This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
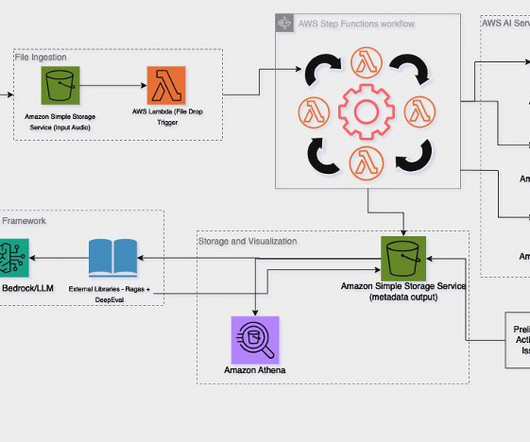
This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata. JupyterLab applications flexible and extensive interface can be used to configure and arrange machine learning (ML) workflows.
Deep Instinct is a cybersecurity company that applies deeplearning to cybersecurity. As I learned about the possibilities of predictive prevention technology, I quickly realized that Deep Instinct was the real deal and doing something unique. ML is unfit for the task. He holds a B.Sc Not all AI is equal.
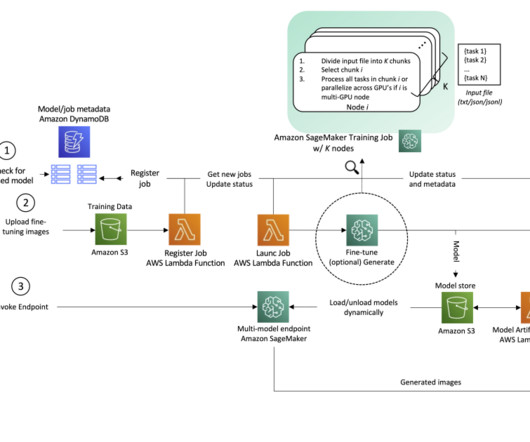
Amazon Bedrock offers fine-tuning capabilities that allow you to customize these pre-trained models using proprietary call transcript data, facilitating high accuracy and relevance without the need for extensive machine learning (ML) expertise. Architecture The following diagram illustrates the solution architecture.
This archive includes over 24 million image-text pairs from 6 million articles enriched with metadata and expert annotations. Articles and media files are downloaded from the NCBI server, extracting metadata, captions, and figure references from nXML files and the Entrez API. Dont Forget to join our 65k+ ML SubReddit.
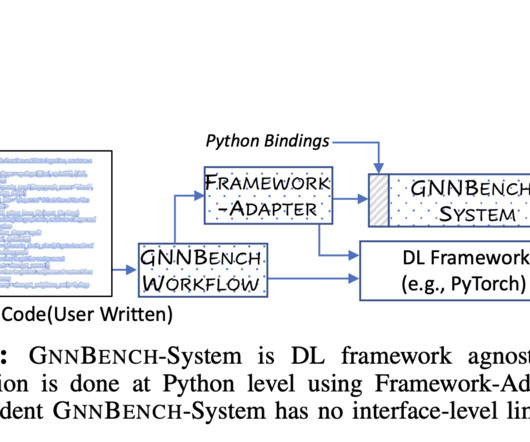
Existing benchmarks like Graph500 and LDBC need to be revised for GNNs due to differences in computations, storage, and reliance on deeplearning frameworks. PyTorch and TensorFlow plugins present limitations in accepting custom graph objects, while GNN operations require additional metadata in system APIs, leading to inconsistencies.
Whether youre new to Gradio or looking to expand your machine learning (ML) toolkit, this guide will equip you to create versatile and impactful applications. Using the Ollama API (this tutorial) To learn how to build a multimodal chatbot with Gradio, Llama 3.2, and the Ollama API, just keep reading. ollama/models directory.
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses.
Additionally, for every retrieval result you bring, you can provide a name and additional metadata in the form of key-value pairs. His expertise is in reproducible and end-to-end AI/ML methods, practical implementations, and helping global customers formulate and develop scalable solutions to interdisciplinary problems. are optional.
attempt to convert entire PDF pages into readable text using deeplearning. Image Source The core innovation behind olmOCR is document anchoring, a technique that combines textual metadata with image-based analysis. Also,feel free to follow us on Twitter and dont forget to join our 80k+ ML SubReddit.
Challenges in deploying advanced ML models in healthcare Rad AI, being an AI-first company, integrates machine learning (ML) models across various functions—from product development to customer success, from novel research to internal applications. Rad AI’s ML organization tackles this challenge on two fronts.
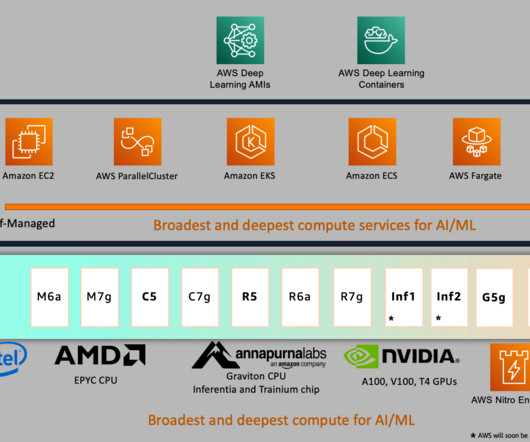
Trainium chips are purpose-built for deeplearning training of 100 billion and larger parameter models. Model training on Trainium is supported by the AWS Neuron SDK, which provides compiler, runtime, and profiling tools that unlock high-performance and cost-effective deeplearning acceleration. using the following code.
This capability enables organizations to create custom inference profiles for Bedrock base foundation models, adding metadata specific to tenants, thereby streamlining resource allocation and cost monitoring across varied AI applications. He focuses on Deeplearning including NLP and Computer Vision domains.
Model server overview A model server is a software component that provides a runtime environment for deploying and serving machine learning (ML) models. The primary purpose of a model server is to allow effortless integration and efficient deployment of ML models into production systems. For MMEs, each model.py The full model.py
After some impressive advances over the past decade, largely thanks to the techniques of Machine Learning (ML) and DeepLearning , the technology seems to have taken a sudden leap forward. 1] Users can access data through a single point of entry, with a shared metadata layer across clouds and on-premises environments.
It was in 2014 when ICML organized the first AutoML workshop that AutoML gained the attention of ML developers. A majority of these frameworks implement a general purpose AutoML solution that develops ML-based models automatically across different classes of applications across financial services, healthcare, education, and more.
In the past decade, Artificial Intelligence (AI) and Machine Learning (ML) have seen tremendous progress. Modern AI and ML models can seamlessly and accurately recognize objects in images or video files. There are two key factors that have massively contributed towards the boost in performance of these deeplearning models.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computer vision and natural language processing. This provides a major flexibility advantage over the majority of ML frameworks, which require neural networks to be defined as static objects before runtime.
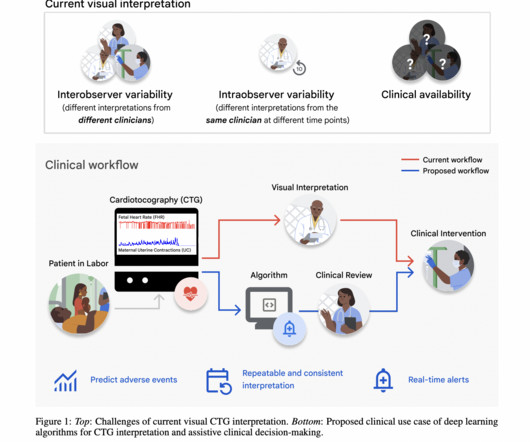
Google researchers addressed the challenge of variability and subjectivity in clinical experts’ interpretation of visual cardiotocography (CTG), specifically focusing on predicting fetal hypoxia, a dangerous condition of oxygen deprivation during labor, using deeplearning techniques. Don’t Forget to join our 50k+ ML SubReddit.
PyTorch is a machine learning (ML) framework that is widely used by AWS customers for a variety of applications, such as computer vision, natural language processing, content creation, and more. These are basically big models based on deeplearning techniques that are trained with hundreds of billions of parameters.
Spark NLP’s deeplearning models have achieved state-of-the-art results on sentiment analysis tasks, thanks to their ability to automatically learn features and representations from raw text data. There are separate blog posts for the rule-based systems and for statistical methods.
Copy Code Copied Use a different Browser import torch import torchxrayvision as xrv import torchvision.transforms as transforms import gradio as gr We import PyTorch for deeplearning operations, TorchXRayVision for Xray analysis, torchvision’s transforms for image preprocessing, and Gradio for building an interactive UI.
Amazon Personalize makes it straightforward to personalize your website, app, emails, and more, using the same machine learning (ML) technology used by Amazon, without requiring ML expertise. If you use Amazon Personalize with generative AI, you can also feed the metadata into prompts. compared to previous versions.
Traditionally, academic benchmarks for tabular ML have not fully represented the complexities encountered in real-world industrial applications. Such limitations can lead to overly optimistic performance estimates when models evaluated on these benchmarks are deployed in real-world ML production scenarios.
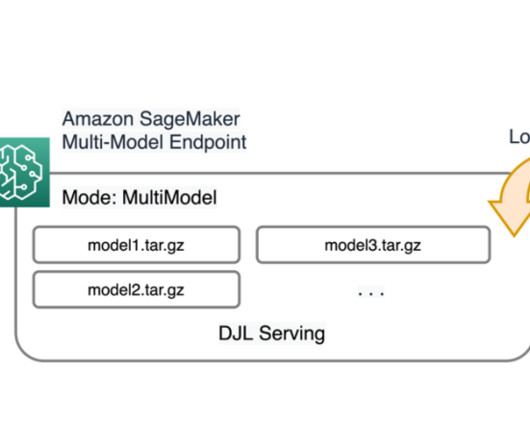
SageMaker provides single model endpoints (SMEs), which allow you to deploy a single ML model, or multi-model endpoints (MMEs), which allow you to specify multiple models to host behind a logical endpoint for higher resource utilization. TensorRT is an SDK developed by NVIDIA that provides a high-performance deeplearning inference library.
For more information about multi-GPU hosting, refer to How Mantium achieves low-latency GPT-J inference with DeepSpeed on Amazon SageMaker and Deploy BLOOM-176B and OPT-30B on Amazon SageMaker with large model inference DeepLearning Containers and DeepSpeed. We discuss more considerations on concurrency in the next section.
This approach allows for greater flexibility and integration with existing AI and machine learning (AI/ML) workflows and pipelines. By providing multiple access points, SageMaker JumpStart helps you seamlessly incorporate pre-trained models into your AI/ML development efforts, regardless of your preferred interface or workflow.
Knowledge and skills in the organization Evaluate the level of expertise and experience of your ML team and choose a tool that matches their skill set and learning curve. Model monitoring and performance tracking : Platforms should include capabilities to monitor and track the performance of deployed ML models in real-time.
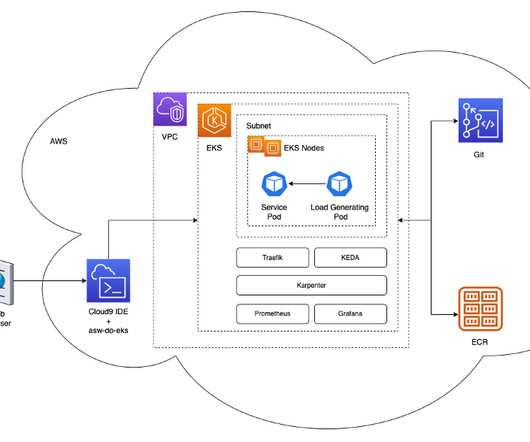
This solution simplifies the integration of advanced monitoring tools such as Prometheus and Grafana, enabling you to set up and manage your machine learning (ML) workflows with AWS AI Chips. By deploying the Neuron Monitor DaemonSet across EKS nodes, developers can collect and analyze performance metrics from ML workload pods.
Then, they manually tag the content with metadata such as romance, emotional, or family-friendly to verify appropriate ad matching. The downstream system ( AWS Elemental MediaTailor ) can consume the chapter segmentation, contextual insights, and metadata (such as IAB taxonomy) to drive better ad decisions in the video.
Our deeplearning models have non-trivial requirements: they are gigabytes in size, are numerous and heterogeneous, and require GPUs for fast inference and fine-tuning. v1alpha5 kind: ClusterConfig metadata: name: do-eks-yaml-karpenter version: '1.28' region: us-west-2 tags: karpenter.sh/discovery:
In this comprehensive guide, we’ll explore the key concepts, challenges, and best practices for ML model packaging, including the different types of packaging formats, techniques, and frameworks. So, let’s dive in and discover everything you need to know about model packaging in machine learning.
When working on real-world machine learning (ML) use cases, finding the best algorithm/model is not the end of your responsibilities. Reusability & reproducibility: Building ML models is time-consuming by nature. Save vs package vs store ML models Although all these terms look similar, they are not the same.
release , you can now launch Neuron DLAMIs (AWS DeepLearning AMIs) and Neuron DLCs (AWS DeepLearning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. AWS DLCs provide a set of Docker images that are pre-installed with deeplearning frameworks.
Even today, a vast chunk of machine learning and deeplearning techniques for AI models rely on a centralized model that trains a group of servers that run or train a specific model against training data, and then verifies the learning using validation or training dataset.
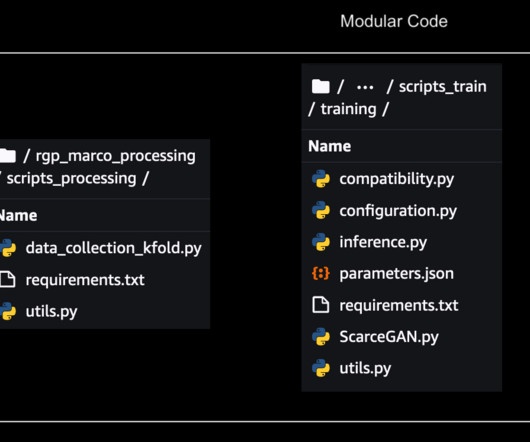
They’ve built a deep-learning model ScarceGAN, which focuses on identification of extremely rare or scarce samples from multi-dimensional longitudinal telemetry data with small and weak labels. There was no mechanism to pass and store the metadata of the multiple experiments done on the model.
Carl Froggett, is the Chief Information Officer (CIO) of Deep Instinct , an enterprise founded on a simple premise: that deeplearning , an advanced subset of AI, could be applied to cybersecurity to prevent more threats, faster. But not all AI is created equal. This makes it extremely fast and privacy-friendly.
This post gives a brief overview of modularity in deeplearning. Fuelled by scaling laws, state-of-the-art models in machine learning have been growing larger and larger. We give an in-depth overview of modularity in our survey on Modular DeepLearning. Case studies of modular deeplearning.
In this post, we discuss deploying scalable machine learning (ML) models for diarizing media content using Amazon SageMaker , with a focus on the WhisperX model. With manual methods, a 30-minute episode can take between 1–3 hours to localize. Through automation, ZOO Digital aims to achieve localization in under 30 minutes.
Training machine learning (ML) models to interpret this data, however, is bottlenecked by costly and time-consuming human annotation efforts. One way to overcome this challenge is through self-supervised learning (SSL). Additionally, each folder contains a JSON file with the image metadata. tif" --include "_B03.tif"
The embedding representations of text chunks along with related metadata are indexed in OpenSearch Service. Text embedding models are machine learning (ML) models that map words or phrases from text to dense vector representations. The application uses Amazon Textract to get the text and tables from the input documents.
Light & Wonder teamed up with the Amazon ML Solutions Lab to use events data streamed from LnW Connect to enable machine learning (ML)-powered predictive maintenance for slot machines. Predictive maintenance is a common ML use case for businesses with physical equipment or machinery assets.
Amazon SageMaker Serverless Inference is a purpose-built inference service that makes it easy to deploy and scale machine learning (ML) models. In this phase, you submit a text search query or image search query through the deeplearning model (CLIP) to encode as embeddings. We use the first metadata file in this demo.
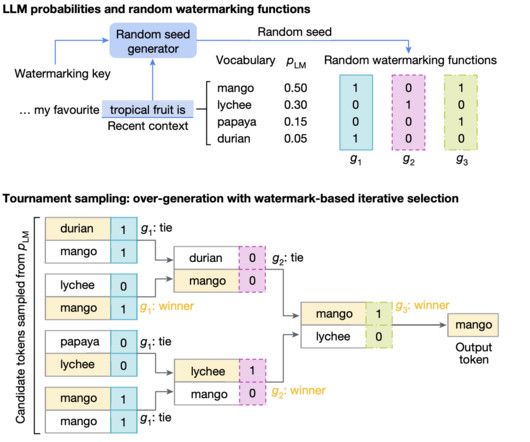
Technical Overview and Benefits of SynthID SynthID integrates an imperceptible watermark directly into AI-generated text using advanced deeplearning models. By embedding metadata-like signals that work across AI text formats, SynthID can determine whether a given text is AI-generated.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content