This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Automated document fraud detection powered by AI offers a proactive solution, letting businesses to verify documents in real-time, detect anomalies, and prevent fraud before it occurs. Here is where AI-powered intelligent document processing (IDP) is changing the game. This is where intelligent document processing comes in.
Introduction Keyword extraction is commonly used to extract key information from a series of paragraphs or documents. The post Keyword Extraction Methods from Documents in NLP appeared first on Analytics Vidhya. Keyword extraction is an automated method of extracting the most relevant words and phrases from text input.
The post Identifying The Language of A Document Using NLP! ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction The goal of this article is to identify the language. appeared first on Analytics Vidhya.
This article focuses on answer retrieval from a document by. The post NLP: Answer Retrieval from Document using Python appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction ?
Introduction In the field of Natural Language Processing i.e., NLP, Lemmatization and Stemming are Text Normalization techniques. These techniques are used to prepare words, text, and documents for further processing. The post Stemming vs Lemmatization in NLP: Must-Know Differences appeared first on Analytics Vidhya.
This is where the term frequency-inverse document frequency (TF-IDF) technique in Natural Language Processing (NLP) comes into play. Introduction Understanding the significance of a word in a text is crucial for analyzing and interpreting large volumes of data. appeared first on Analytics Vidhya.
Introduction Document information extraction involves using computer algorithms to extract structured data (like employee name, address, designation, phone number, etc.) from unstructured or semi-structured documents, such as reports, emails, and web pages.
Introduction In the world of information retrieval, where oceans of text data await exploration, the ability to pinpoint relevant documents efficiently is invaluable. Traditional keyword-based search has its limitations, especially when dealing with personal and confidential data.
Introduction NLP (Natural Language Processing) can help us to understand huge amounts of text data. Instead of going through a huge amount of documents by hand and reading them manually, we can make use of these techniques to speed up our understanding and get to the main messages quickly.
Introduction Pre-requisite: Basic understanding of Python, machine learning, scikit learn python, Classification Objectives: In this tutorial, we will build a method for embedding text documents, called Bag of concepts, and then we will use the resulting representations (embedding) to classify these documents. First, […].
Enter Retrieval Augmented Generation (RAG), a fusion of retrieval and generation models in NLP. Join us as we uncover the secrets of RAG, explore its applications, and its […] The post RAG’s Innovative Approach to Unifying Retrieval and Generation in NLP appeared first on Analytics Vidhya.
Use it for a variety of tasks, like translating text, answering […] The post Unlocking LangChain & Flan-T5 XXL | A Guide to Efficient Document Querying appeared first on Analytics Vidhya. For example, OpenAI’s GPT-3 model has 175 billion parameters.
Natural Language Processing (NLP) and Artificial Intelligence (AI) emerge as a powerful tools to revolutionize capital infrastructure planning, foster inclusivity, and drive an equitable future by engaging communities in decision-making. Beyond public engagement, NLP offers numerous benefits for stakeholders in infrastructure planning.
In Natural Language Processing (NLP), Text Summarization models automatically shorten documents, papers, podcasts, videos, and more into their most important soundbites. What is Text Summarization for NLP? The models are powered by advanced Deep Learning and Machine Learning research.
These platforms handle essential tasks like clinical documentation, medical imaging analysis, patient communications, and administrative workflows, letting providers focus on patient care. For clinical documentation, practitioners can access specialized tools and templates to streamline their note-taking and patient intake processes.
Knowledge Base Integration: Connects to structured knowledge sources (websites, documents, etc.) Natural Language Processing (NLP): Built-in NLP capabilities for understanding user intents and extracting key information. This allows the chatbot to pull information from a predefined set of documents or data sources.
Introduction to Ludwig The development of Natural Language Machines (NLP) and Artificial Intelligence (AI) has significantly impacted the field. These models can understand and generate human-like text, enabling applications like chatbots and document summarization.
AI in healthcare is causing a revolution in how clinicians document, analyze, and make decisions. AI Scribes: Redefining Clinical Documentation AI has a big influence on clinical documentation, which is one of the main areas it's changing. They also help make documentation more accurate and complete.
The framework's cross-platform support and extensive documentation make it an excellent choice for developers building sophisticated real-time AI applications. Natural Natural has established itself as a comprehensive NLP library for JavaScript, providing essential tools for text-based AI applications.
Unlocking efficient legal document classification with NLP fine-tuning Image Created by Author Introduction In today’s fast-paced legal industry, professionals are inundated with an ever-growing volume of complex documents — from intricate contract provisions and merger agreements to regulatory compliance records and court filings.
Overview In NLP, tf-idf is an important measure and is used by algorithms like cosine similarity to find documents that are similar to a given search query. This article was published as a part of the Data Science Blogathon. Here in this blog, we will try to break tf-idf and see how sklearn’s TfidfVectorizer calculates […].
print(preprocess_legal_text(sample_text)) Then, we preprocess legal text using spaCy and regular expressions to ensure cleaner and more structured input for NLP tasks. print(preprocess_legal_text(sample_text)) Then, we preprocess legal text using spaCy and regular expressions to ensure cleaner and more structured input for NLP tasks.
Overview This article will give you a brief idea about Named Entity recognition, a popular method that is used for recognizing entities that are present in a text document. This article is targeted at beginners in the field of NLP. By the end […].
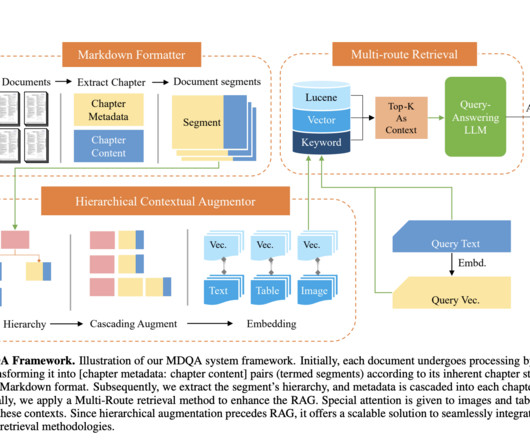
Be sure to check out their talk, Structuring the Unstructured: Advanced Document Parsing for AI Workflows, there! We all have been there, tackling the challenge of extracting unstructured data from documents while maintaining context awareness and fidelity. An enterprise document is not just text or simple tables.
This article was published as a part of the Data Science Blogathon Overview Sentence classification is one of the simplest NLP tasks that have a wide range of applications including document classification, spam filtering, and sentiment analysis. A sentence is classified into a class in sentence classification.
Imagine an AI that can write poetry, draft legal documents, or summarize complex research papersbut how do we truly measure its effectiveness? As Large Language Models (LLMs) blur the lines between human and machine-generated content, the quest for reliable evaluation metrics has become more critical than ever.
Dwell in the Beginning: How Language Models Embed Long Documents for Dense Retrieval João Coelho, Bruno Martins, João Magalhães, Jamie Callan, Chenyan Xiong. link] The paper investigates positional biases when encoding long documents into a vector for similarity-based retrieval. ArXiv 2024. CSIRO Data61, University of Copenhagen.
Introduction Often there are many situations where we don’t have/get enough time to read and understand lengthy documents, research papers, or news articles. This is where NLP text summarization comes into play, which […] The post Exploring the Extractive Method of Text Summarization appeared first on Analytics Vidhya.
Natural Language Processing (NLP) Once speech becomes text, natural language processing, or NLP, models analyze the actual meaning. NLP identifies sentence structure and maps relationships between statements. Healthcare operations Voice intelligence streamlines documentation while improving patient care.
NLP Logix, a leading artificial intelligence (AI) and machine learning (ML) consultancy has announced a strategic technology partnership with John Snow Labs, a premier provider of healthcare AI solutions. Building custom de-identification pipelines can often be time-intensive and resource-heavy. The sentiment is echoed by John Snow Labs.
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. This solution uses the powerful capabilities of Amazon Q Business.
In today’s data-driven business landscape, the ability to efficiently extract and process information from a wide range of documents is crucial for informed decision-making and maintaining a competitive edge. The Anthropic Claude 3 Haiku model then processes the documents and returns the desired information, streamlining the entire workflow.
However, with Healthcare NLP s task-based pretrained pipelines, these challenges can be overcome with simple one-liner solutions that tackle everything from entity recognition to de-identification. Similarly, Healthcare NLP pipelines follow this principle, enabling seamless text processing for clinical applications. What Is a Pipeline?
A researcher within Google leaked a document on a public Discord server recently. There is much controversy surrounding the document’s authenticity. Discord is an open-source community platform. Many other groups also use it, but Discord is primarily designed for communities of gamers to facilitate voice, video, and text chat.
Natural Language Processing (NLP) is a rapidly growing field that deals with the interaction between computers and human language. As NLP continues to advance, there is a growing need for skilled professionals to develop innovative solutions for various applications, such as chatbots, sentiment analysis, and machine translation.
This extensive training allows the embeddings to capture semantic meanings effectively, enabling advanced NLP tasks. Utility Functions: The library provides useful functions for similarity lookups and analogies, aiding in various NLP tasks. Custom Training: Users can train these embeddings on new data, tailoring them to specific needs.
A significant challenge with question-answering (QA) systems in Natural Language Processing (NLP) is their performance in scenarios involving extensive collections of documents that are structurally similar or ‘indistinguishable.’ Knowledge graphs and LLMs are used to model these relationships.
Large language models ( LLMs ) like GPT-4, PaLM, Bard, and Copilot have made a huge impact in natural language processing (NLP). Their design makes them accessible and cost-effective, offering organizations an opportunity to harness NLP without the heavy demands of LLMs. However, they also come with significant challenges.
The company aims to acquire agencies with under $5 million in revenue a segment often overlooked by traditional private equity and infuse them with machine learning tools that handle repetitive tasks like document processing, client onboarding, and claims management.
By Vatsal Saglani This article explores the creation of PDF2Pod, a NotebookLM clone that transforms PDF documents into engaging, multi-speaker podcasts. It also demonstrates how to store and retrieve embedded documents using vector stores and visualize embeddings for better understanding.
From research papers in PDF to reports in DOCX and plain text documents (TXT), to structured data in CSV files, there’s […] The post How to Develop A Multi-File Chatbot? appeared first on Analytics Vidhya.
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent data extraction. Named Entity Recognition ( NER) Named entity recognition (NER), an NLP technique, identifies and categorizes key information in text.
John Snow Labs is the developer behind Spark NLP, Healthcare NLP, and Medical LLMs. John Snow Labs’ Medical Language Models is by far the most widely used natural language processing (NLP) library by practitioners in the healthcare space (Gradient Flow, The NLP Industry Survey 2022 and the Generative AI in Healthcare Survey 2024 ).
Knowledge base and database connectors: Give the bot context from your documents or data tables. This means your AI agents can automatically update records, send emails, pull documents, or trigger workflows in your existing software stack. Visit BotPress 2. plus the ability to record UI actions for legacy systems.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content