innovations but remained limited in handling the comprehensive requirements of formal theorem proving.
Solution overview By combining the powerful vector search capabilities of OpenSearch Service with the access control features provided by Amazon Cognito , this solution enables organizations to manage access controls based on custom user attributes and document metadata. If you don’t already have an AWS account, you can create one.
These models can also rank potential sites by identifying the best combination of site attributes and factors that align with study objectives and recruitment strategies. Healthtech companies adopting AI are also developing tools that help physicians to quickly and accurately determine eligible trials for patients.
This technique is designed to enhance the capabilities of LargeLanguageModels (LLMs) by seamlessly integrating contextually relevant, timely, and domain-specific information into their responses. This new approach transforms the existing pipeline into a more sophisticated prepare-then-rewrite-then-retrieve-then-read framework.
The growth of autonomous agents by foundation models (FMs) like LargeLanguageModels (LLMs) has reform how we solve complex, multi-step problems. These agents perform tasks ranging from customer support to software engineering, navigating intricate workflows that combine reasoning, tool use, and memory.
Largelanguagemodels (LLMs) have exploded in popularity over the last few years, revolutionizing natural language processing and AI. What are LargeLanguageModels and Why are They Important? Hybrid retrieval combines dense embeddings and sparse keyword metadata for improved recall.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
Each dataset includes metadata and training/testing splits, enabling easy benchmarking of different machine-learning models. The variety and granularity of the datasets encourage the development of generalizable models capable of solving a broad spectrum of problems in physics, chemistry, and engineering.
LlamaIndex is a flexible data framework for connecting custom data sources to LargeLanguageModels (LLMs). The metadata contains the full JSON response of our API with more meta information: print(docs[0].metadata) With LlamaIndex, you can easily store and index your data and then apply LLMs. print(docs[0].text)
To start simply, you could think of LLMOps ( LargeLanguageModel Operations) as a way to make machine learning work better in the real world over a long period of time. As previously mentioned: model training is only part of what machine learning teams deal with. What is LLMOps? Why are these elements so important?
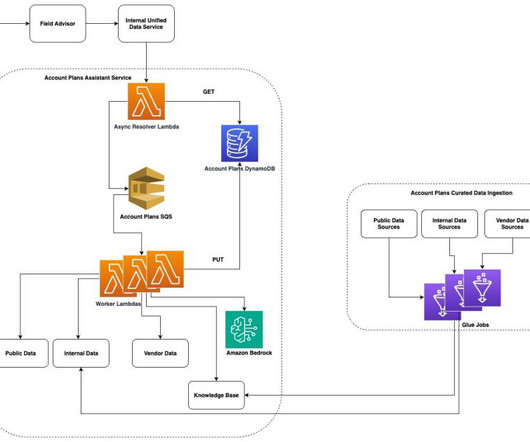
Mid-market Account Manager Amazon Q, Amazon Bedrock, and other AWS services underpin this experience, enabling us to use largelanguagemodels (LLMs) and knowledge bases (KBs) to generate relevant, data-driven content for APs. Its a game-changer for serving my full portfolio of accounts.
Instead of solely focusing on whos building the most advanced models, businesses need to start investing in robust, flexible, and secure infrastructure that enables them to work effectively with any AI model, adapt to technological advancements, and safeguard their data. Did we over-invest in companies like OpenAI and NVIDIA?
results.json captures the metadata of this particular job run, such as the model’s configuration, batch size, total steps, gradient accumulation steps, and training dataset name. The model checkpoint and output log per each compute node are also captured in this directory. This directory is accessible to all compute nodes.
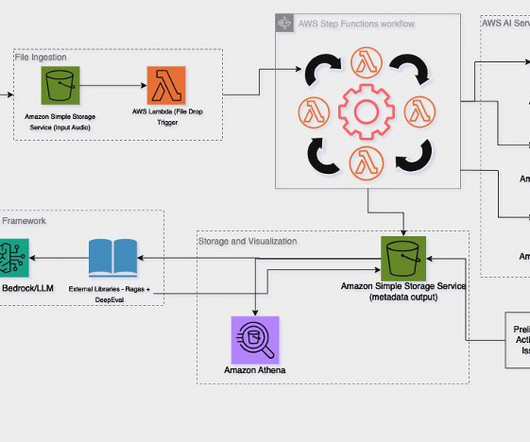
The evaluation framework, call metadata generation, and Amazon Q in QuickSight were new components introduced from the original PCA solution. Ragas and a human-in-the-loop UI (as described in the customer blogpost with Tealium) were used to evaluate the metadata generation and individual call Q&A portions.
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team There has been great progress towards adapting largelanguagemodels (LLMs) to accommodate multimodal inputs for tasks including image captioning , visual question answering (VQA) , and open vocabulary recognition.
Customizable Uses prompt engineering , which enables customization and iterative refinement of the prompts used to drive the largelanguagemodel (LLM), allowing for refining and continuous enhancement of the assessment process. Metadata filtering is used to improve retrieval accuracy.
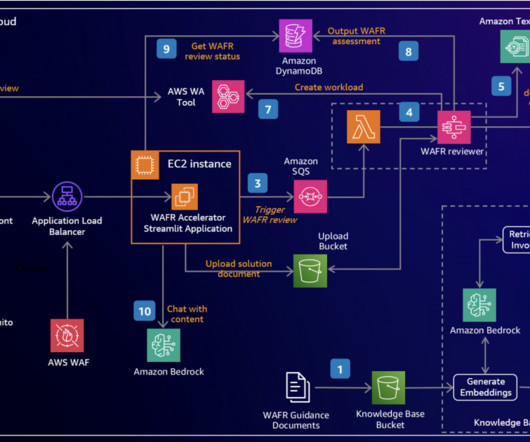
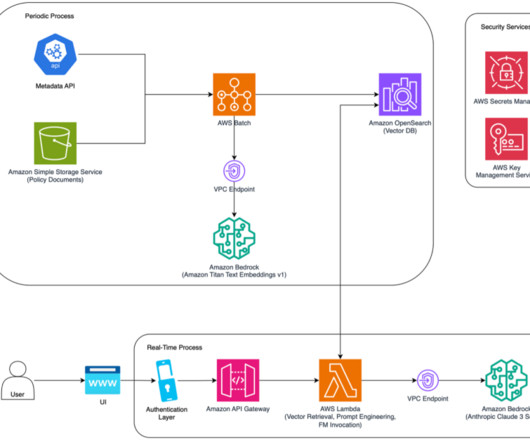
An AWS Batch job reads these documents, chunks them into smaller slices, then creates embeddings of the text chunks using the Amazon Titan Text Embeddings model through Amazon Bedrock and stores them in an Amazon OpenSearch Service vector database.
DMS: OneMeta+OneOps, a platform for unified management of metadata across multiple cloud environments. Alibaba Cloud Open Lake, a solution to maximise data utility for generative AI applications. PAI AI Scheduler, a proprietary cloud-native scheduling engine for enhanced computing resource management.
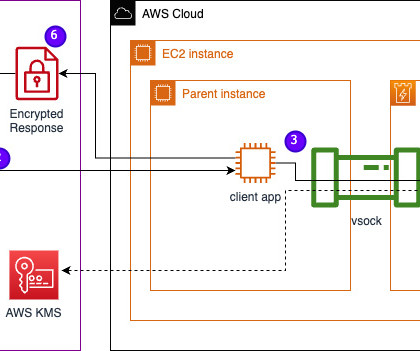
In this post, we discuss how Leidos worked with AWS to develop an approach to privacy-preserving largelanguagemodel (LLM) inference using AWS Nitro Enclaves. LLMs are designed to understand and generate human-like language, and are used in many industries, including government, healthcare, financial, and intellectual property.
LangChain is a framework for developing applications powered by LargeLanguageModels (LLMs). The metadata contains the full JSON response of our API with more meta information: print(docs[0].metadata) With LangChain, you can easily apply LLMs to your data and, for example, ask questions about the contents of your data.
With the FMEval package the model hosting is agnostic, but there are a few built-in model runners that are provided. For instance, a native JumpStart, Amazon Bedrock, and SageMaker Endpoint Model Runner classes have been provided.
Largelanguagemodels (LLMs) like OpenAI's GPT series have been trained on a diverse range of publicly accessible data, demonstrating remarkable capabilities in text generation, summarization, question answering, and planning. Data Indexes : Post data ingestion, LlamaIndex assists in indexing this data into a retrievable format.
Retrieval-augmented generation ( RAG ) has emerged as a powerful paradigm for enhancing the capabilities of largelanguagemodels (LLMs). Often support for metadata filtering alongside vector search Popular vector databases include FAISS (Facebook AI Similarity Search), Pinecone, Weaviate, Milvus, and Chroma.
What Is Ollama and the Ollama API Functionality Ollama is an open-source framework that enables developers to run largelanguagemodels (LLMs) like Llama 3.2 It offers a lightweight, extensible platform for building and managing languagemodels, providing a simple API for creating, running, and managing models.
Models typically treat all input data equivalently, disregarding contextual cues about the source or style. This approach has two primary shortcomings: Missed Contextual Signals : Without considering metadata such as source URLs, LMs overlook important contextual information that could guide their understanding of a texts intent or quality.
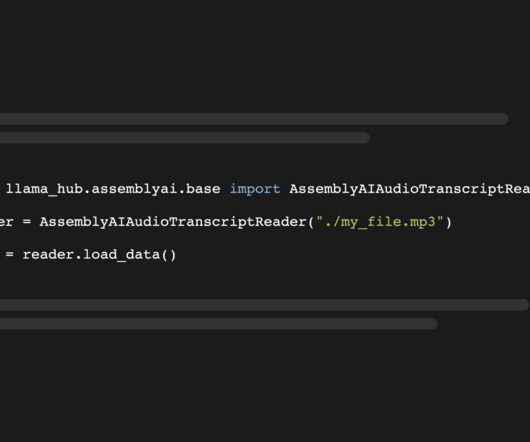
Join Us On Discord Use LargeLanguageModels With Voice Data Get more from your voice data with our guides on using LargeLanguageModels (LLMs) with LeMUR. Extract and generate data : Find out how to extract tags and descriptions from your audio to enhance metadata and searchability with LeMUR.
The advent of Multimodal LargeLanguageModels (MLLM) has ushered in a new era of mobile device agents, capable of understanding and interacting with the world through text, images, and voice. Along with GPT-4V, Mobile-Agent also employs an icon detection module for icon localization.
In this post, we show you an example of a generative AI assistant application and demonstrate how to assess its security posture using the OWASP Top 10 for LargeLanguageModel Applications , as well as how to apply mitigations for common threats.
Join Us On Discord Use LargeLanguageModels With Voice Data Get more from your voice data with our new guides on using LargeLanguageModels (LLMs) with LeMUR. Extract and generate data : Find out how to extract tags and descriptions from your audio to enhance metadata and searchability with LeMUR.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content