
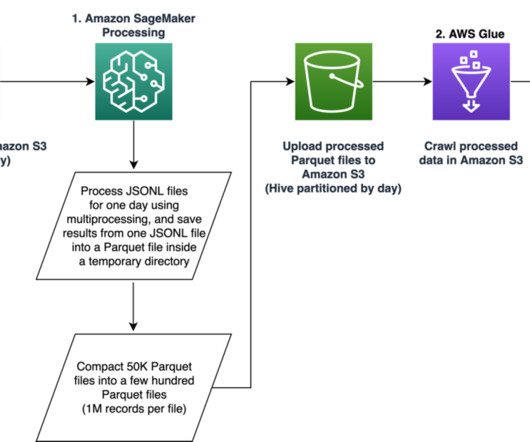
Streamlining ETL data processing at Talent.com with Amazon SageMaker
AWS Machine Learning Blog
DECEMBER 14, 2023
Our pipeline belongs to the general ETL (extract, transform, and load) process family that combines data from multiple sources into a large, central repository. The solution does not require porting the feature extraction code to use PySpark, as required when using AWS Glue as the ETL solution. session.Session().region_name






















Let's personalize your content