This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For AI and large language model (LLM) engineers , design patterns help build robust, scalable, and maintainable systems that handle complex workflows efficiently. This article dives into design patterns in Python, focusing on their relevance in AI and LLM -based systems. model inference, real-time updates).
Groq groq Groq is renowned for its high-performance AI inference technology. Their standout product, the Language Processing Units (LPU) InferenceEngine , combines specialized hardware and optimized software to deliver exceptional compute speed, quality, and energy efficiency. per million tokens.
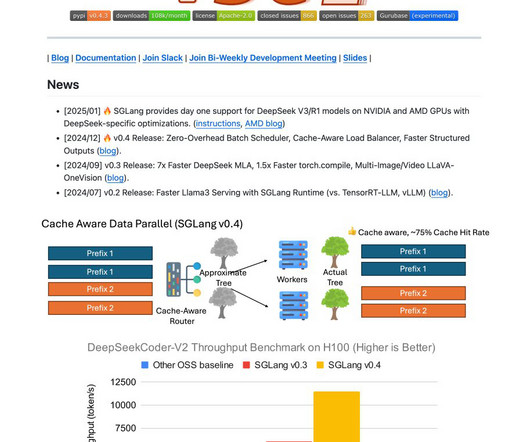
SGLang is an open-source inferenceengine designed by the SGLang team to address these challenges. It optimizes CPU and GPU resources during inference, achieving significantly higher throughput than many competitive solutions. RadixAttention is central to SGLang, which reuses shared prompt prefixes across multiple requests.
Researchers developed an efficient, scalable, and lightweight framework for LLMinference, LightLLM, to address the challenge of efficiently deploying LLMs in environments with limited computational resources, such as mobile devices, edge computing, and resource-constrained environments.
higher throughput compared to state-of-the-art inference systems on various large language and multimodal models, tackling tasks such as agent control, logical reasoning, few-shot learning benchmarks, JSON decoding, retrieval-augmented generation pipelines, and multi-turn chat. Experiments demonstrate that SGLang achieves up to 6.4×
For the ever-growing challenge of LLM validation, ReLM provides a competitive and generalized starting point. ReLM is the first solution that allows practitioners to directly measure LLM behavior over collections too vast to enumerate by describing a query as the whole set of test patterns.
Recent advancements in LLM capabilities have increased their usability by enabling them to do a broader range of general activities autonomously. There are two main obstacles to effective LM program utilization: The non-deterministic character of LLMs makes programming LM programs tedious and complex.
Accelerating LLMInference with NVIDIA TensorRT While GPUs have been instrumental in training LLMs, efficient inference is equally crucial for deploying these models in production environments. Setup Python Virtual Environment Ubuntu 22.04 comes with Python 3.10. Accelerating LLM Training with GPUs and CUDA.
One of the biggest challenges of using LLMs is the cost of accessing them. Many LLMs, such as OpenAI’s GPT-3, are only available through paid APIs. Learn how to deploy any open-source LLM as a free API endpoint using HuggingFace and Gradio. Many LLMs, such as OpenAI’s GPT-3, are only available through paid APIs.
Benefits of SLMs on Edge Devices In this section, we present three compelling reasons why companies may find Small Language Model (SLM) applications preferable to their cloud-heavy Large Language Model (LLM) counterparts: Cost Reduction The expense of cloud inference for Large Language Models can be prohibitive.
With this support, you can look forward to faster inference, automatic optimization, and quantization when exporting your LLM models. Additionally, we are also set to release an array of new LLM models fine-tuned specifically for chat and instruction, now that we have successfully integrated ONNX Runtime into Spark NLP.
🧑🔬 The LLM Scientist focuses on building the best possible LLMs using the latest techniques. 👷 The LLMEngineer focuses on creating LLM-based applications and deploying them. . 👷 The LLMEngineer focuses on creating LLM-based applications and deploying them.
In this post, we explore the new Container Caching feature for SageMaker inference, addressing the challenges of deploying and scaling large language models (LLMs). We discuss how this innovation significantly reduces container download and load times during scaling events, a major bottleneck in LLM and generative AI inference.
The use of large language models (LLMs) and generative AI has exploded over the last year. With the release of powerful publicly available foundation models, tools for training, fine tuning and hosting your own LLM have also become democratized. top_p=0.95) # Create an LLM. llm = LLM(model="meta-llama/Llama-3.2-1B",
Please join me at my ODSC workshop on Jan 15th for a deeper dive on turbo LoRA, as well as a few other innovative features of Predibases next-gen inferenceengine that collectively enhance the deployment ofSLMs. We made fine-tuning super easy but also flexible for advanced users to configure different settings.
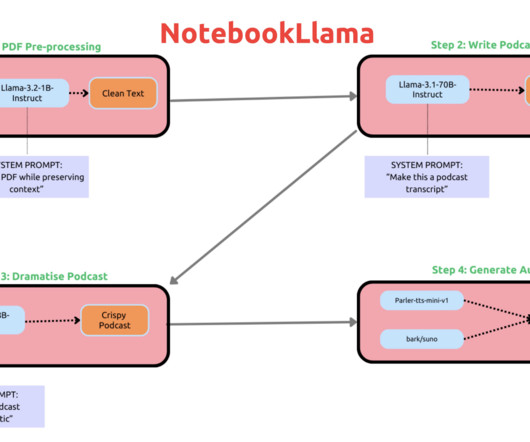
NotebookLlama integrates large language models directly into an open-source notebook interface, similar to Jupyter or Google Colab, allowing users to interact with a trained LLM as they would with any other cell in a notebook environment. If you like our work, you will love our newsletter. Don’t Forget to join our 55k+ ML SubReddit.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content