This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
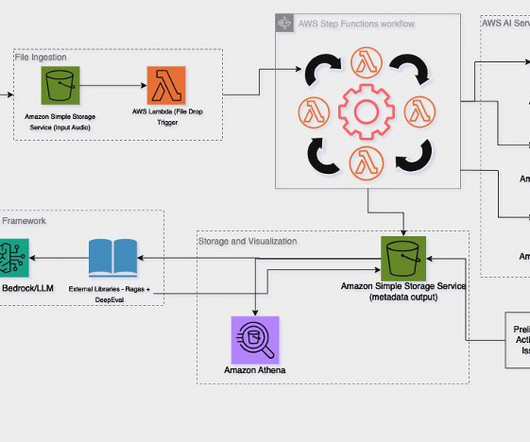
This post is part of an ongoing series about governing the machine learning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. The data mesh is a modern approach to data management that decentralizes data ownership and treats data as a product.
Machine learning (ML) has become a critical component of many organizations’ digital transformation strategy. From predicting customer behavior to optimizing business processes, ML algorithms are increasingly being used to make decisions that impact business outcomes.
This enables the efficient processing of content, including scientific formulas and data visualizations, and the population of Amazon Bedrock Knowledge Bases with appropriate metadata. JupyterLab applications flexible and extensive interface can be used to configure and arrange machine learning (ML) workflows.
Recently, we’ve been witnessing the rapid development and evolution of generative AI applications, with observability and evaluation emerging as critical aspects for developers, datascientists, and stakeholders.
With metadata filtering now available in Knowledge Bases for Amazon Bedrock, you can define and use metadata fields to filter the source data used for retrieving relevant context during RAG. This helps improve the relevance and quality of retrieved context while reducing potential hallucinations or noise from irrelevant data.
A data lakehouse architecture combines the performance of data warehouses with the flexibility of data lakes, to address the challenges of today’s complex data landscape and scale AI. New insights and relationships are found in this combination. All of this supports the use of AI.
From Solo Notebooks to Collaborative Powerhouse: VS Code Extensions for Data Science and ML Teams Photo by Parabol | The Agile Meeting Toolbox on Unsplash In this article, we will explore the essential VS Code extensions that enhance productivity and collaboration for datascientists and machine learning (ML) engineers.
It stores information such as job ID, status, creation time, and other metadata. The following is a screenshot of the DynamoDB table where you can track the job status and other types of metadata related to the job. With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value.
After some impressive advances over the past decade, largely thanks to the techniques of Machine Learning (ML) and Deep Learning , the technology seems to have taken a sudden leap forward. Through workload optimization an organization can reduce data warehouse costs by up to 50 percent by augmenting with this solution. [1] But why now?
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries.
Although AutoML rose to popularity a few years ago, the ealy work on AutoML dates back to the early 90’s when scientists published the first papers on hyperparameter optimization. It was in 2014 when ICML organized the first AutoML workshop that AutoML gained the attention of ML developers.
For instance, according to International Data Corporation (IDC), the world’s data volume is expected to increase tenfold by 2025, with unstructured data accounting for a significant portion. The custom metadata helps organizations and enterprises categorize information in their preferred way.
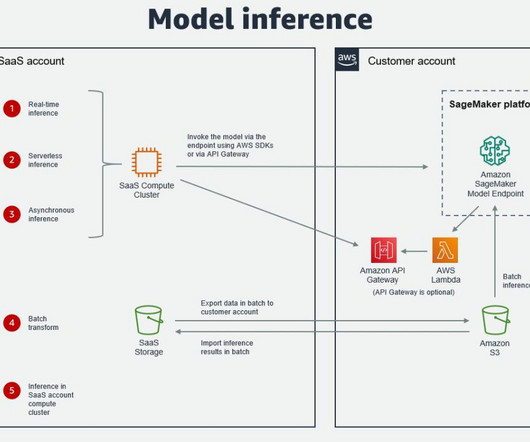
Real-world applications vary in inference requirements for their artificial intelligence and machine learning (AI/ML) solutions to optimize performance and reduce costs. SageMaker Model Monitor monitors the quality of SageMaker ML models in production. Your client applications invoke this endpoint to get inferences from the model.
Employees and managers see different levels of company policy information, with managers getting additional access to confidential data like performance review and compensation details. The role information is also used to configure metadata filtering in the knowledge bases to generate relevant responses.
Amazon Bedrock offers fine-tuning capabilities that allow you to customize these pre-trained models using proprietary call transcript data, facilitating high accuracy and relevance without the need for extensive machine learning (ML) expertise. Architecture The following diagram illustrates the solution architecture.
Additionally, for every retrieval result you bring, you can provide a name and additional metadata in the form of key-value pairs. His expertise is in reproducible and end-to-end AI/ML methods, practical implementations, and helping global customers formulate and develop scalable solutions to interdisciplinary problems. are optional.
Many organizations choose SageMaker as their ML platform because it provides a common set of tools for developers and datascientists. This is usually in a dedicated customer AWS account, meaning there still needs to be cross-account access to the customer AWS account where SageMaker is running.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
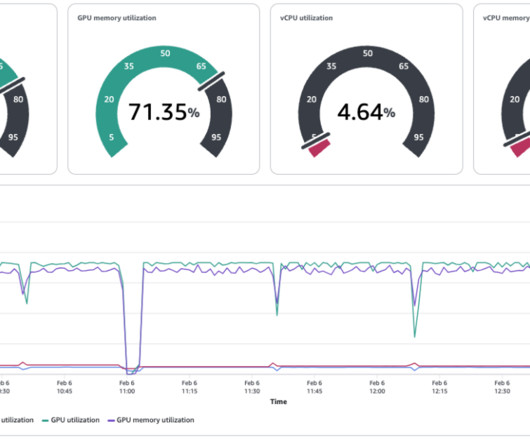
In this example, the ML engineering team is borrowing 5 GPUs for their training task With SageMaker HyperPod, you can additionally set up observability tools of your choice. Datascientist experience Datascientists are the second persona interacting with SageMaker HyperPod clusters.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
FMEval is an open source LLM evaluation library, designed to provide datascientists and machine learning (ML) engineers with a code-first experience to evaluate LLMs for various aspects, including accuracy, toxicity, fairness, robustness, and efficiency. This allows you to keep track of your ML experiments.
You can use Amazon SageMaker Model Building Pipelines to collaborate between multiple AI/ML teams. SageMaker Pipelines You can use SageMaker Pipelines to define and orchestrate the various steps involved in the ML lifecycle, such as data preprocessing, model training, evaluation, and deployment.
is our enterprise-ready next-generation studio for AI builders, bringing together traditional machine learning (ML) and new generative AI capabilities powered by foundation models. Automated development: Automates data preparation, model development, feature engineering and hyperparameter optimization using AutoAI. IBM watsonx.ai
Introduction to AI and Machine Learning on Google Cloud This course introduces Google Cloud’s AI and ML offerings for predictive and generative projects, covering technologies, products, and tools across the data-to-AI lifecycle. It includes labs on feature engineering with BigQuery ML, Keras, and TensorFlow.
This involves unifying and sharing a single copy of data and metadata across IBM® watsonx.data ™, IBM® Db2 ®, IBM® Db2® Warehouse and IBM® Netezza ®, using native integrations and supporting open formats, all without the need for migration or recataloging.
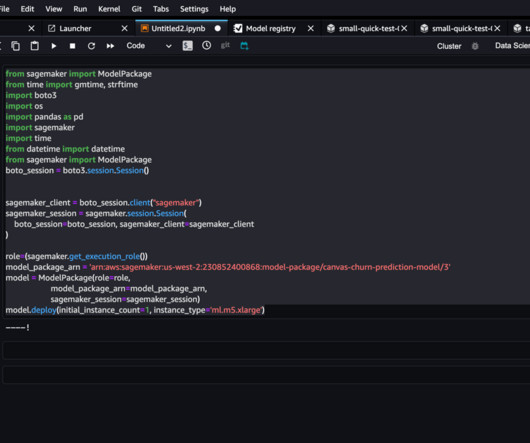
You can now register machine learning (ML) models built in Amazon SageMaker Canvas with a single click to the Amazon SageMaker Model Registry , enabling you to operationalize ML models in production. By keeping track of model versions, you can easily revert to a previous version if a new version causes issues.
Access to high-quality data can help organizations start successful products, defend against digital attacks, understand failures and pivot toward success. Emerging technologies and trends, such as machine learning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good data quality.
An enterprise data catalog does all that a library inventory system does – namely streamlining data discovery and access across data sources – and a lot more. For example, data catalogs have evolved to deliver governance capabilities like managing data quality and data privacy and compliance.
Amazon DataZone makes it straightforward for engineers, datascientists, product managers, analysts, and business users to access data throughout an organization so they can discover, use, and collaborate to derive data-driven insights.
This post explores how Amazon SageMaker AI with MLflow can help you as a developer and a machine learning (ML) practitioner efficiently experiment, evaluate generative AI agent performance, and optimize their applications for production readiness.
In addition, the Amazon Bedrock Knowledge Bases team worked closely with us to address several critical elements, including expanding embedding limits, managing the metadata limit (250 characters), testing different chunking methods, and syncing throughput to the knowledge base.
In this comprehensive guide, we’ll explore the key concepts, challenges, and best practices for ML model packaging, including the different types of packaging formats, techniques, and frameworks. These teams may include but are not limited to datascientists, software developers, machine learning engineers, and DevOps engineers.
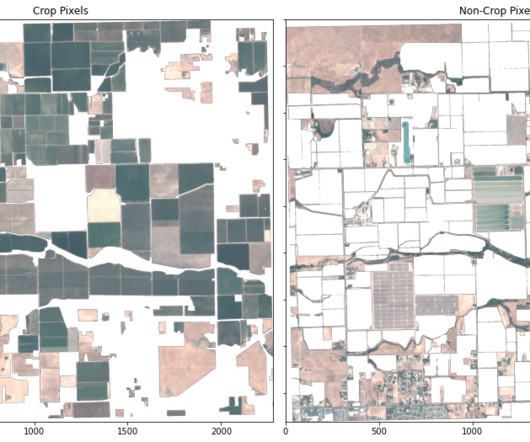
This guest post is co-written by Lydia Lihui Zhang, Business Development Specialist, and Mansi Shah, Software Engineer/DataScientist, at Planet Labs. In this post, we illustrate how to use a segmentation machine learning (ML) model to identify crop and non-crop regions in an image.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, data lakes, and analytics tools to load, transform, clean, and aggregate data.
Traditionally, developing appropriate data science code and interpreting the results to solve a use-case is manually done by datascientists. Datascientists still need to review and evaluate these results. Ultimately, users benefit from a transparent, and clear explanation of what ML predictions means to them.
It involves breaking down the document into its constituent parts, such as text, tables, images, and metadata, and identifying the relationships between these elements. Metadata customization for.csv files Knowledge Bases for Amazon Bedrock now offers an enhanced.csv file processing feature that separates content and metadata.
In this post, we discuss how the IEO developed UNDP’s artificial intelligence and machine learning (ML) platform—named Artificial Intelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
Artificial intelligence (AI) and machine learning (ML) are becoming an integral part of systems and processes, enabling decisions in real time, thereby driving top and bottom-line improvements across organizations. However, putting an ML model into production at scale is challenging and requires a set of best practices.
We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. In Part 2 , we demonstrated how to use Amazon Neptune ML (in Amazon SageMaker ) to train the KG and create KG embeddings. The KG files were stored in Amazon Simple Storage Service (Amazon S3) and then loaded in Amazon Neptune.
MLOps , or Machine Learning Operations, is a multidisciplinary field that combines the principles of ML, software engineering, and DevOps practices to streamline the deployment, monitoring, and maintenance of ML models in production environments. What is MLOps?
aws sagemaker create-cluster --cli-input-json file://cluster-config.json --region $AWS_REGION You should be able to see your cluster by navigating to SageMaker Hyperpod in the AWS Management Console and see a cluster named ml-cluster listed. After a few minutes, its status should change from Creating to InService. using the following code.
When working on real-world machine learning (ML) use cases, finding the best algorithm/model is not the end of your responsibilities. These practices are needed for a number of reasons: Backup: A trained model can be saved as a backup in case the original data is damaged or destroyed. model.save()) for saving the models.
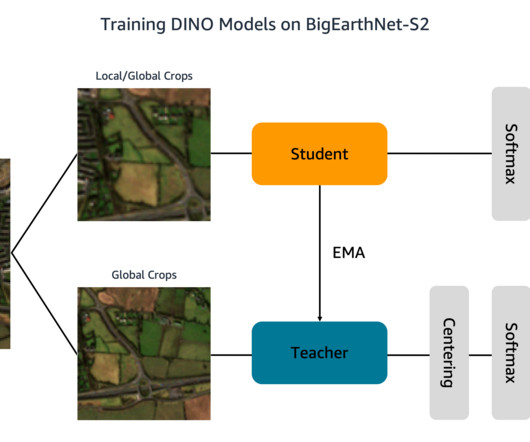
Training machine learning (ML) models to interpret this data, however, is bottlenecked by costly and time-consuming human annotation efforts. Additionally, each folder contains a JSON file with the image metadata. A detailed description of the data is provided in the BigEarthNet Guide. tif" --include "_B03.tif"
And eCommerce companies have a ton of use cases where ML can help. The problem is, with more ML models and systems in production, you need to set up more infrastructure to reliably manage everything. And because of that, many companies decide to centralize this effort in an internal ML platform. But how to build it?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content