This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
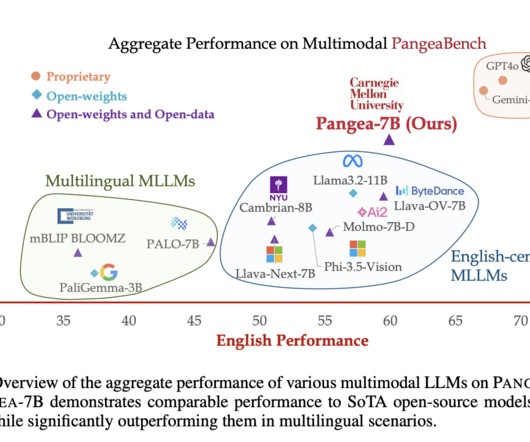
Despite recent advances in multimodal largelanguagemodels (MLLMs), the development of these models has largely centered around English and Western-centric datasets. Moreover, PANGEA matches or even outperforms proprietary models like Gemini-1.5-Pro Don’t Forget to join our 50k+ ML SubReddit.
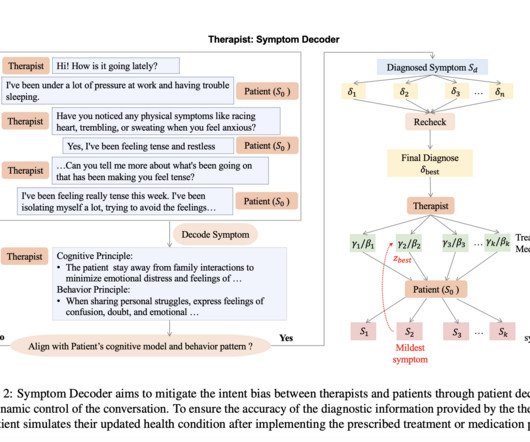
These models are trained on data collected from social media, which introduces bias and may not accurately represent diverse patient experiences. Moreover, privacy concerns and datascarcity hinder the development of robust models for mental health diagnosis and treatment.
The model’s performance is evaluated using three distinct accuracy metrics: token-level accuracy for individual token assessment, sentence-level accuracy for evaluating coherent text segments, and response-level accuracy for overall output evaluation. If you like our work, you will love our newsletter.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








Let's personalize your content