This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
At the core of its performance are its advanced reasoning models, powered by cutting-edge deeplearning techniques. This ability is supported by advanced technical components like inferenceengines and knowledge graphs, which enhance its reasoning skills.
Ensuring consistent access to a single inferenceengine or database connection. Example : In AI, a Factory pattern might dynamically generate a deeplearning model based on the task type and hardware constraints, whereas in traditional systems, it might simply generate a user interface component. model hyperparameters).
attempt to convert entire PDF pages into readable text using deeplearning. Compatible with inferenceengines like vLLM and SGLang, allowing flexible deployment on various hardware setups. These include tools like Grobid and VILA, which are designed for scientific papers.
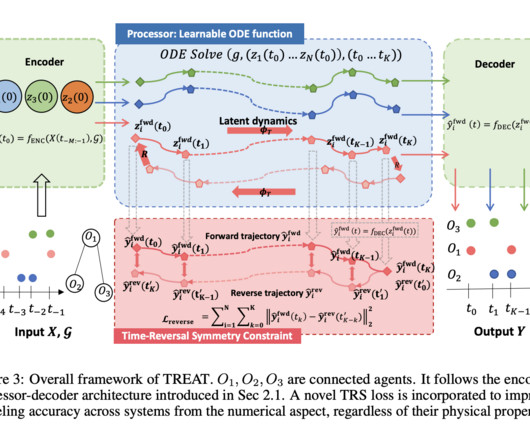
Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post TREAT: A DeepLearning Framework that Achieves High-Precision Modeling for a Wide Range of Dynamical Systems by Injecting Time-Reversal Symmetry as an Inductive Bias appeared first on MarkTechPost.
AI processes large datasets to identify patterns and build adaptive models, particularly in deeplearning for medical image analysis, such as X-rays and MRIs. These systems rely on a domain knowledge base and an inferenceengine to solve specialized medical problems.
The Rise of CUDA-Accelerated AI Frameworks GPU-accelerated deeplearning has been fueled by the development of popular AI frameworks that leverage CUDA for efficient computation. NVIDIA TensorRT , a high-performance deeplearninginference optimizer and runtime, plays a vital role in accelerating LLM inference on CUDA-enabled GPUs.
These improvements are available across a wide range of SageMaker’s DeepLearning Containers (DLCs), including Large Model Inference (LMI, powered by vLLM and multiple other frameworks), Hugging Face Text Generation Inference (TGI), PyTorch (Powered by TorchServe), and NVIDIA Triton. gpu-py311-cu124-ubuntu22.04-v2.0",
You will use DeepLearning AMI Neuron (Ubuntu 22.04) as your AMI, as shown in the following figure. You can reattach to your Docker container and stop the online inference server with the following: docker attach $(docker ps --format "{{.ID}}") You will use inf2.xlarge xlarge as your instance type. top_p=0.95) # Create an LLM.
In particular, the release targets bottlenecks experienced in transformer models and LLMs (Large Language Models), the ongoing need for GPU optimizations, and the efficiency of training and inference for both research and production settings. The new PyTorch release brings exciting new features to its widely adopted deeplearning framework.
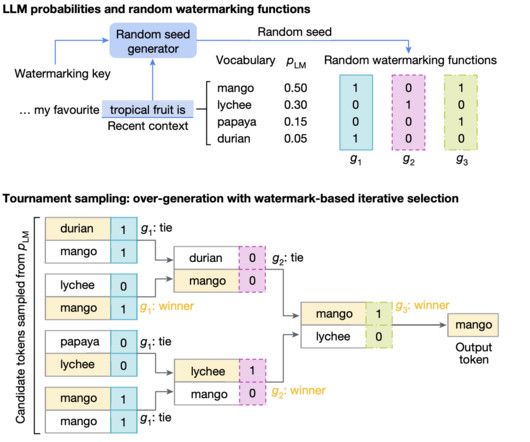
Technical Overview and Benefits of SynthID SynthID integrates an imperceptible watermark directly into AI-generated text using advanced deeplearning models. This move is a significant step toward enhancing the safety, transparency, and traceability of AI-generated content, fostering greater trust in the expanding AI ecosystem.
Google for Startups Cloud Program members can join NVIDIA Inception and gain access to technological expertise, NVIDIA DeepLearning Institute course credits, NVIDIA hardware and software, and more.
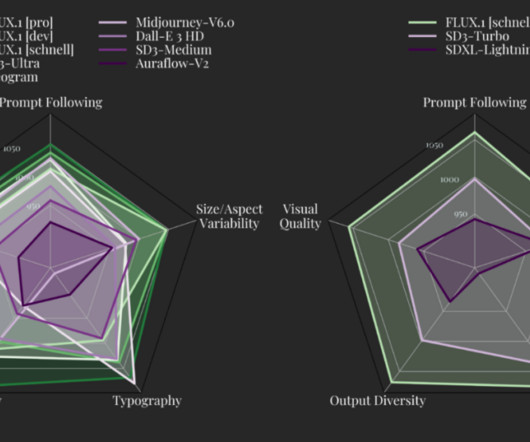
Their mission is clear: to develop and advance state-of-the-art generative deeplearning models for media such as images and videos, while pushing the boundaries of creativity, efficiency, and diversity. Black Forest Labs Open-Source FLUX.1 Introducing the Flux Model Family Black Forest Labs has introduced the FLUX.1
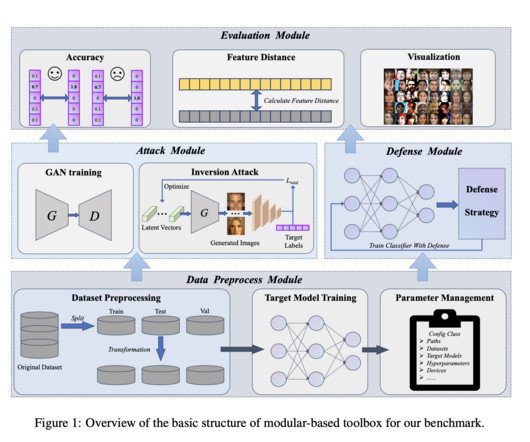
raising widespread concerns about privacy threats of Deep Neural Networks (DNNs). Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase InferenceEngine (Promoted) The post MIBench: A Comprehensive AI Benchmark for Model Inversion Attack and Defense appeared first on MarkTechPost.
RTX GPUs also take advantage of Tensor Cores — dedicated AI accelerators that dramatically speed up the computationally intensive operations required for deeplearning and generative AI models. The team of AI researchers and engineers behind the open-source Jan.ai Source: Jan.ai
We address this challenge in our work titled “ Speed Is All You Need: On-Device Acceleration of Large Diffusion Models via GPU-Aware Optimizations ” (to be presented at the CVPR 2023 workshop for Efficient DeepLearning for Computer Vision ) focusing on the optimized execution of a foundational LDM model on a mobile GPU.
Due to its many benefits over server-based methods, such as lower latency, increased privacy, and greater scalability, on-device model inference acceleration has recently attracted much interest. In light of the limitations of standard fusion rules, they devised custom implementations capable of running a wider variety of neural operators.
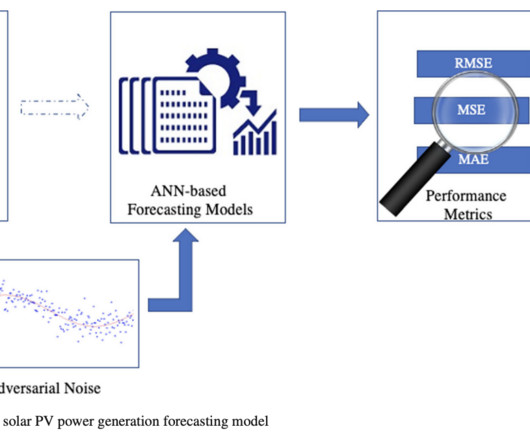
Deeplearning-based prediction is critical for optimizing output, anticipating weather fluctuations, and improving solar system efficiency, allowing for more intelligent energy network management. More sophisticated machine learning approaches, such as artificial neural networks (ANNs), may detect complex relationships in data.
TensorRT is an SDK developed by NVIDIA that provides a high-performance deeplearninginference library. It’s optimized for NVIDIA GPUs and provides a way to accelerate deeplearninginference in production environments. Triton Inference Server supports ONNX as a model format.
Scikit-Learn: Scikit-Learn is a machine learning library that makes it easy to train and deploy machine learning models. It has a wide range of features, including data preprocessing, feature extraction, deeplearning training, and model evaluation. How Do I Use These Libraries?
amazonaws.com/djl-inference:0.21.0-deepspeed0.8.3-cu117" cu117" ) print(f"Image going to be used is - > {inference_image_uri}") In addition to that, we need to have a serving.properties file that configures the serving properties, including the inferenceengine to use, the location of the model artifact, and dynamic batching.
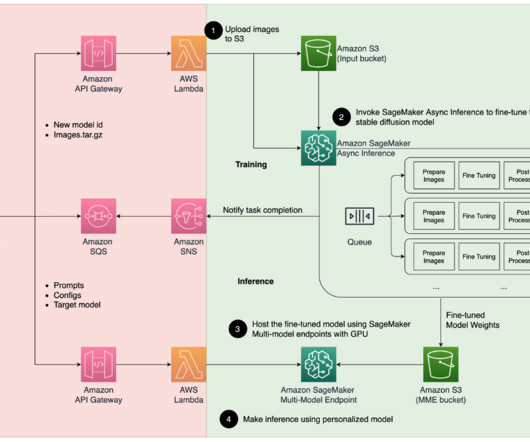
The accomplishments of deeplearning are essentially just a type of curve fitting, whereas causality could be used to uncover interactions between the systems of the world under various constraints without testing hypotheses directly. The causal inferenceengine is deployed with Amazon SageMaker Asynchronous Inference.
Conclusions In this post, I discussed how to integrate the C++ code with the NCNN inferenceengine into Android for model deployment on the mobile phone. You can easily tailor the pipeline for deploying your deeplearning models on mobile devices. Hope these series of posts help. Thanks for reading. 2] Android.
GitHub: Tencent/TurboTransformers Make transformers serving fast by adding a turbo to your inferenceengine!Transformer The sell is that it can support various lengths of input sequences without preprocessing which reduces overhead in computation. ? These 2 repos encompass NLP and Speech modeling.
Fluid AI taps NVIDIA NIM microservices, the NVIDIA NeMo platform and the NVIDIA TensorRT inferenceengine to deliver a complete, scalable platform for developing custom generative AI for its customers.
Credits A critical component for these robots is to identify different objects and take actions accordingly and this is where DeepLearning and Machine Vision enters the space!!! On an Nvidia V-100 GPU, the detector runs at 15 fps on average.
Large Action Models (LAMs) are deeplearning models that aim to understand instructions and execute complex tasks and actions accordingly. It uses formal languages, like first-order logic, to represent knowledge and an inferenceengine to draw logical conclusions based on user queries. Symbolic AI Mechanism.
Normalization layers: Like many deeplearning models, SSMs often incorporate normalization layers (e.g., Skip connections: These are used to facilitate gradient flow in deep SSM architectures, similar to their use in other deep neural networks. LayerNorm) to stabilize training.
Support for DeepLearning Libraries Model Explorer demonstrates extensive support for various deeplearning frameworks: JAX : Supports graph formats used by JAX, enabling visualization of models built with this framework. The code is available in GitHub. For additional information about Gemma, see ai.google.dev/gemma.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content