This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Bedrock Knowledge Bases has a metadata filtering capability that allows you to refine search results based on specific attributes of the documents, improving retrieval accuracy and the relevance of responses. These metadata filters can be used in combination with the typical semantic (or hybrid) similarity search.
Deep Instinct is a cybersecurity company that applies deeplearning to cybersecurity. As I learned about the possibilities of predictive prevention technology, I quickly realized that Deep Instinct was the real deal and doing something unique. He holds a B.Sc Not all AI is equal.
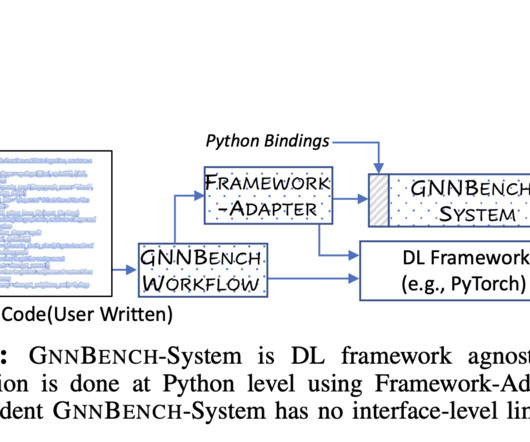
Existing benchmarks like Graph500 and LDBC need to be revised for GNNs due to differences in computations, storage, and reliance on deeplearning frameworks. PyTorch and TensorFlow plugins present limitations in accepting custom graph objects, while GNN operations require additional metadata in system APIs, leading to inconsistencies.
This archive includes over 24 million image-text pairs from 6 million articles enriched with metadata and expert annotations. Articles and media files are downloaded from the NCBI server, extracting metadata, captions, and figure references from nXML files and the Entrez API.
Artificial Intelligence is a very vast branch in itself with numerous subfields including deeplearning, computer vision , natural language processing , and more. Another subfield that is quite popular amongst AI developers is deeplearning, an AI technique that works by imitating the structure of neurons.
Model Manifests: Metadata files describing the models architecture, hyperparameters, and version details, helping with integration and version tracking. Do you think learning computer vision and deeplearning has to be time-consuming, overwhelming, and complicated? ollama/models directory. Thats not the case.
attempt to convert entire PDF pages into readable text using deeplearning. Image Source The core innovation behind olmOCR is document anchoring, a technique that combines textual metadata with image-based analysis. These include tools like Grobid and VILA, which are designed for scientific papers.
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses.
This capability enables organizations to create custom inference profiles for Bedrock base foundation models, adding metadata specific to tenants, thereby streamlining resource allocation and cost monitoring across varied AI applications. He focuses on Deeplearning including NLP and Computer Vision domains.
However, as technology advanced, so did the complexity and capabilities of AI music generators, paving the way for deeplearning and Natural Language Processing (NLP) to play pivotal roles in this tech. Today platforms like Spotify are leveraging AI to fine-tune their users' listening experiences.
The term “deepfake” is derived from the technology creating this particular style of manipulated content (or “fake”) requiring the use of deeplearning techniques. However, these current security solutions in place, which use metadata analysis, cannot stop bad actors.
Trainium chips are purpose-built for deeplearning training of 100 billion and larger parameter models. Model training on Trainium is supported by the AWS Neuron SDK, which provides compiler, runtime, and profiling tools that unlock high-performance and cost-effective deeplearning acceleration. using the following code.
Spark NLP’s deeplearning models have achieved state-of-the-art results on sentiment analysis tasks, thanks to their ability to automatically learn features and representations from raw text data. During training, the model learns to identify patterns and features that are indicative of a certain sentiment.
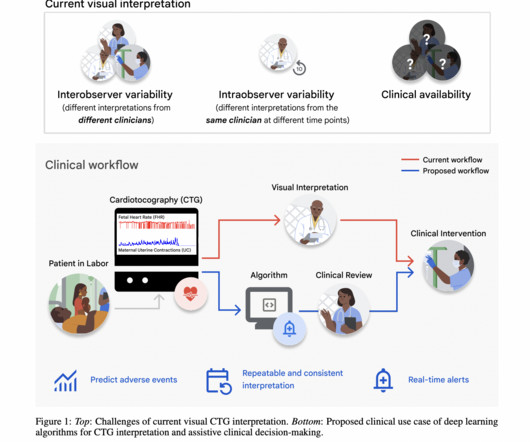
Google researchers addressed the challenge of variability and subjectivity in clinical experts’ interpretation of visual cardiotocography (CTG), specifically focusing on predicting fetal hypoxia, a dangerous condition of oxygen deprivation during labor, using deeplearning techniques. Click here to set up a call!
After some impressive advances over the past decade, largely thanks to the techniques of Machine Learning (ML) and DeepLearning , the technology seems to have taken a sudden leap forward. 1] Users can access data through a single point of entry, with a shared metadata layer across clouds and on-premises environments.
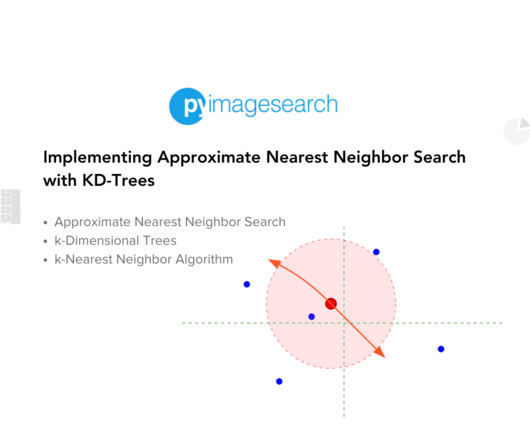
Jump Right To The Downloads Section Introduction to Approximate Nearest Neighbor Search In high-dimensional data, finding the nearest neighbors efficiently is a crucial task for various applications, including recommendation systems, image retrieval, and machine learning. product specifications, movie metadata, documents, etc.)
SEER or SElf-supERvised Model: An Introduction Recent trends in the AI & ML industry have indicated that model pre-training approaches like semi-supervised, weakly-supervised, and self-supervised learning can significantly improve the performance for most deeplearning models for downstream tasks.
Third, the NLP Preset is capable of combining tabular data with NLP or Natural Language Processing tools including pre-trained deeplearning models and specific feature extractors. Next, the LightAutoML inner datasets contain CV iterators and metadata that implement validation schemes for the datasets.
Deeplearning is one of the most crucial tools for analyzing massive amounts of data. However, there is such a prospect as too much information, as deeplearning’s job is to find patterns and connections between data points to inform humanity’s questions and affirm assertions.
Return item metadata in inference responses – The new recipes enable item metadata by default without extra charge, allowing you to return metadata such as genres, descriptions, and availability in inference responses. If you use Amazon Personalize with generative AI, you can also feed the metadata into prompts.
ChatGPT was the first but today there are many competitors ChatGPT uses a deeplearning architecture call the Transformer and represents a significant advancement in the field of NLP. Automatic capture of model metadata and facts provide audit support while driving transparent and explainable model outcomes.
This post gives a brief overview of modularity in deeplearning. Fuelled by scaling laws, state-of-the-art models in machine learning have been growing larger and larger. We give an in-depth overview of modularity in our survey on Modular DeepLearning. Case studies of modular deeplearning.
Even today, a vast chunk of machine learning and deeplearning techniques for AI models rely on a centralized model that trains a group of servers that run or train a specific model against training data, and then verifies the learning using validation or training dataset.
Most available datasets either lack the temporal metadata necessary for time-based splits or come from less extensive data acquisition and feature engineering pipelines compared to common industry ML practices. TabReD bridges the gap between academic research and industrial application in tabular machine learning.
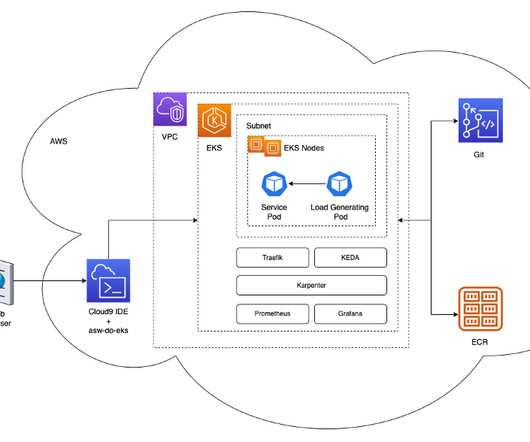
Our deeplearning models have non-trivial requirements: they are gigabytes in size, are numerous and heterogeneous, and require GPUs for fast inference and fine-tuning. v1alpha5 kind: ClusterConfig metadata: name: do-eks-yaml-karpenter version: '1.28' region: us-west-2 tags: karpenter.sh/discovery:
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Can you compare images?
About the Authors Ying Hou, PhD , is a Machine Learning Prototyping Architect at AWS. Her primary areas of interest encompass DeepLearning, with a focus on GenAI, Computer Vision, NLP, and time series data prediction. __dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir": in a code subdirectory. in a code subdirectory.
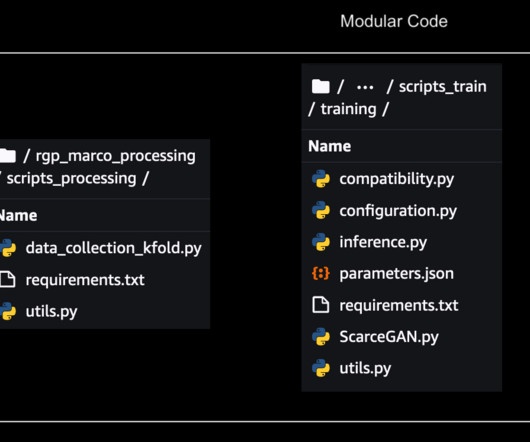
They’ve built a deep-learning model ScarceGAN, which focuses on identification of extremely rare or scarce samples from multi-dimensional longitudinal telemetry data with small and weak labels. There was no mechanism to pass and store the metadata of the multiple experiments done on the model.
The embedding representations of text chunks along with related metadata are indexed in OpenSearch Service. In addition to the embedding vector, the text chunk and document metadata such as document, document section name, or document release date are also added to the index as text fields.
The pipeline begins when researchers manage tags and metadata on the corresponding model artifact. Dmitry Soldatkin is a Senior Machine Learning Solutions Architect at Amazon Web Services (AWS), helping customers design and build AI/ML solutions. He has a passion for continuous innovation and using data to drive business outcomes.
A complete guide to building a deeplearning project with PyTorch, tracking an Experiment with Comet ML, and deploying an app with Gradio on HuggingFace Image by Freepik AI tools such as ChatGPT, DALL-E, and Midjourney are increasingly becoming a part of our daily lives. These tools were developed with deeplearning techniques.
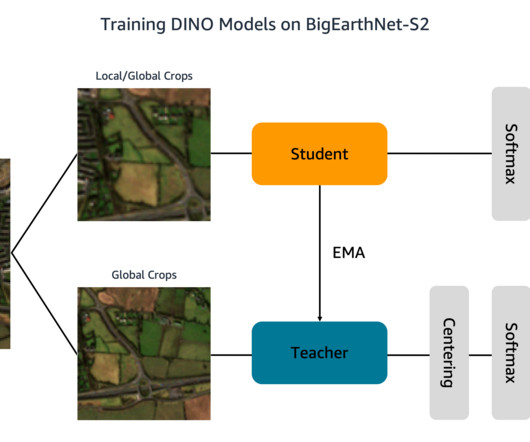
Additionally, each folder contains a JSON file with the image metadata. To perform statistical analyses of the data and load images during DINO training, we process the individual metadata files into a common geopandas Parquet file. We store the BigEarthNet-S2 images and metadata file in an S3 bucket. tif" --include "_B03.tif"
In this section, you will see different ways of saving machine learning (ML) as well as deeplearning (DL) models. Saving deeplearning model with TensorFlow Keras TensorFlow is a popular framework for training DL-based models, and Ker as is a wrapper for TensorFlow. Now let’s see how we can save our model.
We can use this opportunity to not only convert these images from JPG to TFRecords, but when converting them, we can even write them with their appropriate label and any other metadata we wish to store with the image itself. def parse_labels(metadata): def inner(img_name): str_img_name = img_name.numpy().decode("utf-8")
release , you can now launch Neuron DLAMIs (AWS DeepLearning AMIs) and Neuron DLCs (AWS DeepLearning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. AWS DLCs provide a set of Docker images that are pre-installed with deeplearning frameworks.
Carl Froggett, is the Chief Information Officer (CIO) of Deep Instinct , an enterprise founded on a simple premise: that deeplearning , an advanced subset of AI, could be applied to cybersecurity to prevent more threats, faster. We’ve entered a pivotal time, one that requires organizations to fight AI with AI.
Big foundational models like CLIP, Stable Diffusion, and Flamingo have radically improved multimodal deeplearning over the past few years. Multimodal deeplearning, as of 2023, is still primarily concerned with text-image modeling, with only limited attention paid to additional modalities like video (and audio).
Achieve low latency on GPU instances via TensorRT TensorRT is a C++ library for high-performance inference on NVIDIA GPUs and deeplearning accelerators, supporting major deeplearning frameworks such as PyTorch and TensorFlow. Previous studies have shown great performance improvement in terms of model latency.
Two-Tower Model The two-tower model, also known as the dual-tower model, is a deeplearning architecture widely used in recommendation systems. Item Tower: Encodes item features like metadata, content characteristics, and contextual information.
In this phase, you submit a text search query or image search query through the deeplearning model (CLIP) to encode as embeddings. The dataset is a collection of 147,702 product listings with multilingual metadata and 398,212 unique catalogue images. We use the first metadata file in this demo. contains image metadata.
In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machine learning accelerator designed by AWS. Trn1 instances are purpose built for high-performance deeplearning model training while offering up to 50% cost-to-train savings over comparable GPU-based instances.
tolist() embeddings = embed_docs(texts) # create records list for upsert records = zip(ids, embeddings, metadatas) # upsert to Pinecone index.upsert(vectors=records) You can begin querying the index with the question from earlier in this post. He focuses on developing scalable machine learning algorithms.
This post further walks through a step-by-step implementation of fine-tuning a RoBERTa (Robustly Optimized BERT Pretraining Approach) model for sentiment analysis using AWS DeepLearning AMIs (AWS DLAMI) and AWS DeepLearning Containers (DLCs) on Amazon Elastic Compute Cloud (Amazon EC2 p4d.24xlarge)
In other news, OpenAI’s image generator DALL-E 3 will add watermarks to image C2PA metadata as more companies roll out support for standards from the Coalition for Content Provenance and Authenticity (C2PA). This move is aimed as a step towards improving the trustworthiness of digital information.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































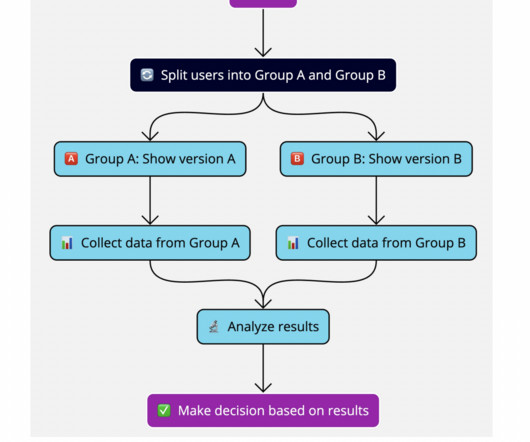


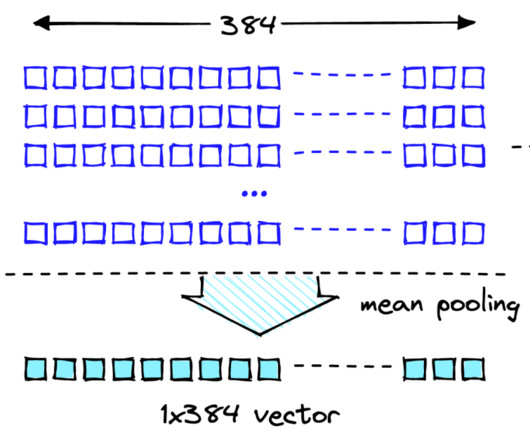
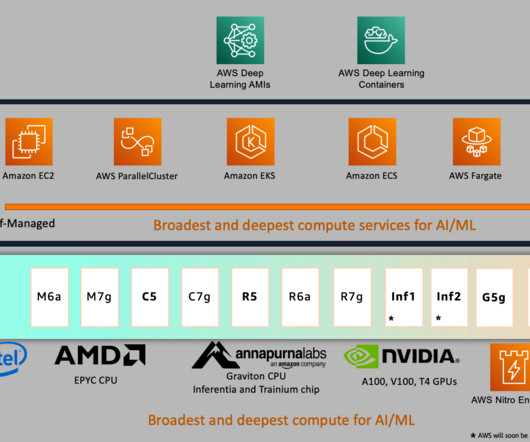
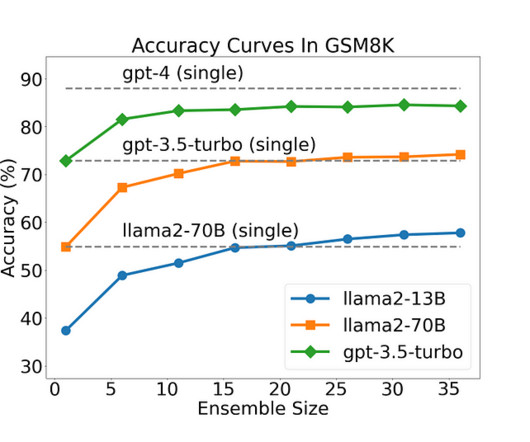






Let's personalize your content