This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As emerging DevOps trends redefine softwaredevelopment, companies leverage advanced capabilities to speed up their AI adoption. When unstructured data surfaces during AI development, the DevOps process plays a crucial role in data cleansing, ultimately enhancing the overall model quality.
.” Recognising the critical concern of ethical AI development, Ros stressed the significance of human oversight throughout the entire process. Softserve’s findings suggest that GenAI can accelerate programming productivity by as much as 40 percent.
Summary: Dataquality is a fundamental aspect of Machine Learning. Poor-qualitydata leads to biased and unreliable models, while high-qualitydata enables accurate predictions and insights. What is DataQuality in Machine Learning? Bias in data can result in unfair and discriminatory outcomes.
Deep learning is a branch of machine learning that makes use of neural networks with numerous layers to discover intricate data patterns. Deep learning models use artificial neural networks to learn from data. Online Learning : Incremental training of the model on new data as it arrives.
But it means that companies must overcome the challenges experienced so far in GenAII projects, including: Poor dataquality: GenAI ends up only being as good as the data it uses, and many companies still dont trust their data. But copilots are expected to have a bigger impact when used outside of IT.
Amidst Artificial Intelligence (AI) developments, the domain of softwaredevelopment is undergoing a significant transformation. Traditionally, developers have relied on platforms like Stack Overflow to find solutions to coding challenges.
The result will be greater innovation and new benchmarks for speed and quality in softwaredevelopment. Processes will become more efficient, and collaboration between development and QA teams will improve. AI-powered QA is also becoming central to DevOps.
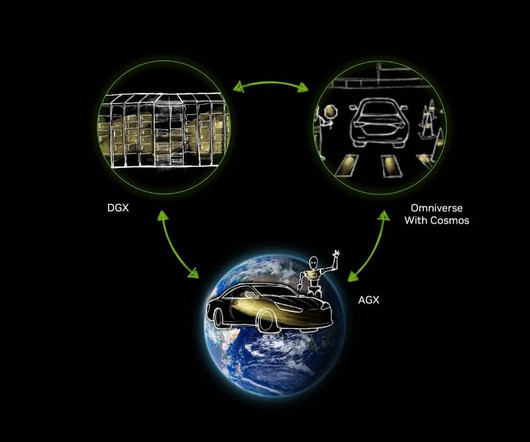
With Cosmos added to the three-computer solution, developers gain a data flywheel that can turn thousands of human-driven miles into billions of virtually driven miles amplifying training dataquality.
“This is across all industries and disciplines, from transforming HR processes and marketing transformations through branded content to contact centers or softwaredevelopment.” These include so-called small language models and non-generative models, such as forecasting models , which require a narrower data set.
This framework creates a central hub for feature management and governance with enterprise feature store capabilities, making it straightforward to observe the data lineage for each feature pipeline, monitor dataquality , and reuse features across multiple models and teams.
Michael Dziedzic on Unsplash I am often asked by prospective clients to explain the artificial intelligence (AI) software process, and I have recently been asked by managers with extensive softwaredevelopment and data science experience who wanted to implement MLOps.
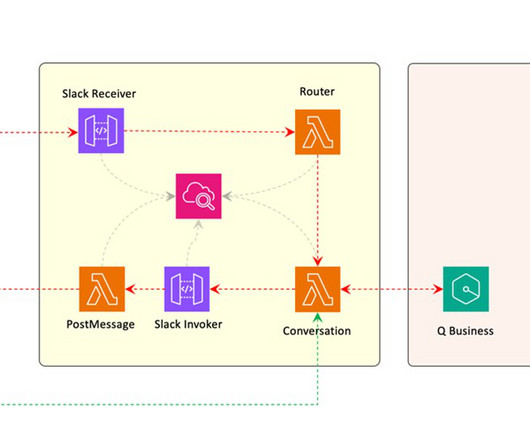
In our case, where we have several applications built in-house, as well as third-party software backed by Amazon S3, we make heavy use of Amazon Q connector for Amazon S3, and as well as custom connectors weve written. SoftwareDevelopment Manager based in Seattle with over a decade of experience at AWS. Jonathan Garcia is a Sr.
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines. He specializes in designing, building, and optimizing large-scale data solutions.
This integration reduced development and future management costs by approximately 50% while improving the expressiveness of the avatars, according to AiHUB. The unsung stars here are softwaredevelopment kits — those bundles of tools, libraries and documentation that cut the guesswork out of innovation.
The bulk of Persistent Systems business comes from building software for enterprises, how has the advent of generative AI transformed how your team operates? The advent of generative AI (GenAI) has transformed how our team operates at Persistent, particularly in enterprise softwaredevelopment.
Model governance involves overseeing the development, deployment, and maintenance of ML models to help ensure that they meet business objectives and are accurate, fair, and compliant with regulations. It also helps achieve data, project, and team isolation while supporting softwaredevelopment lifecycle best practices.
Recognizing this challenge as an opportunity for innovation, F1 partnered with Amazon Web Services (AWS) to develop an AI-driven solution using Amazon Bedrock to streamline issue resolution. Creating ETL pipelines to transform log data Preparing your data to provide quality results is the first step in an AI project.
Next, the SageMaker Ground Truth Plus team sets up data labeling workflows, which changes the batch status to In progress. Annotators label the data, and you complete your dataquality check by accepting or rejecting the labeled data. Rejected objects go back to annotators to re-label.
The DataQuality Check part of the pipeline creates baseline statistics for the monitoring task in the inference pipeline. Within this pipeline, SageMaker on-demand DataQuality Monitor steps are incorporated to detect any drift when compared to the input data.
Data aggregation such as from hourly to daily or from daily to weekly time steps may also be required. Perform dataquality checks and develop procedures for handling issues. Typical dataquality checks and corrections include: Missing data or incomplete records Inconsistent data formatting (e.g.,
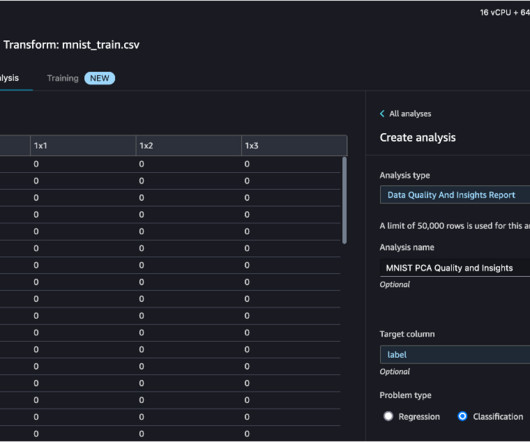
In this section, we demonstrate how to perform feature engineering on the data from Snowflake using SageMaker Data Wrangler’s built-in capabilities. You can use the report to help you clean and process your data. For Analysis type , choose DataQuality and Insights Report. Choose Create.
The AWS managed offering ( SageMaker Ground Truth Plus ) designs and customizes an end-to-end workflow and provides a skilled AWS managed team that is trained on specific tasks and meets your dataquality, security, and compliance requirements. Hasan helps design, deploy and scale Generative AI and Machine learning applications on AWS.
After confirming that the dataquality is acceptable, we go back to the data flow and use Data Wrangler’s DataQuality and Insights Report. Refer to Get Insights On Data and DataQuality for more information. Choose the plus sign next to Data types , then choose Add analysis.
RAG implementations involve combining LLMs with external data sources to enhance their knowledge and decision-making capabilities. This integration increases the complexity of AI systems, requiring robust governance frameworks to manage dataquality, model performance, and compliance.
It’s been fascinating to see the shifting role of the data scientist and the software engineer in these last twenty years since machine learning became widespread. Having worn both hats, I am very aware of the importance of the softwaredevelopment lifecycle (especially automation and testing) as applied to machine learning projects.
Few nonusers (2%) report that lack of data or dataquality is an issue, and only 1.3% AI users are definitely facing these problems: 7% report that dataquality has hindered further adoption, and 4% cite the difficulty of training a model on their data.
This is the common belief that if you just build cool software, people will line up to buy it. This never works, and the solution is a robust marketing process connected with your softwaredevelopment process. What role do large language models (LLMs) play in Tamr’s dataquality and enrichment processes?
In particular, you’ll focus on tabular (or structured) synthetic data and the privacy-preserving benefits of working with synthetic data. You’ll even get hands-on with the open-source tool (DataLLM) and create tabular synthetic data yourselves. Gen AI in SoftwareDevelopment. What should you be looking for?
Therefore, when the Principal team started tackling this project, they knew that ensuring the highest standard of data security such as regulatory compliance, data privacy, and dataquality would be a non-negotiable, key requirement. He has 20 years of enterprise softwaredevelopment experience.
As machine learning (ML) models have improved, data scientists, ML engineers and researchers have shifted more of their attention to defining and bettering dataquality. This has led to the emergence of a data-centric approach to ML and various techniques to improve model performance by focusing on data requirements.
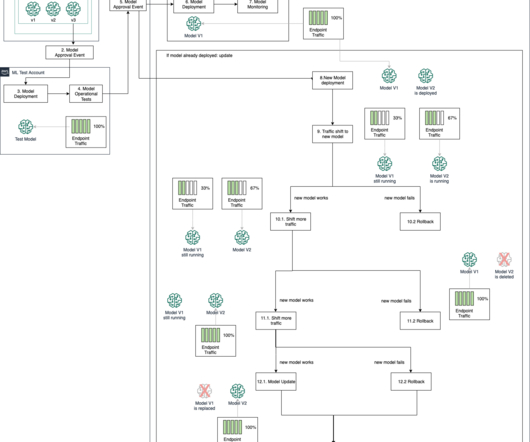
With this option, you are testing the new model and minimizing the risks of a low-performing model, and you can compare both models’ performance with the same data. SageMaker deployment guardrails Guardrails are an essential part of softwaredevelopment. She is also the Co-Director of Women In Big Data (WiBD), Denver chapter.
Outerbounds’ platform is valuable for businesses that want to improve their dataquality and identify potential problems early on. Active learning is a type of machine learning that involves iteratively querying a human for labels for data points that are most informative for the model.
He has more than 25 years of experience with technology, including cloud solution development, machine learning, softwaredevelopment, and data center infrastructure. Indrajit is an AWS Enterprise Sr. Solutions Architect. In his role, he helps customers achieve their business outcomes through cloud adoption.
Data Management – Efficient data management is crucial for AI/ML platforms. Regulations in the healthcare industry call for especially rigorous data governance. It should include features like data versioning, data lineage, data governance, and dataquality assurance to ensure accurate and reliable results.
This is a platform that supports this new data-centric development loop. This is then used to train models, and those models then power feedback and analyses that guide how to improve the quality of your data and therefore of your models.
This is a platform that supports this new data-centric development loop. This is then used to train models, and those models then power feedback and analyses that guide how to improve the quality of your data and therefore of your models.
We started with data loading and preprocessing, fixing optimization issues to allow the model to process years of historical across all 8,000 stores. Several breakthroughs enabled us to fix dataquality issues within the dataset. The approach ultimate delivered a solution that satisfied all the stakeholders. team loves to do.
Automated Query Optimization: By understanding the underlying data schemas and query patterns, ChatGPT could automatically optimize queries for better performance, indexing recommendations, or distributed execution across multiple data sources. gradients of energies to compute forces).
Then you must specify, analyze, test, and manage them throughout the softwaredevelopment lifecycle. Creating user stories , analyzing them, and validating requirements are all parts of requirements development that deserve their own article. The front end is one of the clients for this layer. What talent is available to build?
It provides a detailed overview of each library’s unique contributions and explains how they can be combined to create a functional system that can detect and correct linguistic errors in text data. Training dataquality and bias: ML-based grammar checkers heavily rely on training data to learn patterns and make predictions.
For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, data governance becomes crucial. This includes dataquality, privacy, and compliance. Git is a distributed version control system for softwaredevelopment.
Once the data is loaded into the data warehouse, it can be queried by business analysts and data scientists to perform various analyses such as customer segmentation, product recommendations, and trend analysis.
This “write once, run anywhere” capability allows developers to create applications that are not tied to a specific operating system, increasing portability and flexibility. It supports the handling of large and complex data sets from different sources, including databases, spreadsheets, and external files.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content