This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Photo by Will Truettner on Unsplash NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 07.26.20 GitHub: Tencent/TurboTransformers Make transformers serving fast by adding a turbo to your inferenceengine!Transformer These 2 repos encompass NLP and Speech modeling.
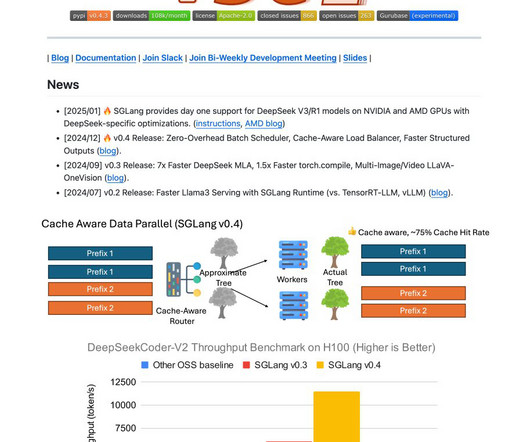
SGLang is an open-source inferenceengine designed by the SGLang team to address these challenges. It optimizes CPU and GPU resources during inference, achieving significantly higher throughput than many competitive solutions. Several high-profile companies have recognized SGLangs practical benefits.
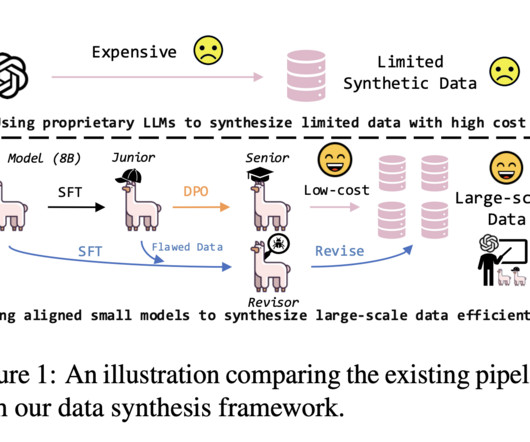
The data was curated from over 250 million tokens gathered from publicly available sources and mixed with instruction sets on coding, general knowledge, NLP, and conversational dialogue to retain original knowledge. Hawkish 8B directly addresses the needs of financial professionals and researchers.
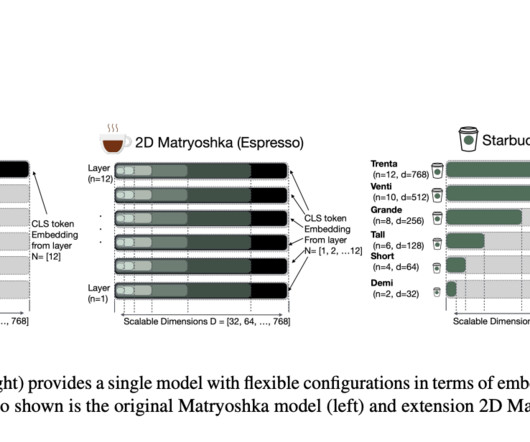
These conventional methods exhibit significant limitations, including poor integration of model dimensions and layers, which leads to diminished performance in complex NLP tasks. Substantial evaluation of broad datasets has validated the robustness and effectiveness of the Starbucks method for a wide range of NLP tasks.
Artificial intelligence (AI) is making significant strides in natural language processing (NLP), focusing on enhancing models that can accurately interpret and generate human language. A major issue facing NLP is sustaining coherence over long texts. In experiments, this model demonstrated marked improvements across various benchmarks.
NVIDIA Inference Microservices (NIM) and LangChain are two cutting-edge technologies that meet these needs, offering a comprehensive solution for deploying AI in real-world environments. Understanding NVIDIA NIM NVIDIA NIM, or NVIDIA Inference Microservices, is simplifying the process of deploying AI models.
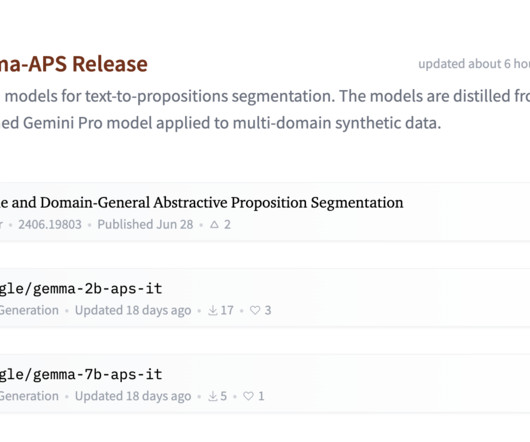
This capability is particularly critical in improving language models used for summarization, information retrieval, and various other NLP tasks. In this landscape, the demand for models capable of breaking down intricate pieces of text into manageable, proposition-level components has never been more pronounced.
Generative Large Language Models (LLMs) are well known for their remarkable performance in a variety of tasks, including complex Natural Language Processing (NLP), creative writing, question answering, and code generation. The team has shared that PowerInfer is a GPU-CPU hybrid inferenceengine that makes use of this understanding.
We are delighted to announce the release of Spark NLP 5.0, We are delighted to announce the release of Spark NLP 5.0, Additionally, we are also set to release an array of new LLM models fine-tuned specifically for chat and instruction, now that we have successfully integrated ONNX Runtime into Spark NLP.
Considering the major influence of autoregressive ( AR ) generative models, such as Large Language Models in natural language processing ( NLP ), it’s interesting to explore whether similar approaches can work for images. If you like our work, you will love our newsletter. Don’t Forget to join our 55k+ ML SubReddit.
These systems rely on a domain knowledge base and an inferenceengine to solve specialized medical problems. AI is also revolutionizing Electronic Health Records (EHRs) by using techniques like RNN and NLP to analyze structured and unstructured data, aiding in risk prediction for conditions like hypertension and cardiac arrest.
The models are trained on over 12 trillion tokens across 12 languages and 116 programming languages, providing a versatile base for natural language processing (NLP) tasks and ensuring privacy and security. delivers powerful NLP features in a secure and transparent manner. If you like our work, you will love our newsletter.
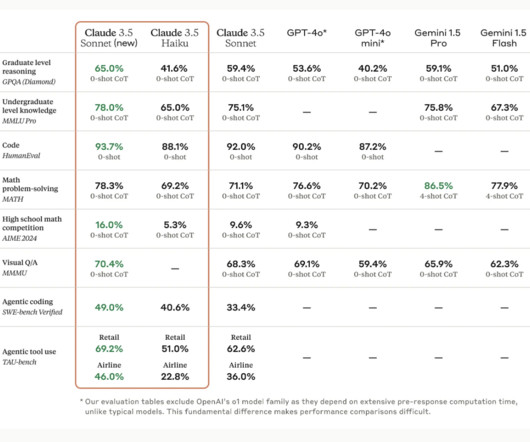
by generating elegant and articulate poetry in structured forms, demonstrating a powerful synergy of natural language processing (NLP) and creative AI. The technical backbone of Anthropic AI’s computer use feature is bridging NLP with autonomous software interaction. This capability allows Claude 3.5
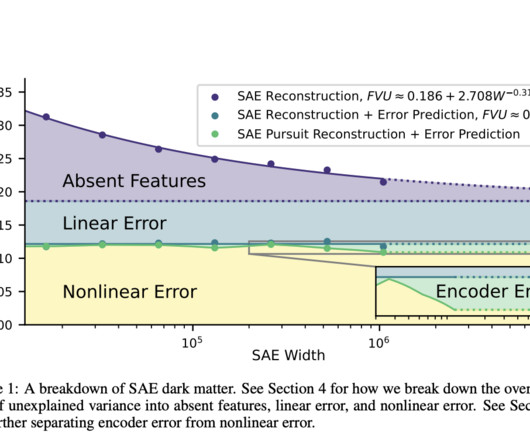
Sparse autoencoders have been benchmarked for error rates using human analysis, geometry visualizations, and NLP tasks. This idea is supported by work using sparse autoencoders and dimensionality reduction, but recent studies have raised doubts, showing non-linear or multidimensional representations in models like Mistral and Llama.
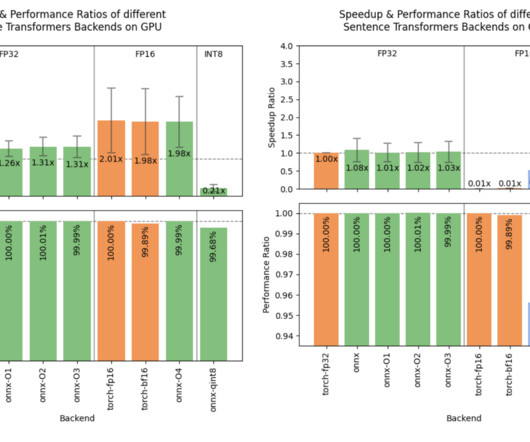
The expanded compatibility with the Hugging Face Transformers library allows for easy use of more pretrained models, providing added flexibility for various NLP applications. The OpenVINO backend, which uses Intel’s OpenVINO toolkit, outperforms ONNX in some situations on the CPU. If you like our work, you will love our newsletter.
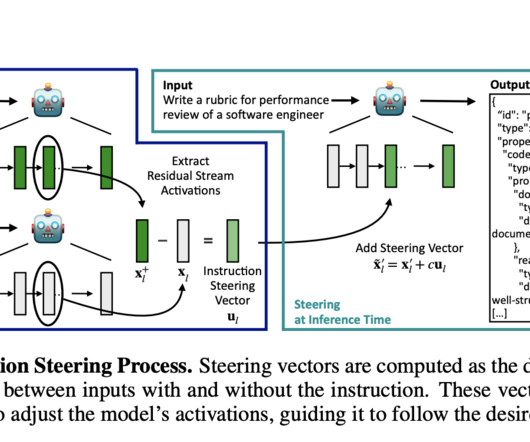
In conclusion, the research presents a significant advancement in the field of NLP by providing a scalable, flexible solution to improve instruction-following in language models. This transferability suggests that activation steering can enhance a broader range of models across different applications, making the method highly versatile.
Overall, TensorRT’s combination of techniques results in faster inference and lower latency compared to other inferenceengines. The TensorRT backend for Triton Inference Server is designed to take advantage of the powerful inference capabilities of NVIDIA GPUs. trtexec —onnx=model.onnx —saveEngine=model_bs16.plan
It uses formal languages, like first-order logic, to represent knowledge and an inferenceengine to draw logical conclusions based on user queries. This pattern recognition capability allows neural networks to perform tasks like image classification , object detection , and predicting the next word in NLP. Symbolic AI Mechanism.
John on Patmos | Correggio NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER The NLP Cypher | 02.14.21 DeepSparse: a CPU inferenceengine for sparse models. Sparsify: a UI interface to optimize deep neural networks for better inference performance. The Vision of St. Heartbreaker Hey Welcome back!
John on Patmos | Correggio NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER The NLP Cypher | 02.14.21 DeepSparse: a CPU inferenceengine for sparse models. Sparsify: a UI interface to optimize deep neural networks for better inference performance. The Vision of St. Heartbreaker Hey Welcome back!
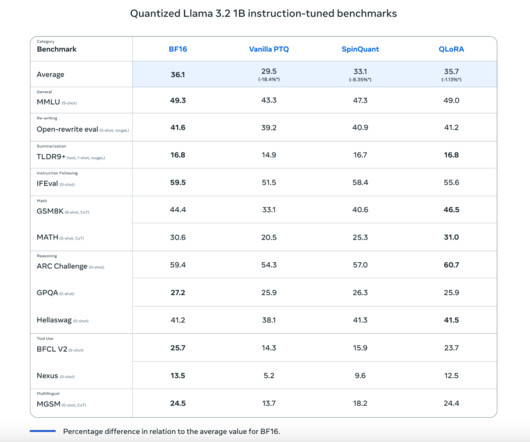
This quantization approach retains the critical features and capabilities of Llama 3, such as its ability to perform advanced natural language processing (NLP) tasks, while making the models much more lightweight. The benefits are clear: Quantized Llama 3.2 Early benchmarking results indicate that Quantized Llama 3.2
This approach not only aids those directly involved in NLP research but also democratizes access to tools for large-scale model training, providing a valuable resource for those looking to experiment without overwhelming technical barriers. If you like our work, you will love our newsletter. Don’t Forget to join our 50k+ ML SubReddit.
Text embedding, a central focus within natural language processing (NLP), transforms text into numerical vectors capturing the essential meaning of words or phrases. The SPEED framework offers a practical, cost-effective alternative for the NLP community. For example, SPEED’s performance reached 78.4 in clustering, 88.2
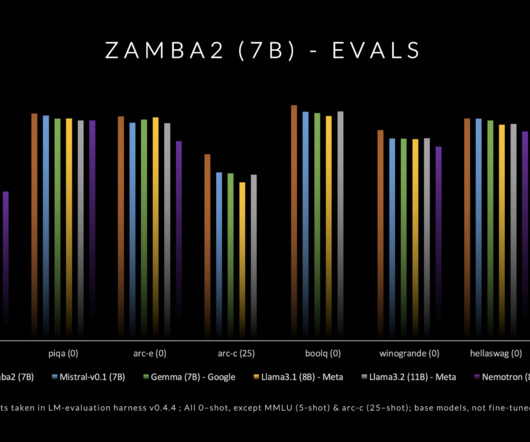
By blending innovative architectural improvements with efficient training techniques, Zyphra has succeeded in creating a model that is not only accessible but also highly capable of meeting a variety of NLP needs. If you like our work, you will love our newsletter. Don’t Forget to join our 50k+ ML SubReddit.
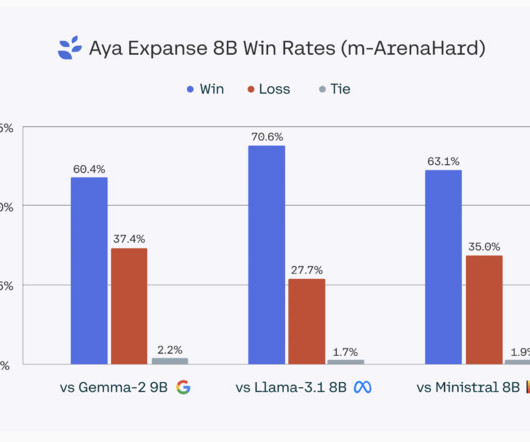
Most progress in natural language processing (NLP) has focused on well-resourced languages like English, leaving many others underrepresented. In conclusion, Aya Expanse represents a significant step towards democratizing AI and addressing the language gap in NLP. If you like our work, you will love our newsletter.
Even the NLP models struggle to understand nuances in language, cultural differences, and the context of conversations. These models are trained on data collected from social media, which introduces bias and may not accurately represent diverse patient experiences. If you like our work, you will love our newsletter.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content