This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Generative Large Language Models (LLMs) are well known for their remarkable performance in a variety of tasks, including complex NaturalLanguageProcessing (NLP), creative writing, question answering, and code generation. Upon evaluation, PowerInfer has also shown that it has the capability to run up to 11.69
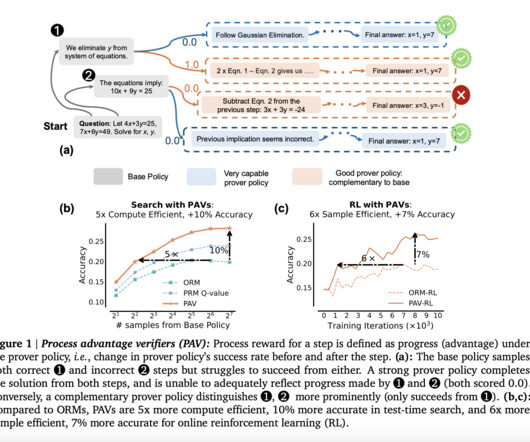
Large language models (LLMs) have become crucial in naturallanguageprocessing, particularly for solving complex reasoning tasks. However, while LLMs can process and generate responses based on vast amounts of data, improving their reasoning capabilities is an ongoing challenge. Check out the Paper.
The ever-increasing size of Large Language Models (LLMs) presents a significant challenge for practical deployment. Despite their transformative impact on naturallanguageprocessing, these models are often hindered by high memory transfer requirements, which pose a bottleneck during autoregressive generation.
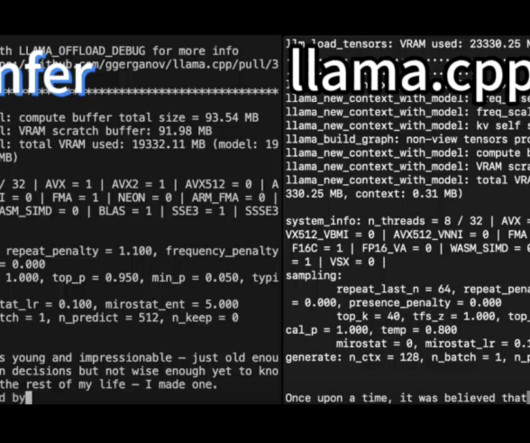
In this article, we will discuss PowerInfer, a high-speed LLMinferenceengine designed for standard computers powered by a single consumer-grade GPU. The PowerInfer framework seeks to utilize the high locality inherent in LLMinference, characterized by a power-law distribution in neuron activations.
NVIDIA Inference Microservices (NIM) and LangChain are two cutting-edge technologies that meet these needs, offering a comprehensive solution for deploying AI in real-world environments. Understanding NVIDIA NIM NVIDIA NIM, or NVIDIA Inference Microservices, is simplifying the process of deploying AI models.
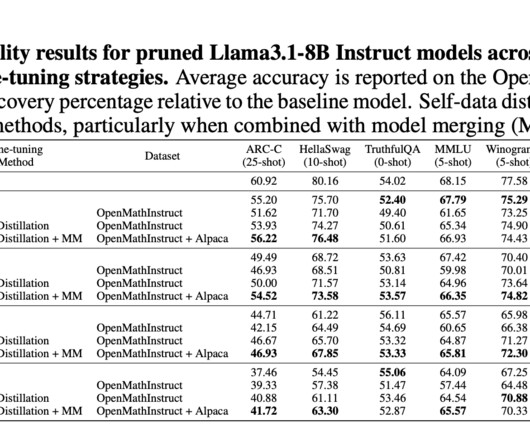
Large language models (LLMs) like GPT-4, Gemini, and Llama 3 have revolutionized naturallanguageprocessing through extensive pre-training and supervised fine-tuning (SFT). However, these models come with high computational costs for training and inference. Check out the Paper.
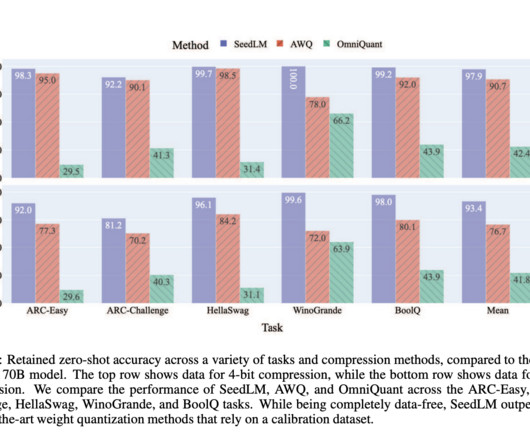
LLMs such as LLaMA, MAP-Neo, Baichuan, Qwen, and Mixtral are trained on large amounts of text data, exhibiting strong capacities in naturallanguageprocessing and task resolution through text generation capacity. It also provides multilingual support for languages such as English and Chinese.
already has over a billion users of its LLM-based conversational AI platform, which includes text, audio and video-based agents. The support of NVIDIA Inception is helping us advance our work to automate conversational AI use cases with domain-specific large language models,” said Ankush Sabharwal, CEO of CoRover. “AI-assisted
With this support, you can look forward to faster inference, automatic optimization, and quantization when exporting your LLM models. Additionally, we are also set to release an array of new LLM models fine-tuned specifically for chat and instruction, now that we have successfully integrated ONNX Runtime into Spark NLP.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content