This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One effective way to improve context relevance is through metadata filtering, which allows you to refine search results by pre-filtering the vector store based on custom metadata attributes. By combining the capabilities of LLM function calling and Pydantic data models, you can dynamically extract metadata from user queries.
It also provides developers with greater control over the LLMs outputs, including the ability to include citations and manage sensitive information. These metadata filters can be used in combination with the typical semantic (or hybrid) similarity search. The user_data fields must match the metadata fields.
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
Introduction to LAION-DISCO-12M To address this gap, LAION AI has released LAION-DISCO-12M—a collection of 12 million links to publicly available YouTube samples, paired with metadata designed to support foundational machine learning research in audio and music.
If we log in to the VSI, we can see the volume disks: [root@test-metadata ~]# ls -la /dev/disk/by-id total 0 drwxr-xr-x. vdb If we want to find the data volume named test-metadata-volume , we see that it is the vdd disk. Recently, IBM Cloud VPC introduced the metadata service. 2 root root 200 Apr 7 12:58. drwxr-xr-x.
However, we can improve the system’s accuracy by leveraging contextual information. Any type of contextual information, like device context, conversational context, and metadata, […]. The post Underlying Engineering Behind Alexa’s Contextual ASR appeared first on Analytics Vidhya.
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data. Generate metadata for the page.
OpenAI is joining the Coalition for Content Provenance and Authenticity (C2PA) steering committee and will integrate the open standard’s metadata into its generative AI models to increase transparency around generated content.
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Furthermore, it might contain sensitive data or personally identifiable information (PII) requiring redaction.
Knowledge bases effectively bridge the gap between the broad knowledge encapsulated within foundation models and the specialized, domain-specific information that businesses possess, enabling a truly customized and valuable generative artificial intelligence (AI) experience.
The evolution of Large Language Models (LLMs) allowed for the next level of understanding and information extraction that classical NLP algorithms struggle with. This article will focus on LLM capabilities to extract meaningful metadata from product reviews, specifically using OpenAI API. Just in case they are present in your dataset.
To equip FMs with up-to-date and proprietary information, organizations use Retrieval Augmented Generation (RAG), a technique that fetches data from company data sources and enriches the prompt to provide more relevant and accurate responses. However, information about one dataset can be in another dataset, called metadata.
To refine the search results, you can filter based on document metadata to improve retrieval accuracy, which in turn leads to more relevant FM generations aligned with your interests. With this feature, you can now supply a custom metadata file (each up to 10 KB) for each document in the knowledge base. Virginia) and US West (Oregon).
Cisco’s 2024 Data Privacy Benchmark Study revealed that 48% of employees admit to entering non-public company information into GenAI tools (and an unknown number have done so and won’t admit it), leading 27% of organisations to ban the use of such tools. The best way to reduce the risks is to limit access to sensitive data.
Amazon Q Business is a generative AI -powered assistant that can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems. For information, refer to Amazon Q Business pricing. At least one Amazon Q Business user is required.
Solution overview By combining the powerful vector search capabilities of OpenSearch Service with the access control features provided by Amazon Cognito , this solution enables organizations to manage access controls based on custom user attributes and document metadata. For more information, see Getting started with the AWS CDK.
These datasets encompass millions of hours of music, over 10 million recordings and compositions accompanied by comprehensive metadata, including key, tempo, instrumentation, keywords, moods, energies, chords, and more, facilitating training and commercial usage. GCX provides datasets with over 4.4
These applications leverage AI tasks such as object detection, segmentation, video metadata and re-identification to rapidly and accurately identify legitimate vs. suspicious or abnormal people or behavior and trigger responses in real time. The most common AI use cases in surveillance systems include perimeter protection and access control.
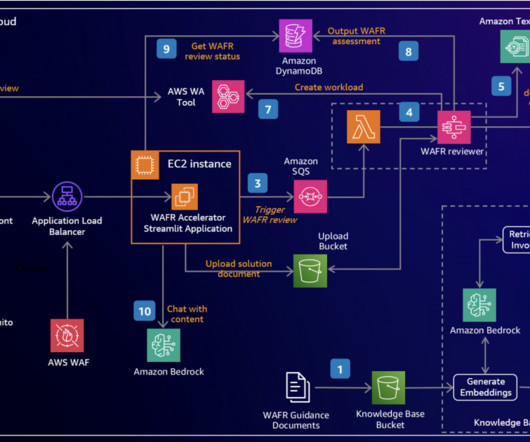
Integration with the AWS Well-Architected Tool pre-populates workload information and initial assessment responses. Metadata filtering is used to improve retrieval accuracy. The WAFR Accelerator application retrieves the review status from the DynamoDB table to keep the user informed.
Veritone’s current media search and retrieval system relies on keyword matching of metadata generated from ML services, including information related to faces, sentiment, and objects. We use the Amazon Titan Text and Multimodal Embeddings models to embed the metadata and the video frames and index them in OpenSearch Service.
This solution uses decorators in your application code to capture and log metadata such as input prompts, output results, run time, and custom metadata, offering enhanced security, ease of use, flexibility, and integration with native AWS services.
Often support for metadata filtering alongside vector search Popular vector databases include FAISS (Facebook AI Similarity Search), Pinecone, Weaviate, Milvus, and Chroma. The language model generates a response informed by both its parameters and the retrieved information Benefits of RAG include: 1.
Verisk (Nasdaq: VRSK) is a leading strategic data analytics and technology partner to the global insurance industry, empowering clients to strengthen operating efficiency, improve underwriting and claims outcomes, combat fraud, and make informed decisions about global risks.
We provide additional information later in this post. For more information about the architecture in detail, refer to Part 1 of this series. Data engineers contribute to the data lineage process by providing the necessary information and metadata about the data transformations they perform.
In an advisory issued by India’s Ministry of Electronics and Information Technology (MeitY) last Friday, it was declared that any AI technology still in development must acquire explicit government permission before being released to the public.
Generative models are prone to “hallucination”, meaning they can produce incorrect or misleading information if they lack the correct context or are fed noisy data. This is valuable in the context of RAG because it ensures that the generative model has access to high-quality, contextually appropriate information.
With so many converging factors, aggregating and assessing this information can be confusing and convoluted, which in some cases can lead to suboptimal decisions on trial sites.
This comprehensive security setup addresses LLM10:2025 Unbound Consumption and LLM02:2025 Sensitive Information Disclosure, making sure that applications remain both resilient and secure. In the physical architecture diagram, the application controller is the LLM orchestrator AWS Lambda function.
An AI-native data abstraction layer acts as a controlled gateway, ensuring your LLMs only access relevant information and follow proper security protocols. It can also enable consistent access to metadata and context no matter what models you are using. A well nourished semantic layer can significantly reduce LLM hallucinations..
Todays organizations face a critical challenge with the fragmentation of vital information across multiple environments. This solution helps streamline information retrieval, enhance collaboration, and significantly boost overall operational efficiency, offering a glimpse into the future of intelligent enterprise information management.
This approach has two primary shortcomings: Missed Contextual Signals : Without considering metadata such as source URLs, LMs overlook important contextual information that could guide their understanding of a texts intent or quality. MeCo leverages readily available metadata, such as source URLs, during the pre-training phase.
The metadata contains the full JSON response of our API with more meta information: print(docs[0].metadata) The metadata needs to be smaller than the text chunk size, and since it contains the full JSON response with extra information, it is quite large. print(docs[0].text) text) # Runner's knee.
In this post, we discuss how to use LLMs from Amazon Bedrock to not only extract text, but also understand information available in images. Solution overview In this post, we demonstrate how to use models on Amazon Bedrock to retrieve information from images, tables, and scanned documents. 90B Vision model.
The platform automatically analyzes metadata to locate and label structured data without moving or altering it, adding semantic meaning and aligning definitions to ensure clarity and transparency. When onboarding customers, we automatically retrain these ontologies on their metadata.
In a world whereaccording to Gartner over 80% of enterprise data is unstructured, enterprises need a better way to extract meaningful information to fuel innovation. This is particularly valuable for industries handling large document volumes, where rapid access to specific information is crucial.
in Information Systems Engineering from Ben Gurion University and an MBA from the Technion, Israel Institute of Technology. Along the way, I’ve learned different best practices – from how to manage a team to how to inform the proper strategy – that have shaped how I lead at Deep Instinct. He holds a B.Sc
Large language models (LLMs) have unlocked new possibilities for extracting information from unstructured text data. This post walks through examples of building information extraction use cases by combining LLMs with prompt engineering and frameworks such as LangChain.
By linking this contextual information, the generative AI system can provide responses that are more complete, precise, and grounded in source data. GraphRAG boosts relevance and accuracy when relevant information is dispersed across multiple sources or documents, which can be seen in the following three use cases.
To serve their customers, Vitech maintains a repository of information that includes product documentation (user guides, standard operating procedures, runbooks), which is currently scattered across multiple internal platforms (for example, Confluence sites and SharePoint folders). langsmith==0.0.43 pgvector==0.2.3 streamlit==1.28.0
These indexes enable efficient searching and retrieval of part data and vehicle information, providing quick and accurate results. The agents also automatically call APIs to perform actions and access knowledge bases to provide additional information. The embeddings are stored in the Amazon OpenSearch Service owner manuals index.
A main issue with PDF processing is that these documents store information optimally for visual presentation rather than logical reading order. This toolkit integrates text-based and visual information, allowing for superior extraction accuracy compared to conventional OCR methods.
It stores information such as job ID, status, creation time, and other metadata. The following is a screenshot of the DynamoDB table where you can track the job status and other types of metadata related to the job. The invoked Lambda function creates new job entries in a DynamoDB table with the status as Pending.
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according to a preset data model. Unstructured information may have a little or a lot of structure but in ways that are unexpected or inconsistent. A metadata layer helps build the relationship between the raw data and AI extracted output.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content