

Streamline RAG applications with intelligent metadata filtering using Amazon Bedrock
NOVEMBER 20, 2024
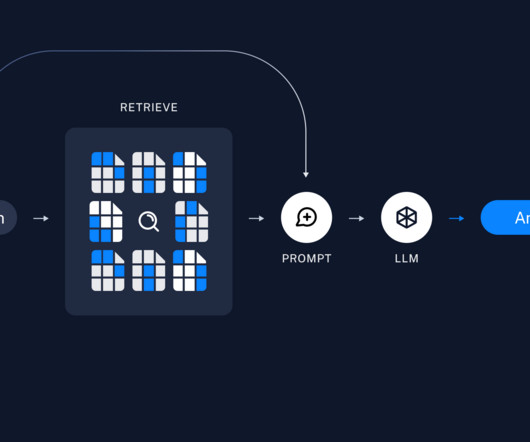
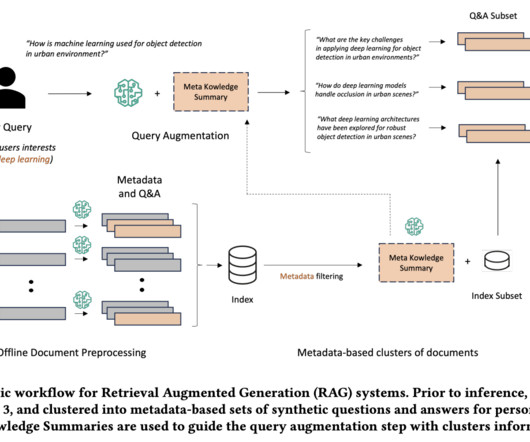
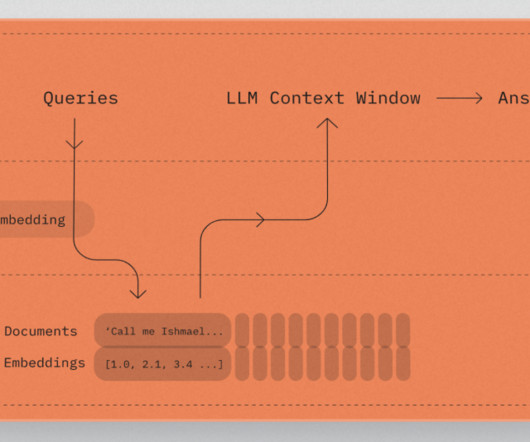
The effectiveness of RAG heavily depends on the quality of context provided to the large language model (LLM), which is typically retrieved from vector stores based on user queries. To address these challenges, you can use LLMs to create a robust solution.





































Let's personalize your content