This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Automated document fraud detection powered by AI offers a proactive solution, letting businesses to verify documents in real-time, detect anomalies, and prevent fraud before it occurs. Here is where AI-powered intelligent document processing (IDP) is changing the game. This is where intelligent document processing comes in.
A new study from researchers at LMU Munich, the Munich Center for Machine Learning, and Adobe Research has exposed a weakness in AI language models : they struggle to understand long documents in ways that might surprise you. Consider a medical researcher using AI to analyze patient records, or a legal team using AI to review case documents.
In simple terms, the AI first searches for relevant documents (like articles or webpages) related to a users query, and then uses those documents to generate a more accurate answer. Intuitively, one might think that the more documents an AI retrieves, the better informed its answer will be. The results were striking.
In an increasing number of industries, eDiscovery of regulation and compliance documents can make trading (across state borders in the US, for example) less complex. Predictive AI is used for classification of documents and generative AI helps with the review process for better, more defensible, downstream results.
Document-heavy workflows slow down productivity, bury institutional knowledge, and drain resources. Key Topics Covered: 🧠 Smarter Workflows: Understand the evolving role of AI in document management and knowledge automation. But with the right AI implementation, these inefficiencies become opportunities for transformation.
And that makes it a powerful tool for generating images of fraudulent documents, as users have found. Beyond faking expenses for lavish meals, OpenAI's increasingly canny ability to generate fake documents could open up the door for everything from phony tax forms and bank cheques to fake IDs and birth certificates.
Current text embedding models, like BERT, are limited to processing only 512 tokens at a time, which hinders their effectiveness with long documents. This limitation often results in loss of context and nuanced understanding.
Digital documents have long presented a dual challenge for both human readers and automated systems: preserving rich structural nuances while converting content into machine-processable formats. appeared first on Analytics Vidhya.
It excels in coding and front-end web development, achieving state-of-the-art performance on benchmarks […] The post Document Analysis with Claude 3.7 This model is the first of its kind to offer both modes within a single framework, mirroring human cognitive processes. Sonnet appeared first on Analytics Vidhya.
Speaker: Kaitlyn "The Persnickety Paralegal" Story
Understand how to identify key issues, potential witnesses, and relevant facts from these documents to ensure that the deposition is comprehensive and well-prepared. Leveraging Draft Pleadings for Deposition Preparation 📝 Gain insights into how to utilize drafts of pleadings to gather essential information for deposition preparation.
The document produced by the AI included supposed scholarly references that were neither verified nor accurate, yet the document did not disclose the use of AI in its preparation. Unfortunately, the document included six citations, four of which seemed to be from respected scientific journals.
More on AI: New York Times Encourages Staff to Create Headlines Using AI The post Large Law Firm Sends Panicked Email as It Realizes Its Attorneys Have Been Using AI to Prepare Court Documents appeared first on Futurism.
AI documentation generators — Automate inline comments, API documentation, and explanations. Kite Kite was a popular AI-powered autocomplete tool that provided developers with real-time code suggestions and documentation assistance. Inline documentation: Showed documentation snippets inside the IDE.
In their latest push for advancement, OpenAI is sharing two important documents on red teaming — a white paper detailing external engagement strategies and a research study introducing a novel method for automated red teaming.
Speaker: Joe Stephens, J.D., Attorney and Law Professor
will share proven techniques for anticipating attorney needs, organizing critical documents, and transforming complex information into compelling case presentations. Streamline Pre-Trial Workflow 📓 Develop reliable systems for managing deadlines, documents, and deliverables that keep your team on track.
This tech automatically breaks down source documents into digestible chunks and links every AI-generated statement back to its original source similar to how academic papers cite their references. Breaking Down the Technical Architecture The magic of Citations lies in its document processing approach. PDF handling is more complex.
According to documents recently submitted to the court, evidence reveals highly incriminating practices involving Metas senior leaders. Documents also revealed that top engineers hesitated to torrent the datasets, citing concerns about using corporate laptops for potentially unlawful activities.
Have you ever stared at a massive document with the deadline looming and thought, Theres no way Im getting through all of this? With NotebookLM, you upload the documents you care about, and it reads them. Pros and Cons Generates concise summaries of lengthy documents in seconds. Its your research sidekick. Your clutter-tamer.
For legal professionals, Jarvis could review large volumes of case documents and organise them by relevance, streamlining workflow. Privacy and security considerations Project Jarvis raises significant privacy and security issues due to its ability to access sensitive information such as emails and documents.
poolside’s malibu and point Designed to address challenges in modern software engineering, poolside’s models – malibu and point – specialise in code generation, testing, documentation, and real-time code completion. documents, video, and audio) into structured formats for analytics or retrieval-augmented generation (RAG).
In a significant advancement for document processing, Anthropic has unveiled new PDF support capabilities for its Claude 3.5 The integration arrives at a pivotal moment in the evolution of AI document processing, as businesses increasingly seek seamless solutions for handling complex documents containing both textual and visual elements.
This blog post walks you through an exciting project that harnesses the power of Google’s Gemini AI to create an intelligent English Educator Application that analyzes text documents and provides […] The post Building an English Educator App API with Google Gemini and FastAPI appeared first on Analytics Vidhya.
These platforms handle essential tasks like clinical documentation, medical imaging analysis, patient communications, and administrative workflows, letting providers focus on patient care. For clinical documentation, practitioners can access specialized tools and templates to streamline their note-taking and patient intake processes.
Upmetrics Key Features Here are Upmetrics' key features: Business Plan Builder & Templates Financial Forecasting & Modeling Tools Real-Time Collaboration Capabilities Document Sharing & Export Options Pitch Deck Creator Document Management System Integration with Other Tools 1. Give Upmetrics your basic assumptions (e.g.,
This free platform gives users a straightforward way to chat with documents, run AI agents, and handle various AI tasks while keeping all data secure on their own machines. The platform works with numerous document types – from PDFs and Word files to entire codebases – making it adaptable for diverse needs.
Instruct Models: Offering improved reasoning, multilingual capabilities, and extended context lengths up to 128K tokens, allowing the handling of longer documents and more complex instructions. Use Cases Cerebrium supports various applications, including: Translation : Translating documents, audio, and video across multiple languages.
The veterinary field is undergoing a transformation through AI-powered tools that enhance everything from clinical documentation to cancer treatment. Scribenote Scribenote is an AI-powered clinical documentation system where machine learning processes veterinary conversations in real-time to generate comprehensive medical records.
Imagine an AI that can write poetry, draft legal documents, or summarize complex research papersbut how do we truly measure its effectiveness? As Large Language Models (LLMs) blur the lines between human and machine-generated content, the quest for reliable evaluation metrics has become more critical than ever.
With a deep understanding of global healthcare systems and governance, he has been instrumental in developing innovative solutions that streamline clinical documentation and enhance operational efficiency. Working with the NHS provided invaluable insights into healthcare documentation challenges on a massive scale.
Ideally, this should reduce the amount of time a provider spends documenting within the EHR and allow for more quality time with the patient. Our AI-powered documentation solution is designed to streamline the care process beyond just transcription or drafting a SOAP note.
The Gauss Portal, another Gauss-powered AI service, enhances productivity through features such as document summarisation and translation. The coding assistant ‘code.i’ Since its launch, this AI service has expanded internationally, aiding various office tasks.
The results are presented in the chat as detailed, well-documented reports. Its ability to rigorously cite sources and provide comprehensive analysis sets it apartshifting the focus from fast, summarised answers to well-documented, research-grade insights. A sidebar provides updates on the actions taken and the sources consulted.
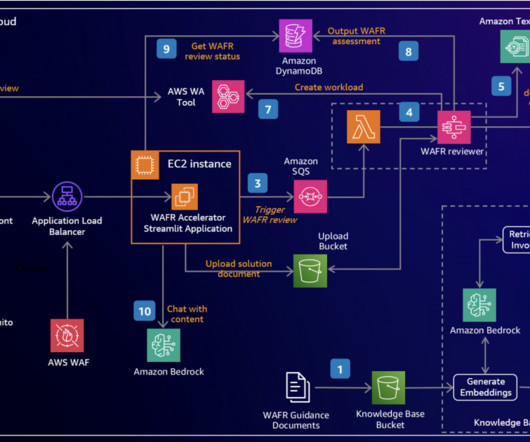
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. An interactive chat interface allows deeper exploration of both the original document and generated content.
AI in healthcare is causing a revolution in how clinicians document, analyze, and make decisions. AI Scribes: Redefining Clinical Documentation AI has a big influence on clinical documentation, which is one of the main areas it's changing. They also help make documentation more accurate and complete.
RAG combines the power of document retrieval with the […] The post Top 13 Advanced RAG Techniques for Your Next Project appeared first on Analytics Vidhya. And how do we keep it from confidently spitting out incorrect facts? These are the kinds of challenges that modern AI systems face, especially those built using RAG.
Yes, a document written over 240 […] The post Does the Rise of AI-generated Content Affect Model Training? Let’s find out! A recent tweet by Christopher Penn exposes a major flaw: an AI detector confidently declared that the US Declaration of Independence was 97% AI-generated. appeared first on Analytics Vidhya.
Jumio has processed over 1 billion transactions worldwide, supporting over 5,000 ID documents across more than 200 countries and territories. We’ve enhanced our liveness detection capabilities to further differentiate between real individuals and presented documents or deepfakes as hackers' techniques become more sophisticated.
You will need to track and document your creative process differently than before. Smart creators are now documenting their process in ways that highlight their creative control: saving iterations, tracking significant modifications, and maintaining clear records of their original contributions. Start with your creative vision.
The model’s tool use includes features like advanced search, document Q&A, image understanding, AI image generation, and webpage reading. As Baidu’s “first multimodal deep-thinking reasoning model capable of tool use,” X1 excels in areas like Chinese knowledge Q&A, literary creation, and complex calculations.
Retrievers play a crucial role in the LangChain framework by providing a flexible interface that returns documents based on unstructured queries. Unlike vector stores, retrievers are not required to store documents; their primary function is to retrieve relevant information.
It combines document processing and web search integration to simplify information retrieval and analysis. With so much happening in the Generative AI space, the need for tools that can efficiently process and retrieve information has never been greater.
Created by the Google Labs team, NotebookLM uses AI to analyze user-provided documents. Previously, to create a new notebook, you had to feed the AI documents, web links, YouTube videos, or raw text. The sources you select will be ingested as if they were documents you uploaded, creating a conversant AI for your chosen topic.
Diving into your document library for some queries while generating creative responses for others. Imagine having a personal research assistant who not only understands your question but intelligently decides how to find answers. This is what is possible with an Agentic RAG Using LlamaIndex TypeScript system.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content