This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post is co-authored by Anatoly Khomenko, MachineLearningEngineer, and Abdenour Bezzouh, Chief Technology Officer at Talent.com. Our pipeline belongs to the general ETL (extract, transform, and load) process family that combines data from multiple sources into a large, central repository. session.Session().region_name
Data exploration and model development were conducted using well-known machinelearning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Deployment times stretched for months and required a team of three system engineers and four MLengineers to keep everything running smoothly.
Often the Data Team, comprising Data and MLEngineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier. What is an ETL data pipeline in ML? Let’s look at the importance of ETL pipelines in detail.
This situation is not different in the ML world. Data Scientists and MLEngineers typically write lots and lots of code. Building a mental model for ETL components Learn the art of constructing a mental representation of the components within an ETL process.
Statistical methods and machinelearning (ML) methods are actively developed and adopted to maximize the LTV. In addition to the challenge of defining the features for the ML model, it’s critical to automate the feature generation process so that we can get ML features from the raw data for ML inference and model retraining.
Training and evaluating models is just the first step toward machine-learning success. For this, we have to build an entire machine-learning system around our models that manages their lifecycle, feeds properly prepared data into them, and sends their output to downstream systems. But what is an ML pipeline?
Specialist Data Engineering at Merck, and Prabakaran Mathaiyan, Sr. MLEngineer at Tiger Analytics. The large machinelearning (ML) model development lifecycle requires a scalable model release process similar to that of software development. This post is co-written with Jayadeep Pabbisetty, Sr.
We then discuss the various use cases and explore how you can use AWS services to clean the data, how machinelearning (ML) can aid in this effort, and how you can make ethical use of the data in generating visuals and insights. As part of the initial ETL, this raw data can be loaded onto tables using AWS Glue.
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply MachineLearning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. You have to make sure that your ETLs are locked down. I’m a product manager at Arize.
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply MachineLearning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. You have to make sure that your ETLs are locked down. I’m a product manager at Arize.
Jack Zhou, product manager at Arize , gave a lightning talk presentation entitled “How to Apply MachineLearning Observability to Your ML System” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. You have to make sure that your ETLs are locked down. I’m a product manager at Arize.
This post was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Practice. Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machinelearning (ML) models.
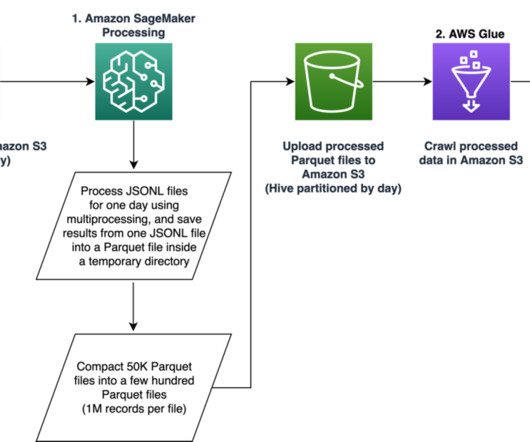
It eliminates tedious, costly, and error-prone ETL (extract, transform, and load) jobs. SageMaker integration SageMaker is a fully managed service to prepare data and build, train, and deploy machinelearning (ML) models for any use case with fully managed infrastructure, tools, and workflows.
Based on the McKinsey survey , 56% of orgs today are using machinelearning in at least one business function. Some of these services aren’t specifically meant for ML models, but we managed to adeptly repurpose them for our model deployment. If you aren’t aware already, let’s introduce the concept of ETL.
In this second installment of the series “Real-world MLOps Examples,” Paweł Pęczek , MachineLearningEngineer at Brainly , will walk you through the end-to-end MachineLearning Operations (MLOps) process in the Visual Search team at Brainly. Their user base spans more than 35 countries.
11 key differences in 2023 Photo by Jan Tinneberg on Unsplash Working in Data Science and MachineLearning (ML) professions can be a lot different from the expectation of it. You will need to learn to query different databases depending on which ones your company uses.
And that’s what we’re going to focus on in this article, which is the second in my series on Software Patterns for Data Science & MLEngineering. Some of the most widely adopted tools in this space are Deepnote , Amazon SageMaker , Google Vertex AI , and Azure MachineLearning.
This is Piotr Niedźwiedź and Aurimas Griciūnas from neptune.ai , and you’re listening to ML Platform Podcast. Stefan is a software engineer, data scientist, and has been doing work as an MLengineer. We want to stop the pain and suffering people feel with maintaining machinelearning pipelines in production.
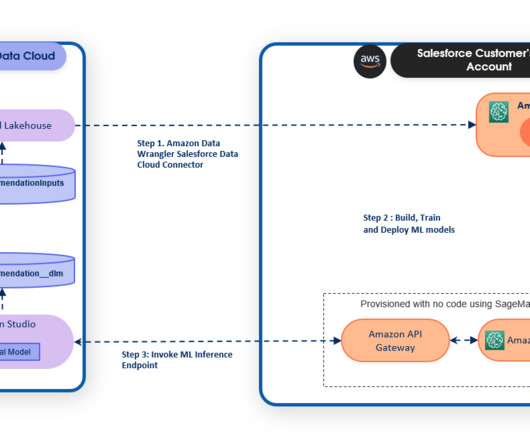
ML operationalization summary As defined in the post MLOps foundation roadmap for enterprises with Amazon SageMaker , ML and operations (MLOps) is the combination of people, processes, and technology to productionize machinelearning (ML) solutions efficiently. The following figure illustrates their journey.
View the execution status and details of the workflow by fetching the state machine Amazon Resource Name (ARN) from the CloudFormation stack. He helps architect solutions across AI/ML applications, enterprise data platforms, data governance, and unified search in enterprises.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content