This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
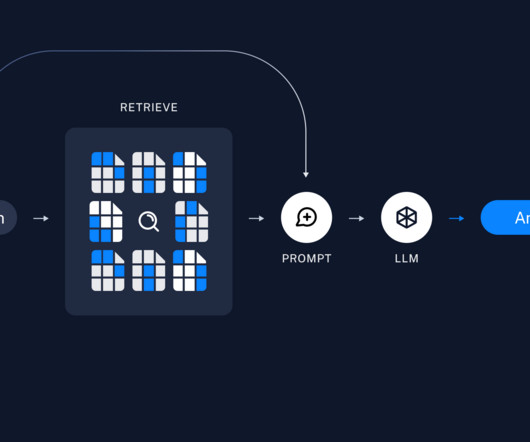
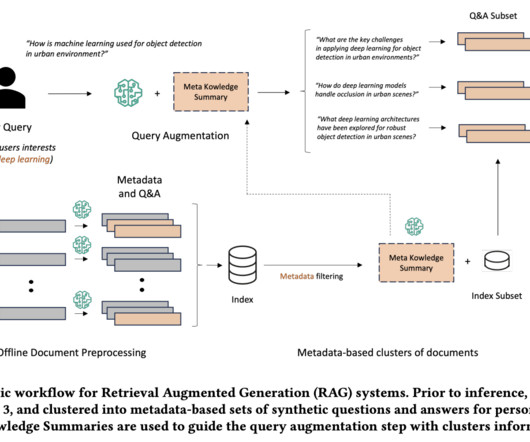
One effective way to improve context relevance is through metadata filtering, which allows you to refine search results by pre-filtering the vector store based on custom metadata attributes. By combining the capabilities of LLM function calling and Pydantic data models, you can dynamically extract metadata from user queries.
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
However, in many situations, you may need to retrieve documents created in a defined period or tagged with certain categories. To refine the search results, you can filter based on documentmetadata to improve retrieval accuracy, which in turn leads to more relevant FM generations aligned with your interests.
By incorporating their unique data sources, such as internal documentation, product catalogs, or transcribed media, organizations can enhance the relevance, accuracy, and contextual awareness of the language model’s outputs. Access control with metadata filters Metadata filtering in knowledge bases enables access control for your data.
However, information about one dataset can be in another dataset, called metadata. Without using metadata, your retrieval process can cause the retrieval of unrelated results, thereby decreasing FM accuracy and increasing cost in the FM prompt token. This change allows you to use metadata fields during the retrieval process.
Introduction With the advent of RAG (Retrieval Augmented Generation) and Large Language Models (LLMs), knowledge-intensive tasks like Document Question Answering, have become a lot more efficient and robust without the immediate need to fine-tune a cost-expensive LLM to solve downstream tasks.
While CSE workflows are documented, inclusive abstract descriptions still need to be included. Emerging tools like Jupyter notebooks and Code Ocean facilitate documentation and integration, while automated workflows aim to merge computer-based and laboratory computations.
A significant challenge with question-answering (QA) systems in Natural Language Processing (NLP) is their performance in scenarios involving extensive collections of documents that are structurally similar or ‘indistinguishable.’ Multi-document QA is more challenging and requires considering relationships between documents.
While using their data source, they want better visibility into the document processing lifecycle during data source sync jobs. They want to know the status of each document they attempted to crawl and index, as well as the ability to troubleshoot why certain documents were not returned with the expected answers.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. In this collaboration, the AWS GenAIIC team created a RAG-based solution for Deltek to enable Q&A on single and multiple government solicitation documents.
A large portion of that information is found in text narratives stored in various document formats such as PDFs, Word files, and HTML pages. Some information is also stored in tables (such as price or product specification tables) embedded in those same document types, CSVs, or spreadsheets.
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.
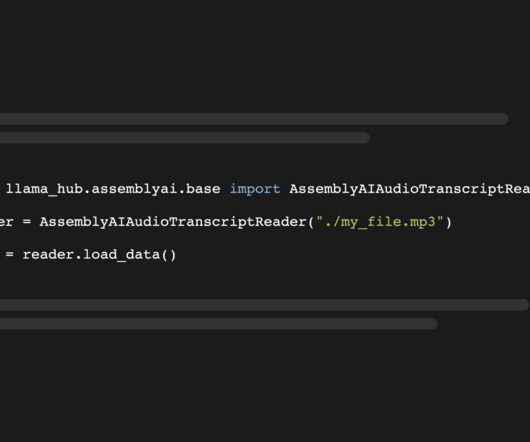
. # Mac/Linux: export ASSEMBLYAI_API_KEY=<YOUR_KEY> # Windows: set ASSEMBLYAI_API_KEY=<YOUR_KEY> Use the AssemblyAIAudioTranscriptReader To load and transcribe audio data into documents, import the AssemblyAIAudioTranscriptReader. You can read more about the integration in the official Llama Hub docs. print(docs[0].text)
Furthermore, the document outlines plans for implementing a “consent popup” mechanism to inform users about potential defects or errors produced by AI. It also mandates the labelling of deepfakes with permanent unique metadata or other identifiers to prevent misuse.
They help in importing data from varied sources and formats, encapsulating them into a simplistic ‘Document' representation. LlamaIndex hub ([link] Documents / Nodes : A Document is like a generic suitcase that can hold diverse data types—be it a PDF, API output, or database entries.
Today, the company announced a $16 million Series A funding round to scale its groundbreaking solution and unveiled Ivo Search Agent, a tool that eliminates manual metadata tagging for contract search and analysis.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
After ChatGPT went viral, one of the first services and applications created was “Use ChatGPT for your documents.” About Part 3 and the Course· Document Loaders· Document Splitting· Basics of RAG pipelines· Time to code About Part 3 and the Course This is Part 3 of the LangChain 101 course. Let it be a PDF file of 100 pages.
This approach has two primary shortcomings: Missed Contextual Signals : Without considering metadata such as source URLs, LMs overlook important contextual information that could guide their understanding of a texts intent or quality. MeCo leverages readily available metadata, such as source URLs, during the pre-training phase.
When using your data source, you might want better visibility into the document processing lifecycle during data source sync jobs. They could include knowing the status of each document you attempted to crawl and index, as well as being able to troubleshoot why certain documents were not returned with the expected answers.
AWS customers in healthcare, financial services, the public sector, and other industries store billions of documents as images or PDFs in Amazon Simple Storage Service (Amazon S3). In this post, we focus on processing a large collection of documents into raw text files and storing them in Amazon S3.
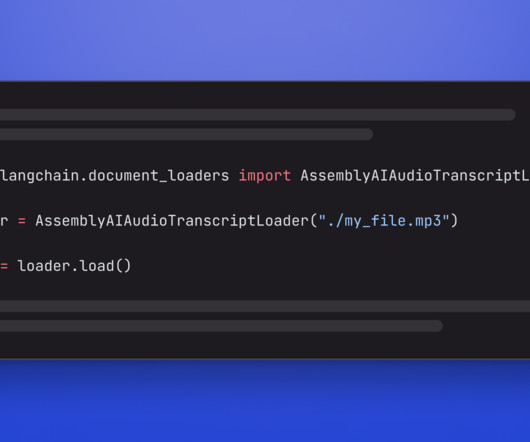
. # Mac/Linux: export ASSEMBLYAI_API_KEY=<YOUR_KEY> # Windows: set ASSEMBLYAI_API_KEY=<YOUR_KEY> Use the AssemblyAIAudioTranscriptLoader To load and transcribe audio data into documents, import the AssemblyAIAudioTranscriptLoader. You can read more about the integration in the official LangChain docs.
In previous posts, we covered new capabilities like hybrid search support , metadata filtering to improve retrieval accuracy , and how Knowledge Bases for Amazon Bedrock manages the end-to-end RAG workflow. Today, we’re introducing the new capability to chat with your document with zero setup in Knowledge Bases for Amazon Bedrock.
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Traditional document processing methods often fall short in efficiency and accuracy, leaving room for innovation, cost-efficiency, and optimizations. However, the potential doesn’t end there.
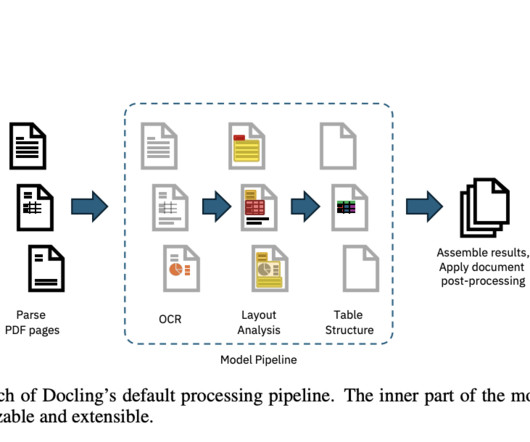
Document conversion, particularly from PDF to machine-processable formats, has long presented significant challenges due to PDF files’ diverse and often complex nature. These documents, widely used across various industries, frequently need more standardization, resulting in a loss of structural features when optimized for printing.
In this approach, the LLM query retrieves relevant documents from a database and passes these into the LLM as additional context. RAG therefore helps improve the relevancy of responses by including pertinent information in the context, and also improves transparency by letting the LLM reference and cite source documents. filepath/URL).
In the previous part, we embarked on a remarkable journey into document processing. We witnessed the development of a robust document embedding mechanism and the creation of a vector store, setting the stage for streamlined and optimized querying. It combines Azure Cognitive Search for document retrieval and OpenAI’s GPT-3.5
Let’s look at several strategies: Take advantage of data catalogs : Data catalogs are centralized repositories that provide a list of available data assets and their associated metadata. This can help data scientists understand the origin, format and structure of the data used to train ML models.
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. This solution uses the powerful capabilities of Amazon Q Business.
DIANNA goes beyond traditional AI tools, offering organizations an unprecedented level of expertise and insight into unknown scripts, documents, and raw binaries to prepare for zero-day attacks. At a high level, we can detect malware that the deep learning framework tags within an attack and then feed it as metadata into the LLM model.
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
Customers want to search through all of the data and applications across their organization, and they want to see the provenance information for all of the documents retrieved. The application needs to search through the catalog and show the metadata information related to all of the data assets that are relevant to the search context.
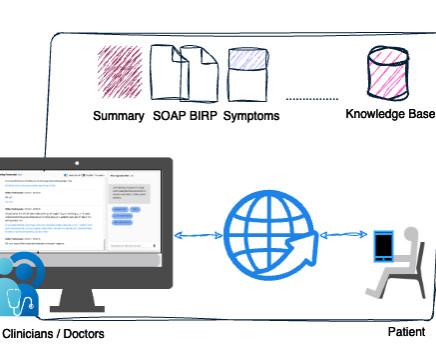
Today, physicians spend about 49% of their workday documenting clinical visits, which impacts physician productivity and patient care. By using the solution, clinicians don’t need to spend additional hours documenting patient encounters. This blog post focuses on the Amazon Transcribe LMA solution for the healthcare domain.
Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. But in the case of unstructured data, metadata discovery is challenging because the raw data isn’t easily readable. Text, images, audio, and videos are common examples of unstructured data.
Download the Gartner® Market Guide for Active Metadata Management 1. With data lineage, every object in the migrated system is mapped and dependencies are documented. We’ve compiled six key reasons why financial organizations are turning to lineage platforms like MANTA to get control of their data.
These datasets often contain a substantial amount of noise, which can either be intrinsic to the task at hand or a result of the lack of standardization across various documents, which may come in different formats like PDFs, PowerPoint presentations, or Word documents.
However, it’s important to note that in RAG-based applications, when dealing with large or complex input text documents, such as PDFs or.txt files, querying the indexes might yield subpar results. Advanced parsing Advanced parsing is the process of analyzing and extracting meaningful information from unstructured or semi-structured documents.
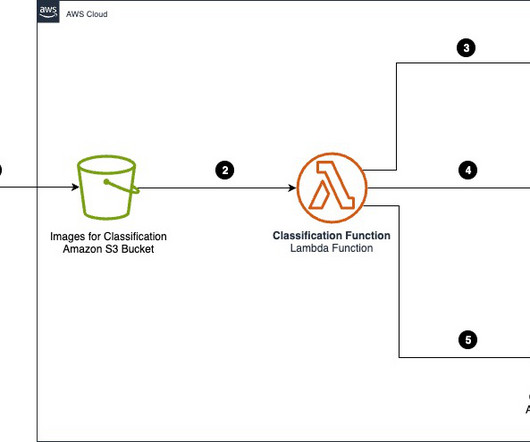
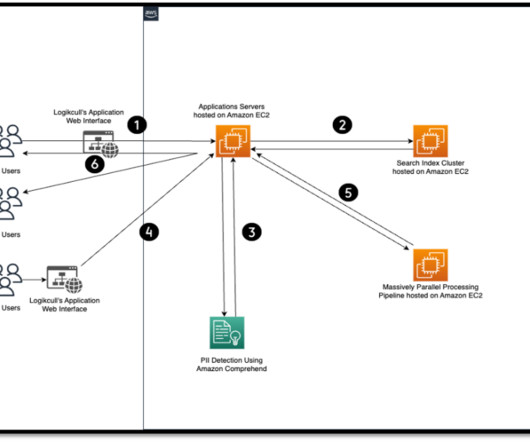
A common adoption pattern is to introduce document search tools to internal teams, especially advanced document searches based on semantic search. In a real-world scenario, organizations want to make sure their users access only documents they are entitled to access. The following diagram depicts the solution architecture.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. It automates capturing model metadata and increases predictive accuracy to identify how AI tools are used and where model training needs to be done again. Track models and drive transparent processes.
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. AnalyzeDocument Layout is a new feature that allows customers to automatically extract layout elements such as paragraphs, titles, subtitles, headers, footers, and more from documents.
Scientific metadata in research literature holds immense significance, as highlighted by flourishing research in scientometricsa discipline dedicated to analyzing scholarly literature. Metadata improves the findability and accessibility of scientific documents by indexing and linking papers in a massive graph.
More information about the settings for the shed load filter is in our NS1 documentation portal. Visit the NSI documentation portal today The post How to optimize application performance with NS1 traffic steering appeared first on IBM Blog.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content