
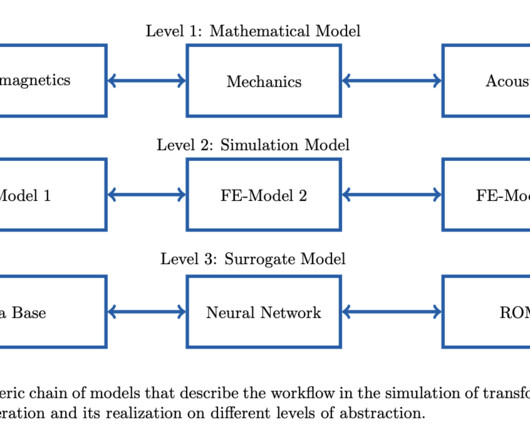
MaRDIFlow: Automating Metadata Abstraction for Enhanced Reproducibility in Computational Workflows
Marktechpost
MAY 8, 2024
While CSE workflows are documented, inclusive abstract descriptions still need to be included. Emerging tools like Jupyter notebooks and Code Ocean facilitate documentation and integration, while automated workflows aim to merge computer-based and laboratory computations.

































Let's personalize your content