This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
But trust isn’t important only for executives; before executive trust can be established, datascientists and citizen datascientists who create and work with ML models must have faith in the data they’re using. This can lead to more accurate predictions and better decision-making.
This involves unifying and sharing a single copy of data and metadata across IBM® watsonx.data ™, IBM® Db2 ®, IBM® Db2® Warehouse and IBM® Netezza ®, using native integrations and supporting open formats, all without the need for migration or recataloging.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. Later this year, it will leverage watsonx.ai
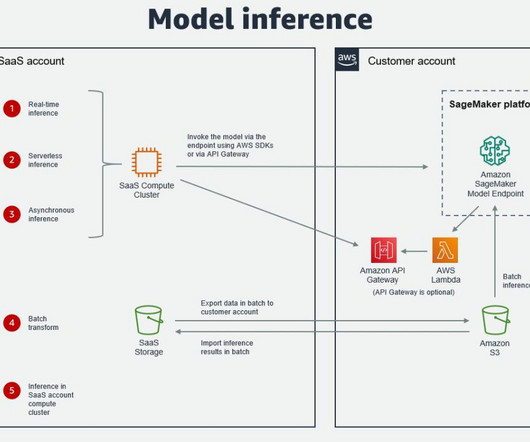
In addition to the challenge of defining the features for the ML model, it’s critical to automate the feature generation process so that we can get ML features from the raw data for ML inference and model retraining. The ETL pipeline, MLOps pipeline, and ML inference should be rebuilt in a different AWS account.
As a result, it’s easier to find problems with data quality, inconsistencies, and outliers in the dataset. Metadata analysis is the first step in establishing the association, and subsequent steps involve refining the relationships between individual database variables.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, data lakes, and analytics tools to load, transform, clean, and aggregate data. Big Data Architect. Zach Mitchell is a Sr.
This is part of the Full Stack DataScientist blog series. Building end-to-end data science solutions means developing data collection, feature engineering, model building and model serving processes. It’s overwhelming at first, so let’s just focus on the main part development as the ‘Data Engineer’ — DAGS.
Many organizations choose SageMaker as their ML platform because it provides a common set of tools for developers and datascientists. Alternatively, a service such as AWS Glue or a third-party extract, transform, and load (ETL) tool can be used for data transfer.
An ML model registered by a datascientist needs an approver to review and approve before it is used for an inference pipeline and in the next environment level (test, UAT, or production). When datascientists develop a model, they register it to the SageMaker Model Registry with the model status of PendingManualApproval.
In contrast, data warehouses and relational databases adhere to the ‘Schema-on-Write’ model, where data must be structured and conform to predefined schemas before being loaded into the database. Schema Enforcement: Data warehouses use a “schema-on-write” approach.
Prerequisites To implement this solution, you need the following: Historical and real-time user click data for the interactions dataset Historical and real-time news article metadata for the items dataset Ingest and prepare the data To train a model in Amazon Personalize, you need to provide training data. Happy building!
The examples focus on questions on chunk-wise business knowledge while ignoring irrelevant metadata that might be contained in a chunk. About the authors Samantha Stuart is a DataScientist with AWS Professional Services, and has delivered for customers across generative AI, MLOps, and ETL engagements.
Set specific, measurable targets Data science goals to “increase sales” lack the clarity needed to evaluate success and secure ongoing funding. Audit existing data assets Inventory internal datasets, ETL capabilities, past analytical initiatives, and available skill sets. Complexity limits accessibility and value creation.
Unlike traditional databases, Data Lakes enable storage without the need for a predefined schema, making them highly flexible. Importance of Data Lakes Data Lakes play a pivotal role in modern data analytics, providing a platform for DataScientists and analysts to extract valuable insights from diverse data sources.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
Collaboration : Ensuring that all teams involved in the project, including datascientists, engineers, and operations teams, are working together effectively. In the case of our CI/CD-MLOPs system, we stored the model versions and metadata in the data storage services offered by AWS i.e S3 buckets.
These work together to enable efficient data processing and analysis: · Hive Metastore It is a central repository that stores metadata about Hive’s tables, partitions, and schemas. Thus, making it easier for analysts and datascientists to leverage their SQL skills for Big Data analysis.
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. In the process of working on their ML tasks, datascientists typically start their workflow by discovering relevant data sources and connecting to them.
When it comes to data complexity, it is for sure that in machine learning, we are dealing with much more complex data. First of all, machine learning engineers and datascientists often use data from different data vendors. Some data sets are being corrected by data entry specialists and manual inspectors.
If you want to get datascientists, engineers, architects, stakeholders, third-party consultants, and a whole myriad of other actors on board, you have to build two things: 1 Bridges between stakeholders and members from all over an organization—from marketing to sales to engineering—working with data on different theoretical and practical levels.
Stefan is a software engineer, datascientist, and has been doing work as an ML engineer. He also ran the data platform in his previous company and is also co-creator of open-source framework, Hamilton. To a junior datascientist, it doesn’t matter if you’re using Airflow, Prefect , Dexter.
So, a better database architecture would be to maintain multiple tables where one of the tables maintains the past 3 months history with session-level details, whereas other tables may contain weekly aggregated click, ATC, and order data. Keeping track of which data was used to run an experiment sometimes becomes painful for a DataScientist.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of data pipelines, including the two major types of existing data pipelines. You also learned how to build an Extract Transform Load (ETL) pipeline and discovered the automation capabilities of Apache Airflow for ETL pipelines.
quality attributes) and metadata enrichment (e.g., Brainly’s journey toward MLOps Since the early days of ML at Brainly, infrastructure, and engineering teams have encouraged datascientists and machine learning engineers working on projects to use best practices for structuring their projects and code bases.
Spark offered a more versatile programming model, supporting not only MapReduce-like batch processing but also real-time stream processing and interactive data queries. Its ability to efficiently handle iterative algorithms and machine learning tasks made it a popular choice for datascientists and engineers. Morgan Kaufmann.
He highlights innovations in data, infrastructure, and artificial intelligence and machine learning that are helping AWS customers achieve their goals faster, mine untapped potential, and create a better future. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
When done well, data democratization empowers employees with tools that let everyone work with data, not just the datascientists. When workers get their hands on the right data, it not only gives them what they need to solve problems, but also prompts them to ask, “What else can I do with data?
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content