This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. This solution uses the powerful capabilities of Amazon Q Business.
Be sure to check out their talk, Structuring the Unstructured: Advanced Document Parsing for AI Workflows, there! We all have been there, tackling the challenge of extracting unstructured data from documents while maintaining context awareness and fidelity. An enterprise document is not just text or simple tables.
A significant challenge with question-answering (QA) systems in Natural Language Processing (NLP) is their performance in scenarios involving extensive collections of documents that are structurally similar or ‘indistinguishable.’ Knowledge graphs and LLMs are used to model these relationships.
Dwell in the Beginning: How Language Models Embed Long Documents for Dense Retrieval João Coelho, Bruno Martins, João Magalhães, Jamie Callan, Chenyan Xiong. link] The paper investigates positional biases when encoding long documents into a vector for similarity-based retrieval. ArXiv 2024. CSIRO Data61, University of Copenhagen.
This capability enhances responses from generative AI applications by automatically creating embeddings for semantic search and generating a graph of the entities and relationships extracted from ingested documents. This new capability integrates the power of graph data modeling with advanced natural language processing (NLP).
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
of Finance NLP releases new demo apps for Question Answering and Summarization tasks and fixes documentation for many models. Fixed NER models detecting eXtensible Business Reporting Language (XBRL) entities We fixed model names and metadata related to XBRL that detects the 139 most common labels of the framework. Fancy trying?
The traditional approach of manually sifting through countless research documents, industry reports, and financial statements is not only time-consuming but can also lead to missed opportunities and incomplete analysis. This event-driven architecture provides immediate processing of new documents.
They help in importing data from varied sources and formats, encapsulating them into a simplistic ‘Document' representation. LlamaIndex hub ([link] Documents / Nodes : A Document is like a generic suitcase that can hold diverse data types—be it a PDF, API output, or database entries.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
We are delighted to announce a suite of remarkable enhancements and updates in our latest release of Healthcare NLP. Allergies: Patient has a documented allergy to Penicillin. """ withColumn("parameters", df.rxhcc_profile.getItem("parameters")).withColumn("details",
Intelligent insights and recommendations Using its large knowledge base and advanced natural language processing (NLP) capabilities, the LLM provides intelligent insights and recommendations based on the analyzed patient-physician interaction. These insights can include: Potential adverse event detection and reporting.
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Traditional document processing methods often fall short in efficiency and accuracy, leaving room for innovation, cost-efficiency, and optimizations. However, the potential doesn’t end there.
Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. But in the case of unstructured data, metadata discovery is challenging because the raw data isn’t easily readable. Text, images, audio, and videos are common examples of unstructured data.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. It automates capturing model metadata and increases predictive accuracy to identify how AI tools are used and where model training needs to be done again. Track models and drive transparent processes.
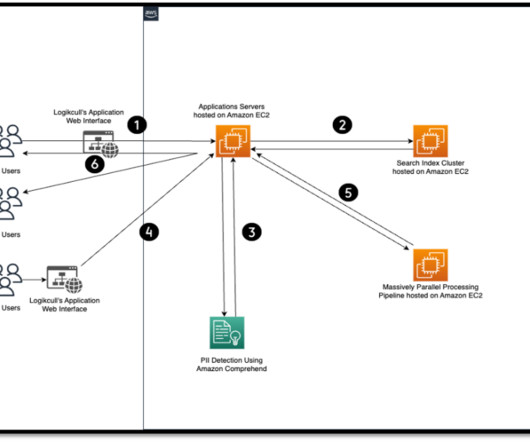
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
In Natural Language Processing (NLP) tasks, data cleaning is an essential step before tokenization, particularly when working with text data that contains unusual word separations such as underscores, slashes, or other symbols in place of spaces. The post Is There a Library for Cleaning Data before Tokenization?
In a prompt lab, users can experiment with models by entering prompts for a wide range of tasks such as summarizing transcripts or performing sentiment analysis on a document. 1] Users can access data through a single point of entry, with a shared metadata layer across clouds and on-premises environments. Watsonx.ai
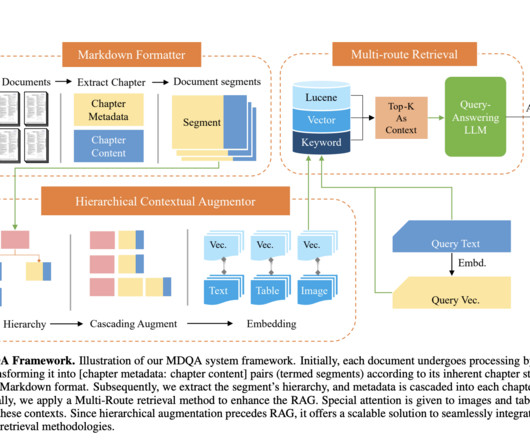
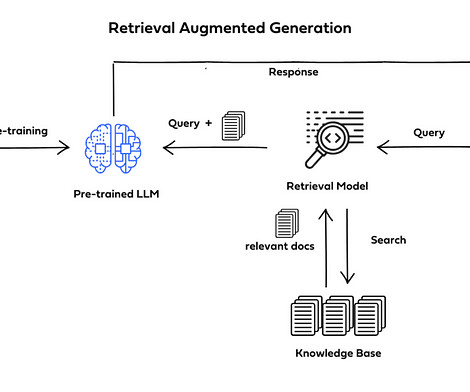
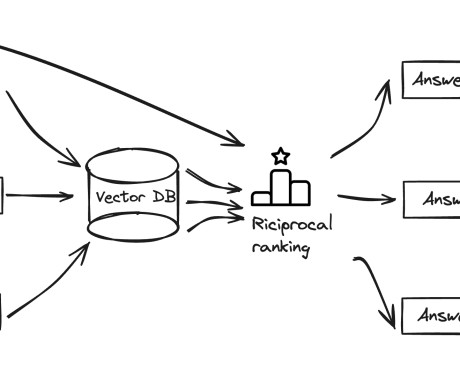
Retrieval Augmented Generation (RAG) represents a cutting-edge advancement in Artificial Intelligence, particularly in NLP and Information Retrieval (IR). The choice of document chunking strategy is critical, affecting the information retained and the context maintained during retrieval.
This NLP clinical solution collects data for administrative coding tasks, quality improvement, patient registry functions, and clinical research. Second, the information is frequently derived from natural language documents or a combination of structured, imaging, and document sources.
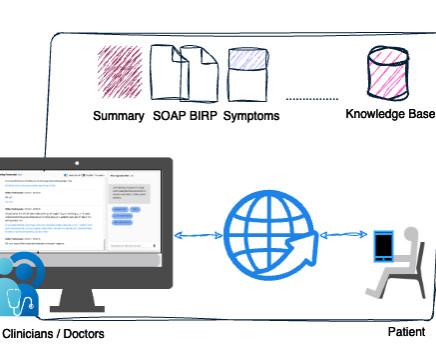
Today, physicians spend about 49% of their workday documenting clinical visits, which impacts physician productivity and patient care. By using the solution, clinicians don’t need to spend additional hours documenting patient encounters. This blog post focuses on the Amazon Transcribe LMA solution for the healthcare domain.
Scientific metadata in research literature holds immense significance, as highlighted by flourishing research in scientometricsa discipline dedicated to analyzing scholarly literature. Metadata improves the findability and accessibility of scientific documents by indexing and linking papers in a massive graph.
Using natural language processing (NLP) and OpenAPI specs, Amazon Bedrock Agents dynamically manages API sequences, minimizing dependency management complexities. The policy agent accesses the Policy Information API to extract answers to insurance-related questions from unstructured policy documents such as PDF files.
Previously, you had a choice between human-based model evaluation and automatic evaluation with exact string matching and other traditional natural language processing (NLP) metrics. Rubrics are published in full with the judge prompts in the documentation so non-scientists can understand how scores are derived.
Let’s start with a brief introduction to Spark NLP and then discuss the details of pretrained pipelines with some concrete results. Spark NLP & LLM The Healthcare Library is a powerful component of John Snow Labs’ Spark NLP platform, designed to facilitate NLP tasks within the healthcare domain.
Sphinx is relatively lightweight compared to other speech-to-text solutions, supports multiple languages, and offers extensive developer documentation and FAQs. The library can be installed using pip, and audio files can be processed with minimal setup, as shown in the provided documentation or code snippets.
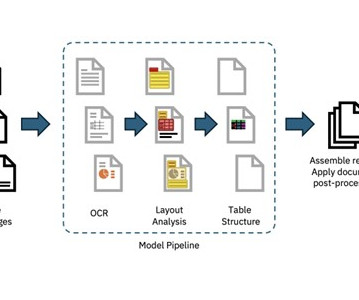
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. AnalyzeDocument Layout is a new feature that allows customers to automatically extract layout elements such as paragraphs, titles, subtitles, headers, footers, and more from documents.
Inspect Rich Documents with Gemini Multimodality and Multimodal RAG This course covers using multimodal prompts to extract information from text and visual data and generate video descriptions with Gemini. Natural Language Processing on Google Cloud This course introduces Google Cloud products and solutions for solving NLP problems.
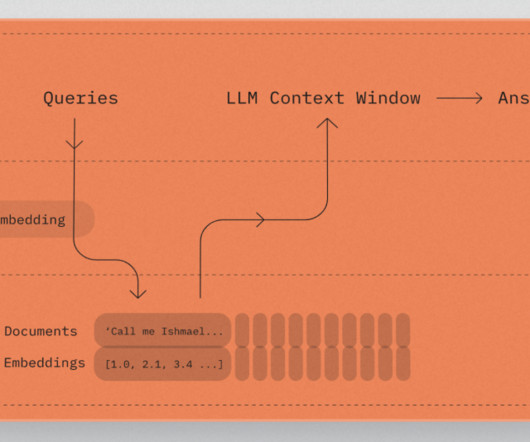
During inference, RAG dynamically gets data from a connected database or document store, in contrast to standard generative models that only use pre-trained data. Step 2 : Document/Text Processing Internal Steps: Import PDF document. _pages_and_chunks( pages_and_texts ) # Create chunks with metadata.
It allows for very fast similarity search, essential for many AI uses such as recommendation systems, picture recognition, and NLP. Each referenced string can have extra metadata that describes the original document. Researchers fabricated some metadata to use in the tutorial. You can skip this step if you like.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. This generative AI task is called text-to-SQL, which generates SQL queries from natural language processing (NLP) and converts text into semantically correct SQL. Today, generative AI can enable people without SQL knowledge.
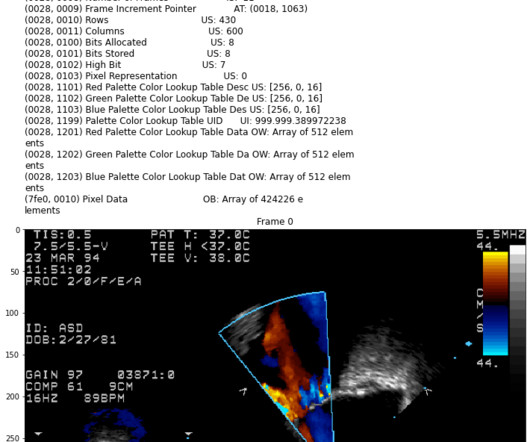
Start to work with DICOM in Visual NLP In this post, we are taking a deep dive into working with metadata using Visual NLP. We are going to make use of Visual NLP pipelines. Visual NLP pipelines are Spark ML pipelines. DicomMetadataDeidentifier this transformer will de-indentify the metadata. Each stage(a.k.a
These encoder-only architecture models are fast and effective for many enterprise NLP tasks, such as classifying customer feedback and extracting information from large documents. With multiple families in plan, the first release is the Slate family of models, which represent an encoder-only architecture.
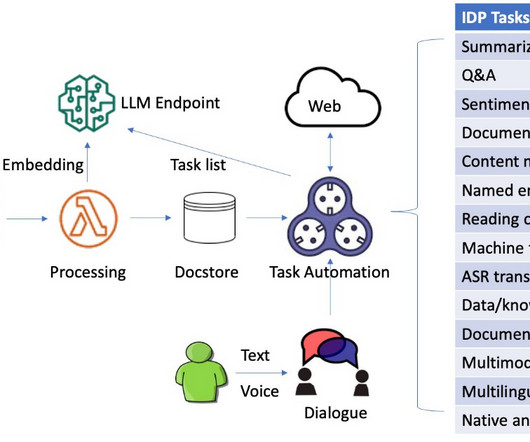
Intelligent document processing (IDP) is a technology that automates the processing of high volumes of unstructured data, including text, images, and videos. Natural language processing (NLP) is one of the recent developments in IDP that has improved accuracy and user experience. You can also choose g5.48xlarge or p4de.24xlarge
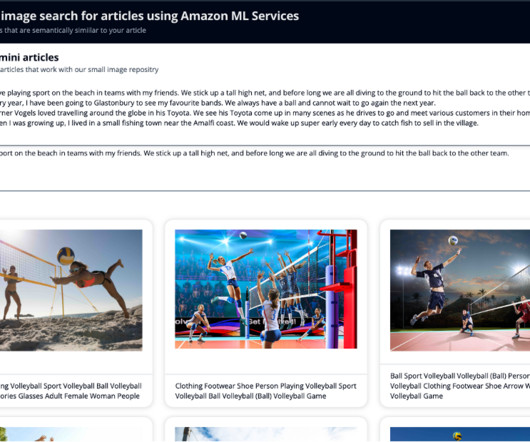
OpenSearch Service allows you to store vectors and other data types in an index, and offers rich functionality that allows you to search for documents using vectors and measuring the semantical relatedness, which we use in this post. First, you extract label and celebrity metadata from the images, using Amazon Rekognition.
Experts can check hard drives, metadata, data packets, network access logs or email exchanges to find, collect, and process information. Reporting Analysts must document every action they take to ensure their evidence holds up in a criminal or civil court later on. AI’s unmatched speed and versatility make it one of the best solutions.
Sentence detection in Spark NLP is the process of identifying and segmenting a piece of text into individual sentences using the Spark NLP library. Sentence Detection in Spark NLP is the process of automatically identifying the boundaries of sentences in a given text.
Solution architecture The mmRAG solution is based on a straightforward concept: to extract different data types separately, you generate text summarization using a VLM from different data types, embed text summaries along with raw data accordingly to a vector database, and store raw unstructured data in a document store. split('.')[0]}.json"
In this article, we will discuss the use of Clinical NLP in understanding the rich meaning that lies behind the doctor’s written analysis (clinical documents/notes) of patients. Contextualization – It is very important for a clinical NLP system to understand the context of what a doctor is writing about.
It goes beyond simple keyword matching by understanding the context of your query and ranking documents based on their relevance to your information needs. In this blog, we delve into the intricacies of Information Retrieval in NLP. This structure allows for efficient lookup and retrieval of documents based on specific terms.
The Normalizer annotator in Spark NLP performs text normalization on data. The Normalizer annotator in Spark NLP is often used as part of a preprocessing step in NLP pipelines to improve the accuracy and quality of downstream analyses and models. These transformations can be configured by the user to meet their specific needs.
Rule-based sentiment analysis in Natural Language Processing (NLP) is a method of sentiment analysis that uses a set of manually-defined rules to identify and extract subjective information from text data. Using Spark NLP, it is possible to analyze the sentiment in a text with high accuracy.
Stopwords removal in natural language processing (NLP) is the process of eliminating words that occur frequently in a language but carry little or no meaning. Stopwords cleaning in Spark NLP is the process of removing stopwords from the text data. Stopwords are commonly occurring words (like the, a, and, in , etc.)
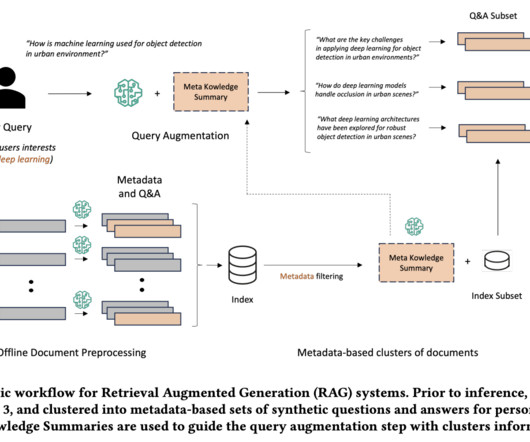
The recent NLP Summit served as a vibrant platform for experts to delve into the many opportunities and also challenges presented by large language models (LLMs). At the recent NLP Summit, experts from academia and industry shared their insights. solves this problem by extracting metadata during the data preparation process.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content