This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
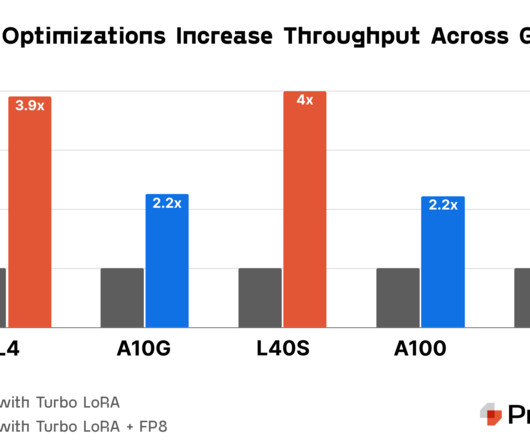
Dynamo can also offload inference data to more cost-effective memory and storage devices while retrieving it rapidly when required, thereby minimising overall inference costs. Together AI , a prominent player in the AI Acceleration Cloud space, is also looking to integrate its proprietary Together InferenceEngine with NVIDIA Dynamo.
Predibase announces the Predibase InferenceEngine , their new infrastructure offering designed to be the best platform for serving fine-tuned small language models (SLMs). The Predibase InferenceEngine addresses these challenges head-on, offering a tailor-made solution for enterprise AI deployments.
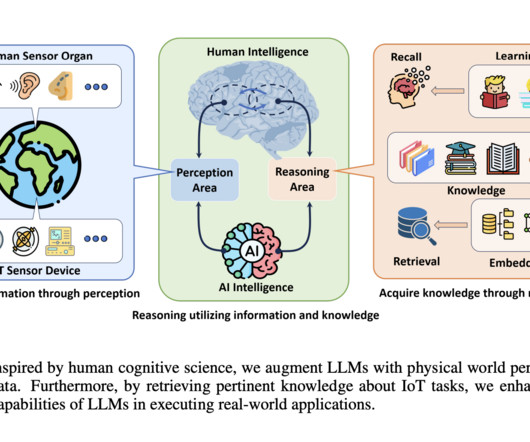
MARS Lab, NTU has devised an innovative IoT-LLM framework that combats the limitations of the LLM in handling real-world tasks. For example, in traditional LLMs like Chat-GPT 4, only 40% accuracy in activity recognition and 50% in machine diagnosis are achieved after processing the raw IoT data.
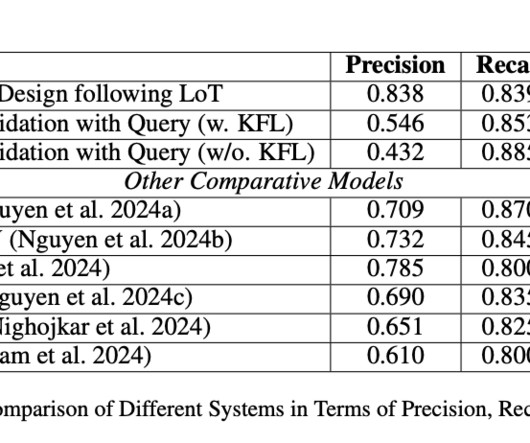
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Layer-of-Thoughts Prompting (LoT): A Unique Approach that Uses Large Language Model (LLM) based Retrieval with Constraint Hierarchies appeared first on MarkTechPost.
Researchers from Google Cloud AI, Google DeepMind, and the University of Washington have proposed a new approach called MODEL SWARMS , which utilizes swarm intelligence to adapt LLMs through collaborative search in the weight space. The research demonstrated superior results for both single-task adaptation and multi-task domains.
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post Stanford Researchers Propose LoLCATS: A Cutting Edge AI Method for Efficient LLM Linearization appeared first on MarkTechPost. If you like our work, you will love our newsletter.
Research on the robustness of LLMs to jailbreak attacks has mostly focused on chatbot applications, where users manipulate prompts to bypass safety measures. However, LLM agents, which utilize external tools and perform multi-step tasks, pose a greater misuse risk, especially in malicious contexts like ordering illegal materials.
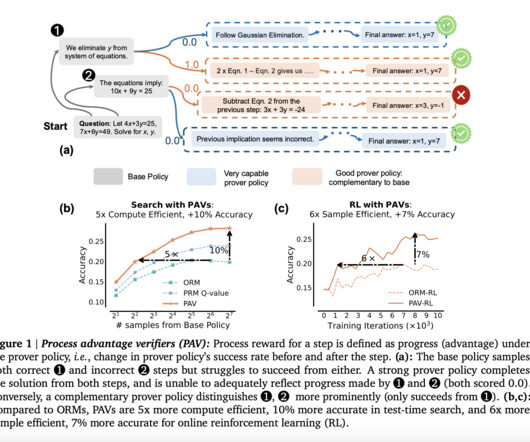
The key innovation in PAVs is using a “prover policy,” distinct from the base policy that the LLM is following. This enables the LLM to explore a wider range of potential solutions, even when early steps do not immediately lead to a correct solution. Check out the Paper. If you like our work, you will love our newsletter.
Specifically, while LLMs are becoming capable of handling longer input sequences, the increase in retrieved information can overwhelm the system. The challenge lies in making sure that the additional context improves the accuracy of the LLM’s outputs rather than confusing the model with irrelevant information.
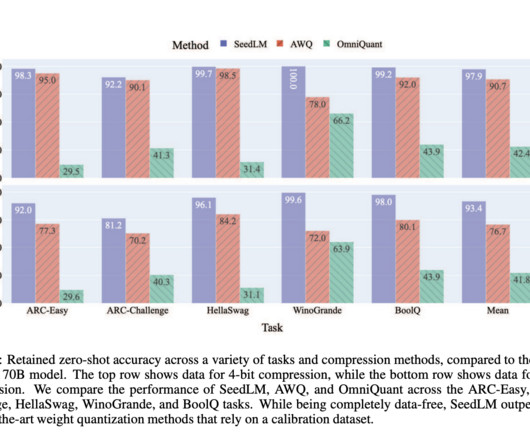
The key problem, therefore, is how to effectively compress LLM weights without sacrificing accuracy or requiring calibration data. Researchers from Apple and Meta AI introduce SeedLM, a novel approach that aims to overcome the challenges associated with the deployment of large-scale LLMs by providing a data-free compression method.
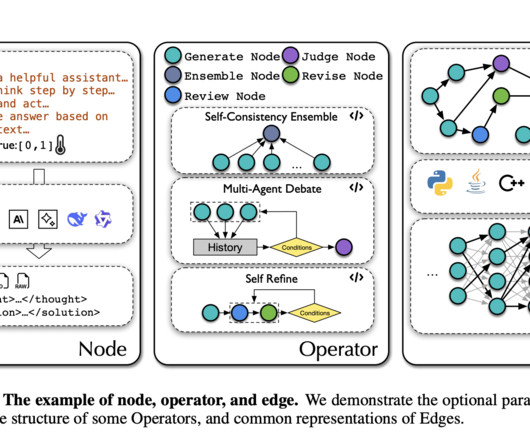
These workflows are modeled as graphs where nodes represent LLM-invoking actions, and edges represent the dependencies between these actions. The key to AFlow’s efficiency lies in its use of nodes and edges to represent workflows, allowing it to model complex relationships between LLM actions.
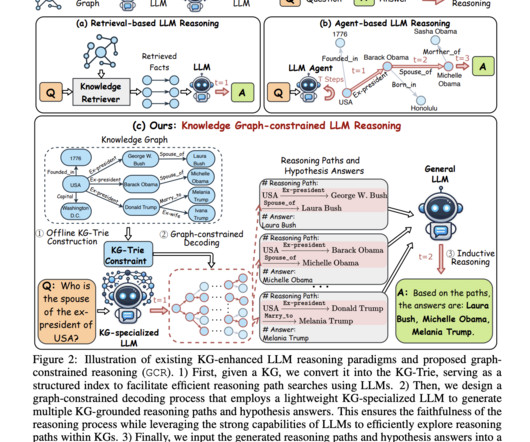
Large language models (LLMs) have demonstrated significant reasoning capabilities, yet they face issues like hallucinations and the inability to conduct faithful reasoning. GCR introduces a trie-based index named KG-Trie to integrate KG structures directly into the LLM decoding process. Don’t Forget to join our 50k+ ML SubReddit.
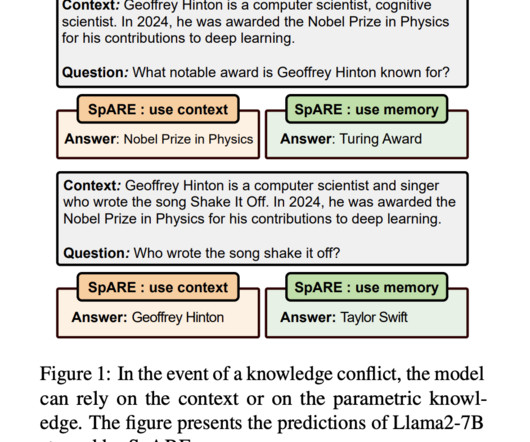
LLMs prefer contextual knowledge over their parametric knowledge, but during conflicts, existing solutions that need additional model interactions result in high latency times, making them impractical for real-world applications. Representation engineering emerged as a higher-level framework for understanding LLM behavior at scale.
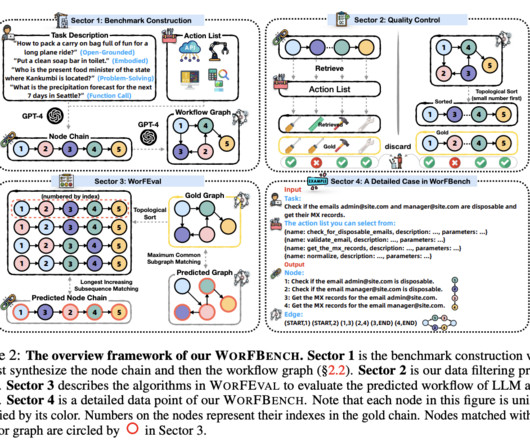
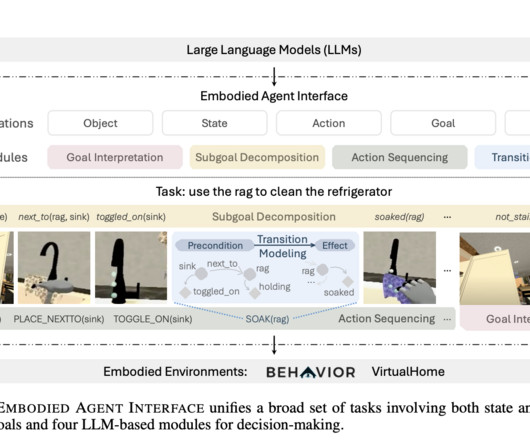
Large Language Models (LLMs) have shown remarkable potential in solving complex real-world problems, from function calls to embodied planning and code generation. Researchers from Zhejiang University and Alibaba Group have proposed WORFBENCH, a benchmark for evaluating workflow generation capabilities in LLM agents.
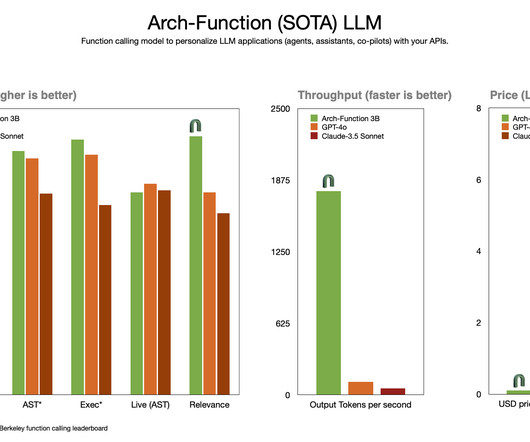
Katanemo’s Arch-Function transforms workflow automation by simplifying LLM deployment and reducing engineering overhead, making it accessible even for smaller enterprises. Arch-Function is optimized for speed and precision, completing tasks in minutes that previously took hours while effectively adapting to dynamic requirements.
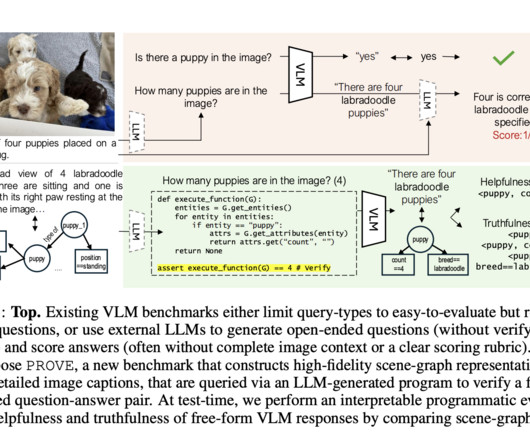
In PROVE, researchers use a high-fidelity scene graph representation constructed from hyper-detailed image captions and employ a large language model (LLM) to generate diverse question-answer (QA) pairs along with executable programs to verify each QA pair. This approach allows the creation of a benchmark dataset of 10.5k
Large language models (LLMs) like GPT-4, Gemini, and Llama 3 have revolutionized natural language processing through extensive pre-training and supervised fine-tuning (SFT). However, these models come with high computational costs for training and inference. Check out the Paper. If you like our work, you will love our newsletter.
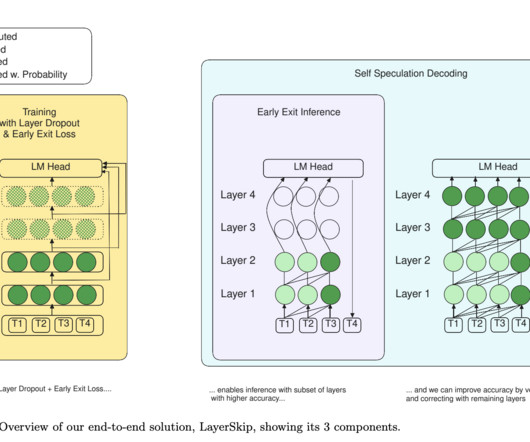
By combining layer dropout, early exit loss, and self-speculative decoding, the researchers have proposed a novel approach that not only speeds up inference but also reduces memory requirements, making it feasible for large models to be deployed on commodity hardware. Check out the Paper , Model Series on Hugging Face , and GitHub.
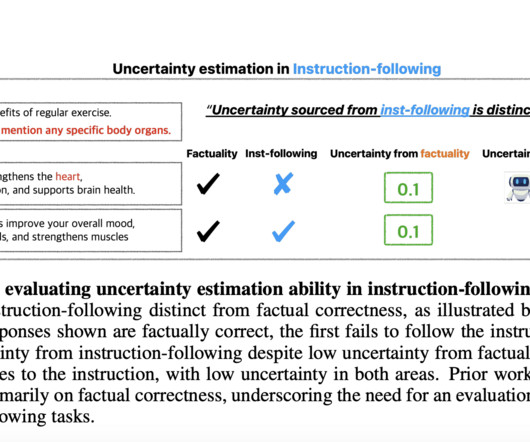
In light of these drawbacks, a trustworthy technique for determining when and how an LLM may be unsure about its capacity to follow directions is necessary to reduce the dangers involved with using these models. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
Task superposition means that when an LLM is provided relevant examples for each task within the same input prompt, it can process and produce responses for several tasks at once. The team has shared their primary contributions as follows. Llama-3, and Qwen. If you like our work, you will love our newsletter.
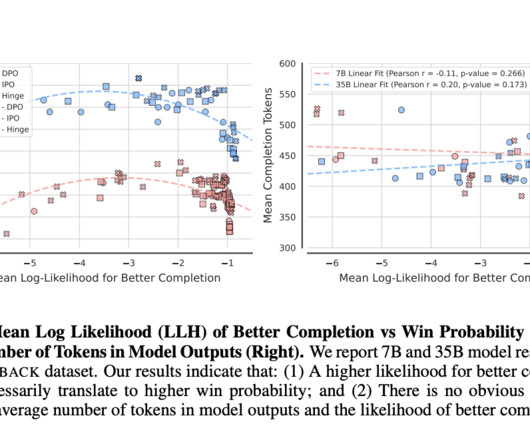
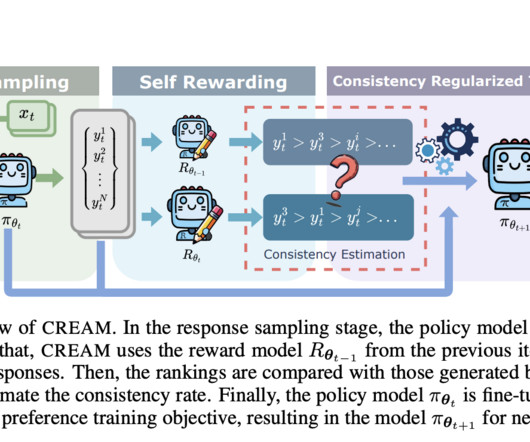
The study also employed regularization schemes like Negative Log-Likelihood (NLL) to mitigate over-optimization and evaluated generalization performance using LLM-as-a-Judge, a framework for comparing model outputs with those from other leading models. If you like our work, you will love our newsletter.
Recent advancements in LLM capabilities have increased their usability by enabling them to do a broader range of general activities autonomously. There are two main obstacles to effective LM program utilization: The non-deterministic character of LLMs makes programming LM programs tedious and complex.
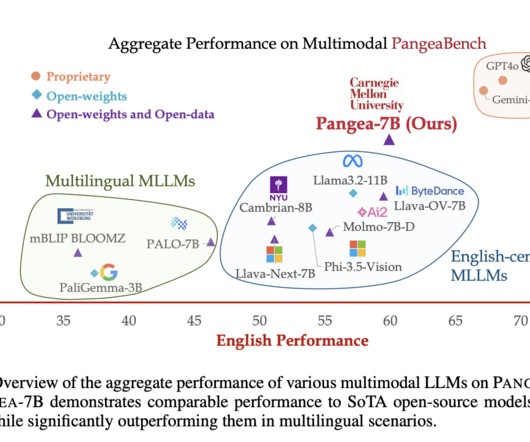
A team of researchers from Carnegie Mellon University introduced PANGEA, a multilingual multimodal LLM designed to bridge linguistic and cultural gaps in visual understanding tasks. PANGEA is trained on a newly curated dataset, PANGEAINS, which contains 6 million instruction samples across 39 languages.
The Attack Generation and Exploration Module uses an attacker LLM to generate jailbreak prompts based on strategies from the Retrieval Module. These prompts target a victim LLM, with responses evaluated by a scorer LLM. This process generates attack logs for the Strategy Library Construction Module.
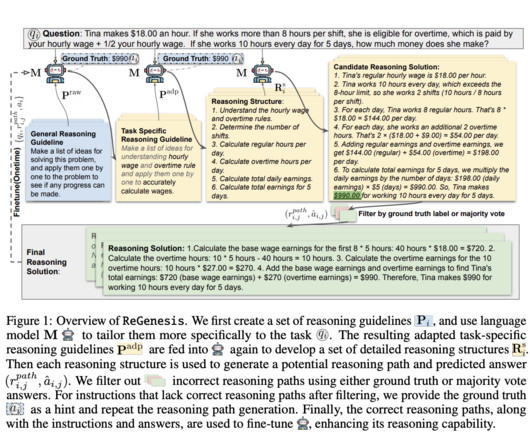
One of the critical problems faced by AI researchers is that many current methods for enhancing LLM reasoning capabilities rely heavily on human intervention. Finally, the LLM uses these reasoning structures to create detailed reasoning paths. If you like our work, you will love our newsletter.
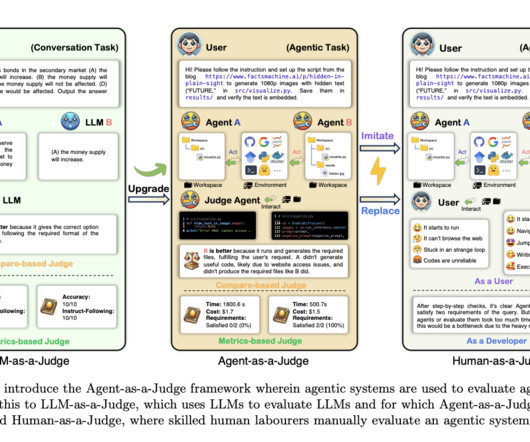
Current evaluation frameworks, such as LLM-as-a-Judge, which uses large language models to judge outputs from other AI systems, must account for the entire task-solving process. The results of the Agent-as-a-Judge framework achieved a 90% alignment with human evaluators, compared to LLM-as-a-Judge’s 70% alignment.
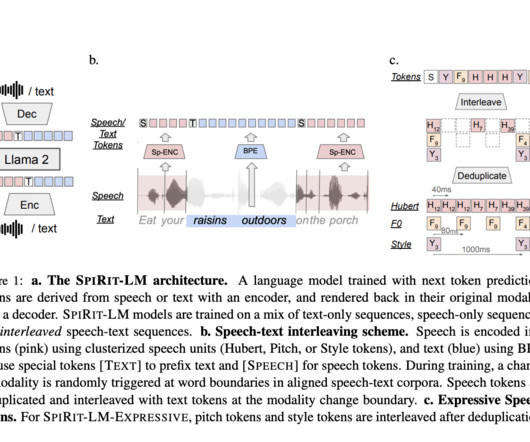
Traditionally, large language models (LLMs) used for building TTS pipelines convert speech to text using automatic speech recognition (ASR), process it using an LLM, and then convert the output back to speech via TTS. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
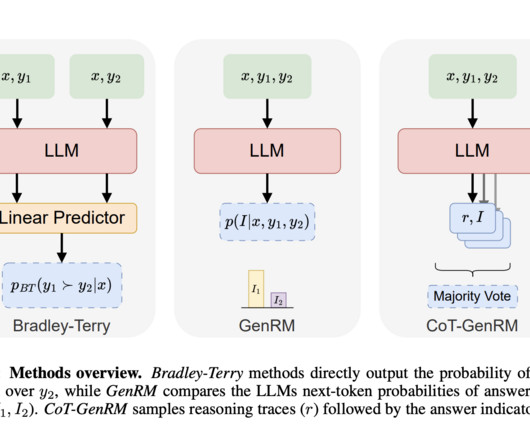
GenRM leverages a large pre-trained LLM to generate reasoning chains that help decision-making. The model also outperformed LLM-based judges, which rely solely on AI feedback, showcasing a more balanced approach to feedback optimization. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
This is indeed a very serious challenge for the larger and more effective scaling of LLM modalities applied to real-world applications. Current solutions to alignment involve methods such as RLHF and direct preference optimization (DPO). Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
Researchers from Westlake University and Zhejiang University introduced an omni-modal LLM Baichuan-Omni alongside a multimodal training scheme designed to facilitate advanced multimodal processing and better user interactions. It also provides multilingual support for languages such as English and Chinese.
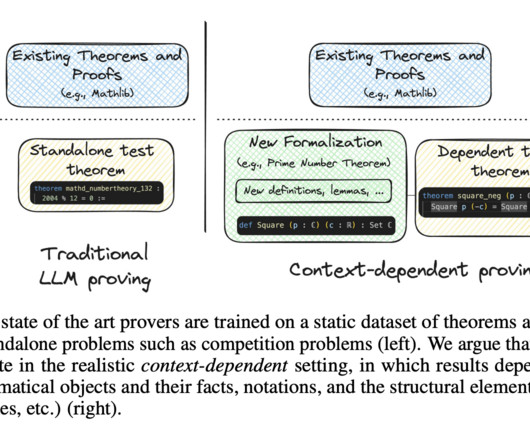
The disconnect between laboratory performance and practical applications raises concerns about the true effectiveness of LLM-based provers. Current methodologies often fail to capture the intricate nature of mathematical reasoning required in authentic theorem-proving scenarios, limiting their practical utility.
While alternative methods like large language model (LLM)-based encoders can handle longer sequences, they fail to provide the same level of alignment as contrastive pre-training encoders do. The growing popularity of diffusion models has been driven by advancements in fast sampling techniques and text-conditioned generation.
Methods for testing reasoning capabilities include datasets like GSM8k, which contains arithmetic word problems that test LLMs on basic to intermediate logic tasks. However, these benchmarks must be revised to push the limits of LLM reasoning, as they often contain repetitive patterns and need more variety in problem structures.
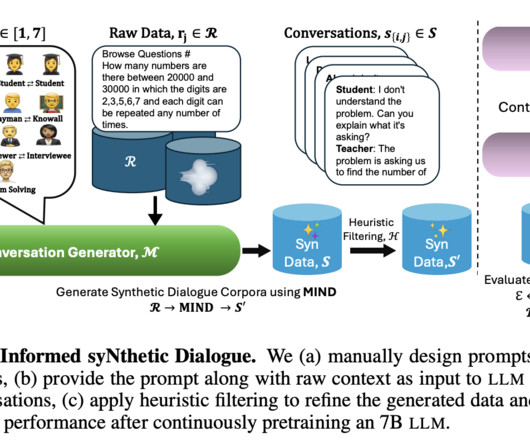
The technology behind MIND works by prompting an LLM with a raw text from OpenWebMath and instructing it to break down the problem into a series of conversational turns. Each conversation style contributes to decomposing a mathematical problem into its core components, allowing the model to focus on each part in a detailed and logical manner.
These methods rely on predefined rules or LLM (Large Language Model) judgments to identify potential vulnerabilities in code. The second stage uses LLM-based mutators to generate large-scale data from these seed samples, preserving the original security context. These samples contain insecure and patched code and associated test cases.
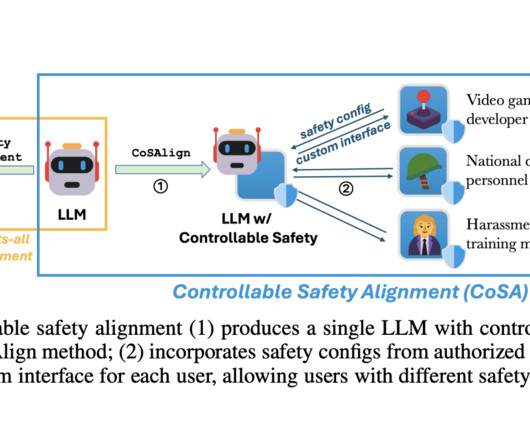
A team of researchers from Microsoft Responsible AI Research and Johns Hopkins University proposed Controllable Safety Alignment (CoSA) , a framework for efficient inference-time adaptation to diverse safety requirements. The adapted strategy first produces an LLM that is easily controllable for safety.
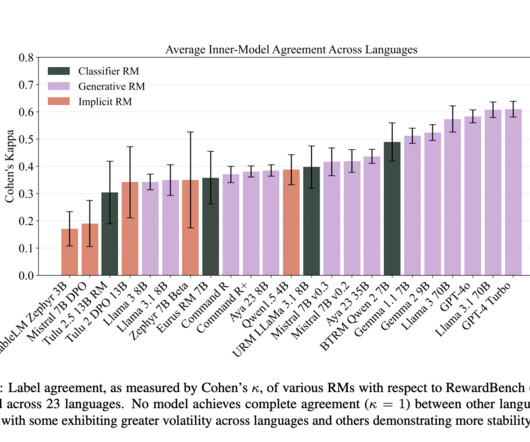
This adaptation is essential, given the global user base that increasingly relies on LLMs across diverse languages for various tasks, including everyday information, safety guidelines, and nuanced conversations. A core issue in LLM development lies in adapting RMs to perform consistently across different languages.
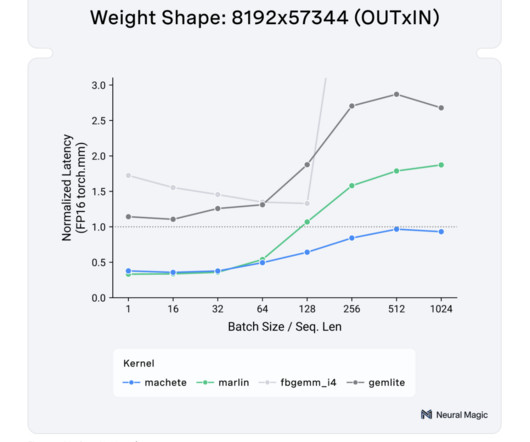
These problems are particularly noticeable when deploying LLMs on NVIDIA Hopper GPUs, as balancing memory usage and computational speed becomes more challenging. Neural Magic introduces Machete: a new mixed-input GEMM kernel for NVIDIA Hopper GPUs, representing a major advancement in high-performance LLMinference.
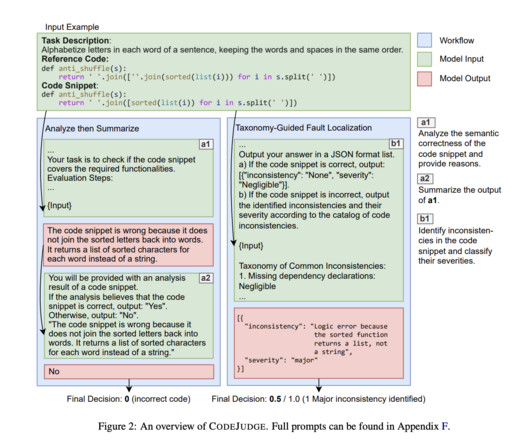
This research offers a valuable tool for improving the quality and reliability of LLM-generated code and streamlining software development workflows. This approach is quite comprehensive but provides a setback due to its dependence on predefined tests that limit the adaptability in unconventional coding styles. Check out the Paper.
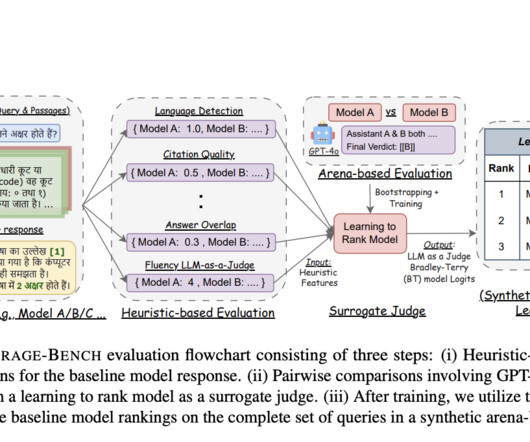
In RAG systems, an LLM creates a response based on the recovered content after a retrieval step in which pertinent information or passages are gathered. The second kind, known as arena-based benchmarks, uses a high-performance LLM as a teacher to evaluate model outputs through direct model comparisons in a setting akin to a competition.
SynPO is a self-boosting method that enhances LLM alignment without heavily depending on human annotations by creating synthetic data. Instead of relying on complicated datasets or outside human inputs, it makes use of the LLM itself to provide a range of cues that elicit various scenarios and replies. and ArenaHard.
Large Language Model (LLM)–based online agents have significantly advanced in recent times, resulting in unique designs and new benchmarks that show notable improvements in autonomous web navigation and interaction. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
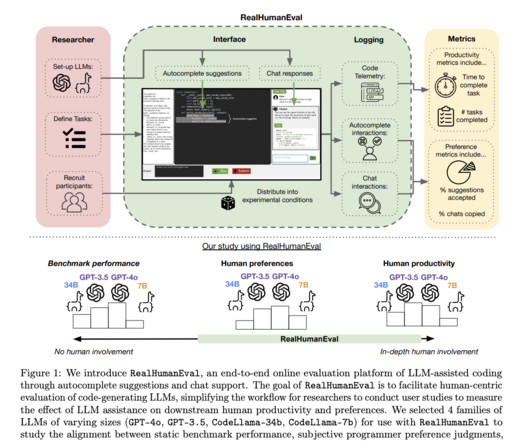
None of these traditional approaches capture key metrics, such as how much time programmers spend coding, how frequently programmers accept LLM suggestions or the degree to which LLMs actually help solve complex problems. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
A portion of this disparity might be attributed to the fact that LLMs have been used in various fields with various goals and input-output configurations. It is challenging for researchers to fine-tune the application of LLMs for particular jobs or contexts without this degree of information.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content