This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post Implementing ETL Process Using Python to Learn Data Engineering appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon Overview: Assume the job of a Data Engineer, extracting data from.
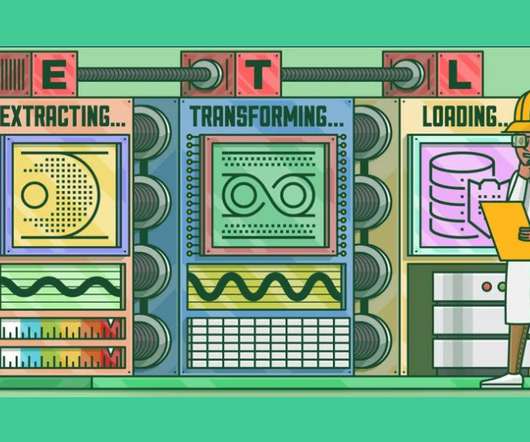
Introduction to ETLETL is a type of three-step data integration: Extraction, Transformation, Load are processing, used to combine data from multiple sources. The post Good ETL Practices with Apache Airflow appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
This crucial process, called Extract, Transform, Load (ETL), involves extracting data from multiple origins, transforming it into a consistent format, and loading it into a target system for analysis.
Overview ETL (Extract, Transform, and Load) is a very common technique in data engineering. Traditionally, ETL processes are […]. The post Crafting Serverless ETL Pipeline Using AWS Glue and PySpark appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction to ETLETL as the name suggests, Extract Transform and. The post Pandas Vs PETL for ETL appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon What is ETL? ETL is a process that extracts data from multiple source systems, changes it (through calculations, concatenations, and so on), and then puts it into the Data Warehouse system. ETL stands for Extract, Transform, and Load.
The post How to Extract Tabular Data from Doc files Using Python? But this data might not be present in a structured form. A beginner starting with the data field is often trained for datasets in standard formats like […]. appeared first on Analytics Vidhya.
In today’s data-driven world, extracting, transforming, and loading (ETL) data is crucial for gaining valuable insights. While many ETL tools exist, dbt (data build tool) is emerging as a game-changer. Introduction Have you ever struggled with managing complex data transformations?
Introduction Apache Airflow is a powerful platform that revolutionizes the management and execution of Extracting, Transforming, and Loading (ETL) data processes. This article explores the intricacies of automating ETL pipelines using Apache Airflow on AWS EC2.
And so, there is no doubt that Data Engineers use it extensively to build and manage their ETL pipelines. Introduction Apache Airflow is the most popular tool for workflow management. But not all the pipelines you build in Airflow will be straightforward. Some are complex and require running one out of the many tasks based […].
Our pipeline belongs to the general ETL (extract, transform, and load) process family that combines data from multiple sources into a large, central repository. The system includes feature engineering, deep learning model architecture design, hyperparameter optimization, and model evaluation, where all modules are run using Python.
In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. Extract, transform and Load Before we begin, let’s shed some light on what an ETL pipeline essentially is. ELT stands for extract, load and transform.
Prerequisites To follow along with this post, set up Amazon SageMaker Studio to run Python in a notebook and interact with Amazon Bedrock. The Python code invokes the Amazon Bedrock Runtime service: import boto3 import json from datetime import datetime import time # Create an Amazon Bedrock Runtime client in the AWS Region of your choice.
This article lists the top data engineering courses that provide comprehensive training in building scalable data solutions, mastering ETL processes, and leveraging advanced technologies like Apache Spark and cloud platforms to meet modern data challenges effectively.
Detailed Examination of Tools Apache Spark: An open-source platform supporting multiple languages (Python, Java, SQL, Scala, and R). AWS Glue: A serverless ETL service that simplifies the monitoring and management of data pipelines. Weaknesses: Long-processing graphs can lead to reliability issues and negatively affect performance.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Introduction The ETL process is crucial in modern data management. What is ETL? ETL stands for Extract, Transform, Load.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
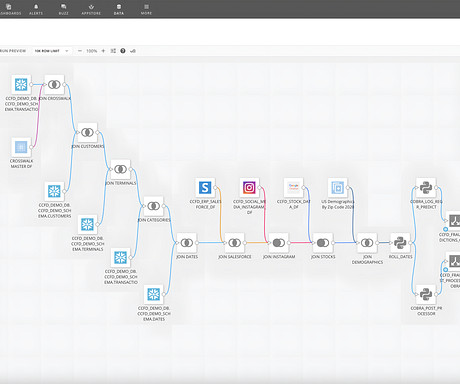
To start, get to know some key terms from the demo: Snowflake: The centralized source of truth for our initial data Magic ETL: Domo’s tool for combining and preparing data tables ERP: A supplemental data source from Salesforce Geographic: A supplemental data source (i.e., Instagram) used in the demo Why Snowflake?
An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark. Creating ETL pipelines to transform log data Preparing your data to provide quality results is the first step in an AI project.
The following sample XML illustrates the prompts template structure: EN FR Prerequisites The project code uses the Python version of the AWS Cloud Development Kit (AWS CDK). To run the project code, make sure that you have fulfilled the AWS CDK prerequisites for Python.
Key Features: Extensive extract, transform, and load (ETL) functions, data integration, and data preparation – all in one platform. Pros: Available as a library in Python, one of the largest user communities, flexible sync frequency. Airbyte has a 300+ library of connectors and the functionality to create custom ones.
Key Features: Extensive extract, transform, and load (ETL) functions, data integration, and data preparation – all in one platform. Pros: Available as a library in Python, one of the largest user communities, flexible sync frequency. Airbyte has a 300+ library of connectors and the functionality to create custom ones.
Summary: Choosing the right ETL tool is crucial for seamless data integration. At the heart of this process lie ETL Tools—Extract, Transform, Load—a trio that extracts data, tweaks it, and loads it into a destination. Choosing the right ETL tool is crucial for smooth data management. What is ETL?
Transform raw insurance data into CSV format acceptable to Neptune Bulk Loader , using an AWS Glue extract, transform, and load (ETL) job. Run an AWS Glue ETL job to merge the raw property and auto insurance data into one dataset and catalog the merged dataset. We use Python scripts to analyze the data in a Jupyter notebook.
The solution harnesses the capabilities of generative AI, specifically Large Language Models (LLMs), to address the challenges posed by diverse sensor data and automatically generate Python functions based on various data formats. It generates a Python function to convert data frames to a common data format.
Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Python, SQL, and Apache Spark are essential for data engineering workflows. PythonPython is one of the most popular programming languages for data engineering. Start your journey with Pickl.AI
To solve this problem, we build an extract, transform, and load (ETL) pipeline that can be run automatically and repeatedly for training and inference dataset creation. The ETL pipeline, MLOps pipeline, and ML inference should be rebuilt in a different AWS account. But there is still an engineering challenge.
Used for 🔀 ETL Systems, ⚙️ Data Microservices, and 🌐 Data Collection Key features: 💡Intuitive API: Easy to learn, easy to think about. 🚀 Functional Paradigm: Python functions are the building blocks of data pipelines. ✨ Pure Python: Lightweight, with zero sub-dependencies.
PowerBI, Tableau) and programming languages like R and Python in the form of bar graphs, scatter line plots, histograms, and much more. What are ETL and data pipelines? The data pipelines follow the Extract, Transform, and Load (ETL) framework. These visualizations can be done using platforms like software tools (e.g.,
This setup uses the AWS SDK for Python (Boto3) to interact with AWS services. Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines.
With SageMaker Unified Studio notebooks, you can use Python or Spark to interactively explore and visualize data, prepare data for analytics and ML, and train ML models. Choose the plus sign and for Notebook , choose Python 3. The Connection Type menu corresponds to connection types such as Local Python, PySpark, SQL, and so on.
The GPU-powered interactive visualizer and Python notebooks provide a seamless way to explore millions of data points in a single window and share insights and results. As part of the initial ETL, this raw data can be loaded onto tables using AWS Glue. Sources and schema There are few sources of mobility data.
Enrich your event analytics, leverage advanced ETL operations and respond to increasing business needs more quickly and efficiently. With its easy-to-use and no-code format, users without deep skills in SQL, Java, or Python can leverage events, enriching their data streams with real-time context, irrespective of their role.
Looking for an effective and handy Python code repository in the form of Importing Data in Python Cheat Sheet? Your journey ends here where you will learn the essential handy tips quickly and efficiently with proper explanations which will make any type of data importing journey into the Python platform super easy.
Introduction Machine learning has become an essential tool for organizations of all sizes to gain insights and make data-driven decisions. However, the success of ML projects is heavily dependent on the quality of data used to train models. Poor data quality can lead to inaccurate predictions and poor model performance.
For budding data scientists and data analysts, there are mountains of information about why you should learn R over Python and the other way around. Without it, whatever you put in Excel, Python, or R, wouldn’t exist because there would be a way to manage the data. But why is SQL, or Structured Query Language , so important to learn?
The next generation of Db2 Warehouse SaaS and Netezza SaaS on AWS fully support open formats such as Parquet and Iceberg table format, enabling the seamless combination and sharing of data in watsonx.data without the need for duplication or additional ETL.
Although no advanced technical knowledge is required, familiarity with Python and AWS Cloud services will be beneficial if you want to explore our sample code on GitHub. It can automate extract, transform, and load (ETL) processes, so multiple long-running ETL jobs run in order and complete successfully without manual orchestration.
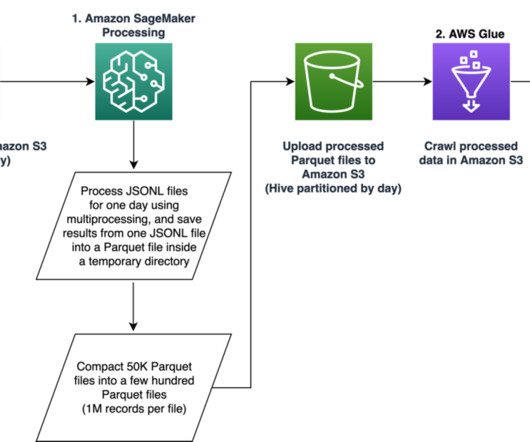
The following figure shows an example diagram that illustrates an orchestrated extract, transform, and load (ETL) architecture solution. For example, searching for the terms “How to orchestrate ETL pipeline” returns results of architecture diagrams built with AWS Glue and AWS Step Functions.
From writing code for doing exploratory analysis, experimentation code for modeling, ETLs for creating training datasets, Airflow (or similar) code to generate DAGs, REST APIs, streaming jobs, monitoring jobs, etc. Implementing these practices can enhance the efficiency and consistency of ETL workflows.
The project I did to land my business intelligence internship — CAR BRAND SEARCH ETL PROCESS WITH PYTHON, POSTGRESQL & POWER BI 1. Section 2: Explanation of the ETL diagram for the project. Section 3: The technical section for the project where Python and pgAdmin4 will be used. Figure 6: Project’s Dashboard 3.
Programming for Data Science with Python This course series teaches essential programming skills for data analysis, including SQL fundamentals for querying databases and Unix shell basics. Students also learn Python programming, from fundamentals to data manipulation with NumPy and Pandas, along with version control using Git.
You can use this notebook job step to easily run notebooks as jobs with just a few lines of code using the Amazon SageMaker Python SDK. These jobs can be run immediately or on a recurring time schedule without the need for data workers to refactor code as Python modules.
You’ll learn Python, Jupyter Notebook, Tableau, and machine-learning techniques through hands-on projects. Meta Data Analyst Professional Certificate This program prepares you for a data analytics career by building essential skills in Python, SQL, and statistics with no prior experience required.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content