This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
Introduction to LAION-DISCO-12M To address this gap, LAION AI has released LAION-DISCO-12M—a collection of 12 million links to publicly available YouTube samples, paired with metadata designed to support foundational machine learning research in audio and music. Don’t Forget to join our 55k+ ML SubReddit.
This post is part of an ongoing series about governing the machine learning (ML) lifecycle at scale. The data mesh architecture aims to increase the return on investments in data teams, processes, and technology, ultimately driving business value through innovative analytics and ML projects across the enterprise.
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data. Generate metadata for the page.
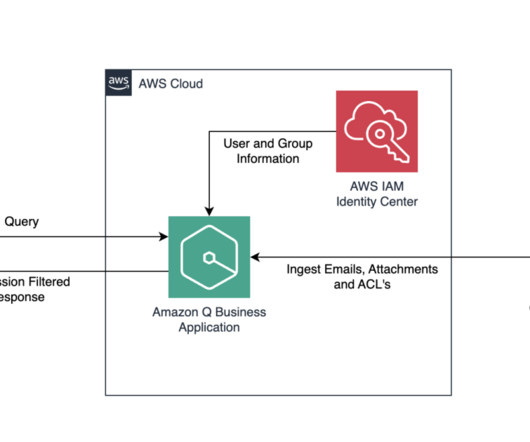
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Furthermore, it might contain sensitive data or personally identifiable information (PII) requiring redaction.
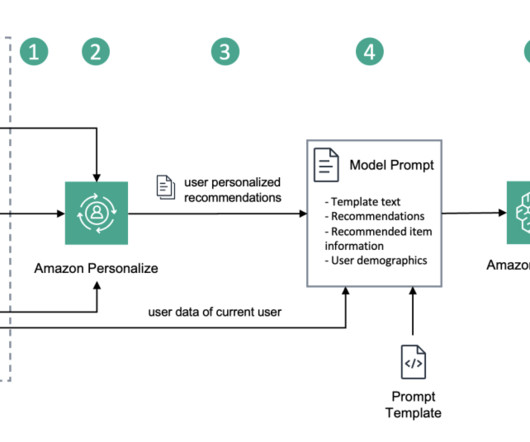
For instance, as a marketing manager for a video-on-demand company, you might want to send personalized email messages tailored to each individual usertaking into account their demographic information, such as gender and age, and their viewing preferences. This can be information like the title, description, or movie genre.
This conversational agent offers a new intuitive way to access the extensive quantity of seed product information to enable seed recommendations, providing farmers and sales representatives with an additional tool to quickly retrieve relevant seed information, complementing their expertise and supporting collaborative, informed decision-making.
Building a Data Foundation for the Future According to a recent KPMG survey , 67% of business leaders expect AI to fundamentally transform their businesses within the next two years, and 85% feel like data quality will be the biggest bottleneck to progress.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. Additionally, we show how to use AWS AI/ML services for analyzing unstructured data.
When building machine learning (ML) models using preexisting datasets, experts in the field must first familiarize themselves with the data, decipher its structure, and determine which subset to use as features. So much so that a basic barrier, the great range of data formats, is slowing advancement in ML.
Todays organizations face a critical challenge with the fragmentation of vital information across multiple environments. This solution helps streamline information retrieval, enhance collaboration, and significantly boost overall operational efficiency, offering a glimpse into the future of intelligent enterprise information management.
Knowledge bases effectively bridge the gap between the broad knowledge encapsulated within foundation models and the specialized, domain-specific information that businesses possess, enabling a truly customized and valuable generative artificial intelligence (AI) experience.
Solution overview By combining the powerful vector search capabilities of OpenSearch Service with the access control features provided by Amazon Cognito , this solution enables organizations to manage access controls based on custom user attributes and document metadata. For more information, see Getting started with the AWS CDK.
These datasets encompass millions of hours of music, over 10 million recordings and compositions accompanied by comprehensive metadata, including key, tempo, instrumentation, keywords, moods, energies, chords, and more, facilitating training and commercial usage. GCX provides datasets with over 4.4
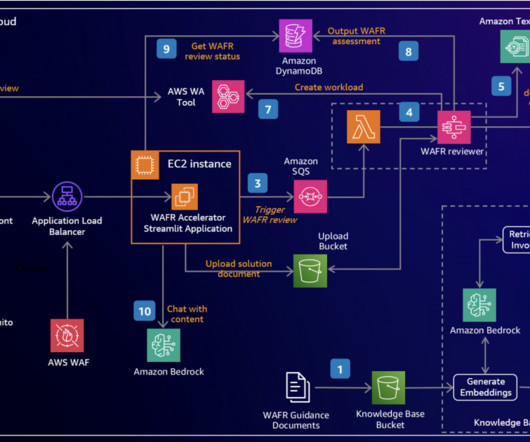
Integration with the AWS Well-Architected Tool pre-populates workload information and initial assessment responses. Metadata filtering is used to improve retrieval accuracy. The WAFR Accelerator application retrieves the review status from the DynamoDB table to keep the user informed.
It often requires managing multiple machine learning (ML) models, designing complex workflows, and integrating diverse data sources into production-ready formats. In a world whereaccording to Gartner over 80% of enterprise data is unstructured, enterprises need a better way to extract meaningful information to fuel innovation.
in Information Systems Engineering from Ben Gurion University and an MBA from the Technion, Israel Institute of Technology. Along the way, I’ve learned different best practices – from how to manage a team to how to inform the proper strategy – that have shaped how I lead at Deep Instinct. ML is unfit for the task.
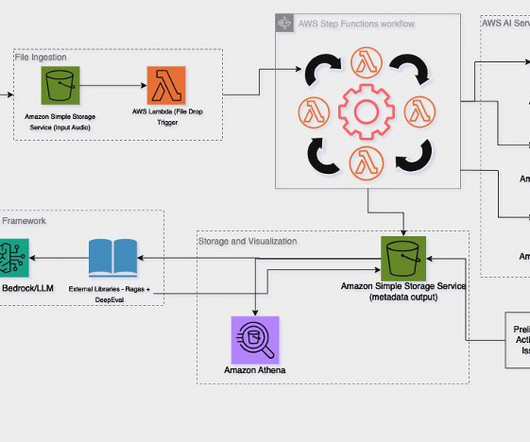
AI/ML and generative AI: Computer vision and intelligent insights As drones capture video footage, raw data is processed through AI-powered models running on Amazon Elastic Compute Cloud (Amazon EC2) instances. It even aids in synthetic training data generation, refining our ML models for improved accuracy.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
Structured data, defined as data following a fixed pattern such as information stored in columns within databases, and unstructured data, which lacks a specific form or pattern like text, images, or social media posts, both continue to grow as they are produced and consumed by various organizations.
Weve also added new citation metrics for the already-powerful RAG evaluation suite, including citation precision and citation coverage, to help you better assess how accurately your RAG system uses retrieved information. You must provide a knowledgeBaseIdentifier for every output. Fields marked with ? are optional.
In this post, we discuss how to use LLMs from Amazon Bedrock to not only extract text, but also understand information available in images. Solution overview In this post, we demonstrate how to use models on Amazon Bedrock to retrieve information from images, tables, and scanned documents. 90B Vision model.
Often support for metadata filtering alongside vector search Popular vector databases include FAISS (Facebook AI Similarity Search), Pinecone, Weaviate, Milvus, and Chroma. The language model generates a response informed by both its parameters and the retrieved information Benefits of RAG include: 1.
This comprehensive security setup addresses LLM10:2025 Unbound Consumption and LLM02:2025 Sensitive Information Disclosure, making sure that applications remain both resilient and secure. In the physical architecture diagram, the application controller is the LLM orchestrator AWS Lambda function.
Google Drive supports storing documents such as Emails contain a wealth of information found in different places, such as within the subject of an email, the message content, or even attachments. It can be tailored to specific business needs by connecting to company data, information, and systems through over 40 built-in connectors.
Amazon Bedrock offers fine-tuning capabilities that allow you to customize these pre-trained models using proprietary call transcript data, facilitating high accuracy and relevance without the need for extensive machine learning (ML) expertise. Architecture The following diagram illustrates the solution architecture.
Veritone’s current media search and retrieval system relies on keyword matching of metadata generated from ML services, including information related to faces, sentiment, and objects. We use the Amazon Titan Text and Multimodal Embeddings models to embed the metadata and the video frames and index them in OpenSearch Service.
Building ML infrastructure and integrating ML models with the larger business are major bottlenecks to AI adoption [1,2,3]. IBM Db2 can help solve these problems with its built-in ML infrastructure. Db2 Warehouse on cloud also supports these ML features.
Employees and managers see different levels of company policy information, with managers getting additional access to confidential data like performance review and compensation details. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses.
Retrieval Augmented Generation (RAG) represents a cutting-edge advancement in Artificial Intelligence, particularly in NLP and Information Retrieval (IR). This integration allows LLMs to perform more accurately and effectively in knowledge-intensive tasks, especially where proprietary or up-to-date information is crucial.
GPT3, LaMDA, PALM, BLOOM, and LLaMA are just a few examples of large language models (LLMs) that have demonstrated their ability to store and apply vast amounts of information. Finally, unlike image search engines, they do not examine the query image against a large corpus of images tagged with different metadata.
This approach has two primary shortcomings: Missed Contextual Signals : Without considering metadata such as source URLs, LMs overlook important contextual information that could guide their understanding of a texts intent or quality. MeCo leverages readily available metadata, such as source URLs, during the pre-training phase.
Real-world applications vary in inference requirements for their artificial intelligence and machine learning (AI/ML) solutions to optimize performance and reduce costs. SageMaker Model Monitor monitors the quality of SageMaker ML models in production. Your client applications invoke this endpoint to get inferences from the model.
By using synthetic data, enterprises can train AI models, conduct analyses, and develop applications without the risk of exposing sensitive information. Validation challenges Verifying the quality and representation of synthetic data often requires comparison with real data, which can be problematic when working with sensitive information.
It stores information such as job ID, status, creation time, and other metadata. The following is a screenshot of the DynamoDB table where you can track the job status and other types of metadata related to the job. The invoked Lambda function creates new job entries in a DynamoDB table with the status as Pending.
A main issue with PDF processing is that these documents store information optimally for visual presentation rather than logical reading order. This toolkit integrates text-based and visual information, allowing for superior extraction accuracy compared to conventional OCR methods.
These meetings often involve exchanging information and discussing actions that one or more parties must take after the session. This engine uses artificial intelligence (AI) and machine learning (ML) services and generative AI on AWS to extract transcripts, produce a summary, and provide a sentiment for the call.
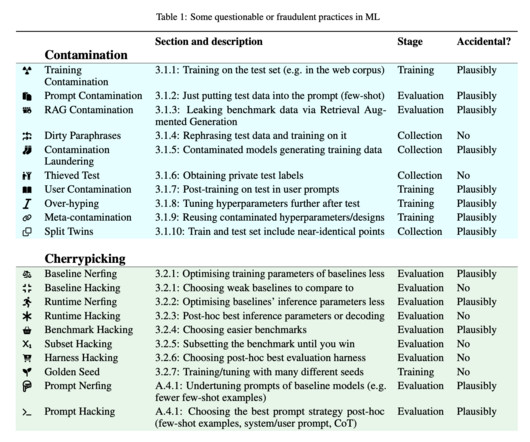
These methods have the potential to greatly exaggerate published results, deceiving the scientific community and the general public about the actual effectiveness of ML models. Due to the intricacy of ML research, which includes pre-training, post-training, and evaluation stages, there is much potential for QRPs. Check out the Paper.
To serve their customers, Vitech maintains a repository of information that includes product documentation (user guides, standard operating procedures, runbooks), which is currently scattered across multiple internal platforms (for example, Confluence sites and SharePoint folders). langsmith==0.0.43 pgvector==0.2.3 streamlit==1.28.0
Large language models (LLMs) have unlocked new possibilities for extracting information from unstructured text data. SageMaker JumpStart is a machine learning (ML) hub with foundation models (FMs), built-in algorithms, and prebuilt ML solutions that you can deploy with just a few clicks.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries.
In today’s information-rich world, finding relevant documents quickly is crucial. print("-" * 50) interactive_search() Let’s add the ability to filter our search results by metadata: Copy Code Copied Use a different Browser def filtered_search(query, filter_source=None, n_results=5): """ Search with optional filtering by source.
Regular interval evaluation also allows organizations to stay informed about the latest advancements, making informed decisions about upgrading or switching models. SageMaker is a data, analytics, and AI/ML platform, which we will use in conjunction with FMEval to streamline the evaluation process.
There are two metrics used to evaluate retrieval: Context relevance Evaluates whether the retrieved information directly addresses the querys intent. It requires ground truth texts for comparison to assess recall and completeness of retrieved information. Implement metadata filtering , adding contextual layers to chunk retrieval.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content