

Streamline RAG applications with intelligent metadata filtering using Amazon Bedrock
NOVEMBER 20, 2024
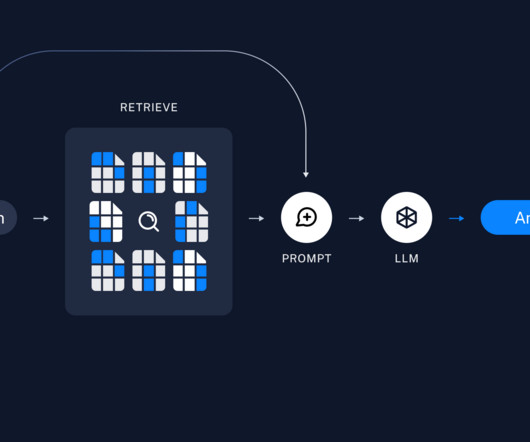
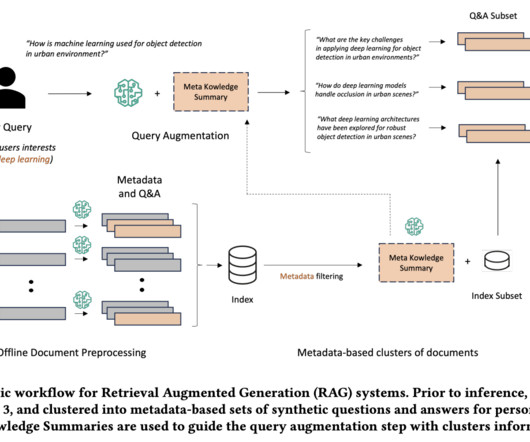
One effective way to improve context relevance is through metadata filtering, which allows you to refine search results by pre-filtering the vector store based on custom metadata attributes. By combining the capabilities of LLM function calling and Pydantic data models, you can dynamically extract metadata from user queries.





































Let's personalize your content