

RAG and Streamlit Chatbot: Chat with Documents Using LLM
Analytics Vidhya
APRIL 30, 2024
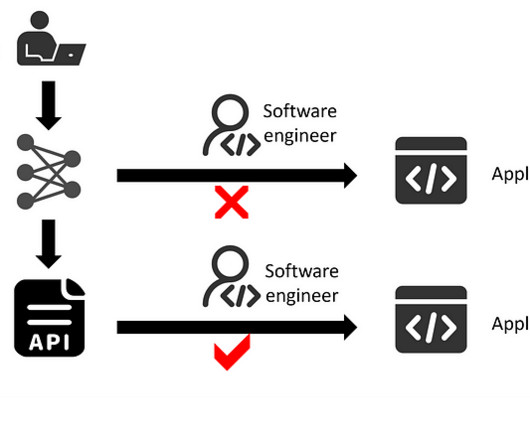
Introduction This article aims to create an AI-powered RAG and Streamlit chatbot that can answer users questions based on custom documents. Users can upload documents, and the chatbot can answer questions by referring to those documents.








































Let's personalize your content