This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
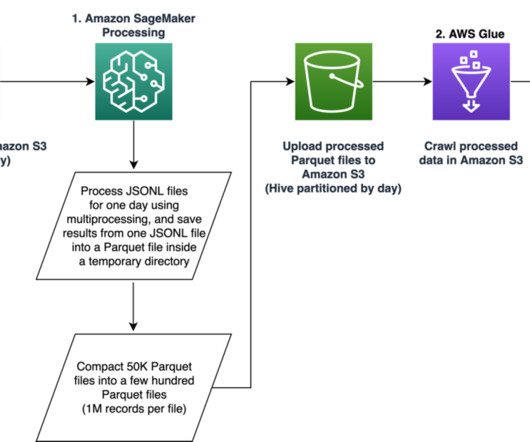
Our pipeline belongs to the general ETL (extract, transform, and load) process family that combines data from multiple sources into a large, central repository. This post shows how we used SageMaker to build a large-scale data processing pipeline for preparing features for the job recommendation engine at Talent.com.
This also led to a backlog of data that needed to be ingested. Steep learning curve for datascientists: Many of Rockets datascientists did not have experience with Spark, which had a more nuanced programming model compared to other popular ML solutions like scikit-learn.
Often the Data Team, comprising Data and MLEngineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier. What is an ETLdata pipeline in ML?
Working as a DataScientist — Expectation versus Reality! 11 key differences in 2023 Photo by Jan Tinneberg on Unsplash Working in Data Science and Machine Learning (ML) professions can be a lot different from the expectation of it. You could be working entirely on data analytics under a DataScientist job title.
In addition to the challenge of defining the features for the ML model, it’s critical to automate the feature generation process so that we can get ML features from the raw data for ML inference and model retraining. Because most of the games share similar log types, they want to reuse this ML solution to other games.
This situation is not different in the ML world. DataScientists and MLEngineers typically write lots and lots of code. Building a mental model for ETL components Learn the art of constructing a mental representation of the components within an ETL process.
Specialist DataEngineering at Merck, and Prabakaran Mathaiyan, Sr. MLEngineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of software development. This post is co-written with Jayadeep Pabbisetty, Sr.
To obtain such insights, the incoming raw data goes through an extract, transform, and load (ETL) process to identify activities or engagements from the continuous stream of device location pings. We can analyze activities by identifying stops made by the user or mobile device by clustering pings using ML models in Amazon SageMaker.
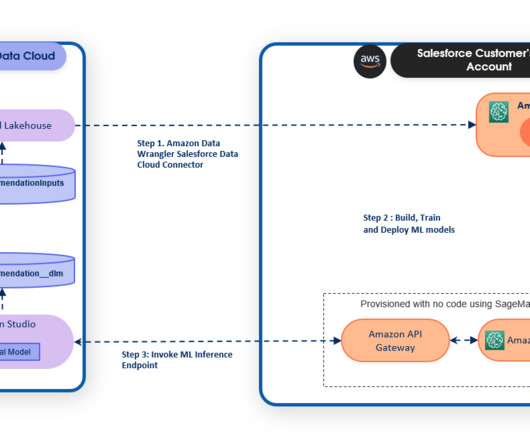
Introducing Einstein Studio on Data Cloud Data Cloud is a data platform that provides businesses with real-time updates of their customer data from any touch point. With Einstein Studio, a gateway to AI tools on the data platform, admins and datascientists can effortlessly create models with a few clicks or using code.
We can then examine how the integrated SageMaker AI/ML offerings helped solve those challenges. Collaboration – Datascientists each worked on their own local Jupyter notebooks to create and train ML models. They lacked an effective method for sharing and collaborating with other datascientists.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Dataengineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
Collaboration : Ensuring that all teams involved in the project, including datascientists, engineers, and operations teams, are working together effectively. Costs: Oftentimes, cost is the most important aspect of any ML model deployment. One DataEngineer: Cloud database integration with our cloud expert.
You have to make sure that your ETLs are locked down. And usually what ends up happening is that some poor datascientist or MLengineer has to manually troubleshoot this in a Jupyter Notebook. So this path on the right side of the production icon is what we’re calling ML observability.
You have to make sure that your ETLs are locked down. And usually what ends up happening is that some poor datascientist or MLengineer has to manually troubleshoot this in a Jupyter Notebook. So this path on the right side of the production icon is what we’re calling ML observability.
Nevertheless, many datascientists will agree that they can be really valuable – if used well. And that’s what we’re going to focus on in this article, which is the second in my series on Software Patterns for Data Science & MLEngineering. Data on its own is not sufficient for a cohesive story.
You have to make sure that your ETLs are locked down. And usually what ends up happening is that some poor datascientist or MLengineer has to manually troubleshoot this in a Jupyter Notebook. So this path on the right side of the production icon is what we’re calling ML observability.
This is Piotr Niedźwiedź and Aurimas Griciūnas from neptune.ai , and you’re listening to ML Platform Podcast. Stefan is a software engineer, datascientist, and has been doing work as an MLengineer. To a junior datascientist, it doesn’t matter if you’re using Airflow, Prefect , Dexter.
This brings interpersonal challenges, and the AI/ML teams are encouraged to build good relationships with clients to help support the models by telling people how to use the solution instead of just exposing the endpoint without documentation or telling them how. For them, it works surprisingly well, considering how low the complexity is. “We
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content